Complete Observability from Hardware to Code
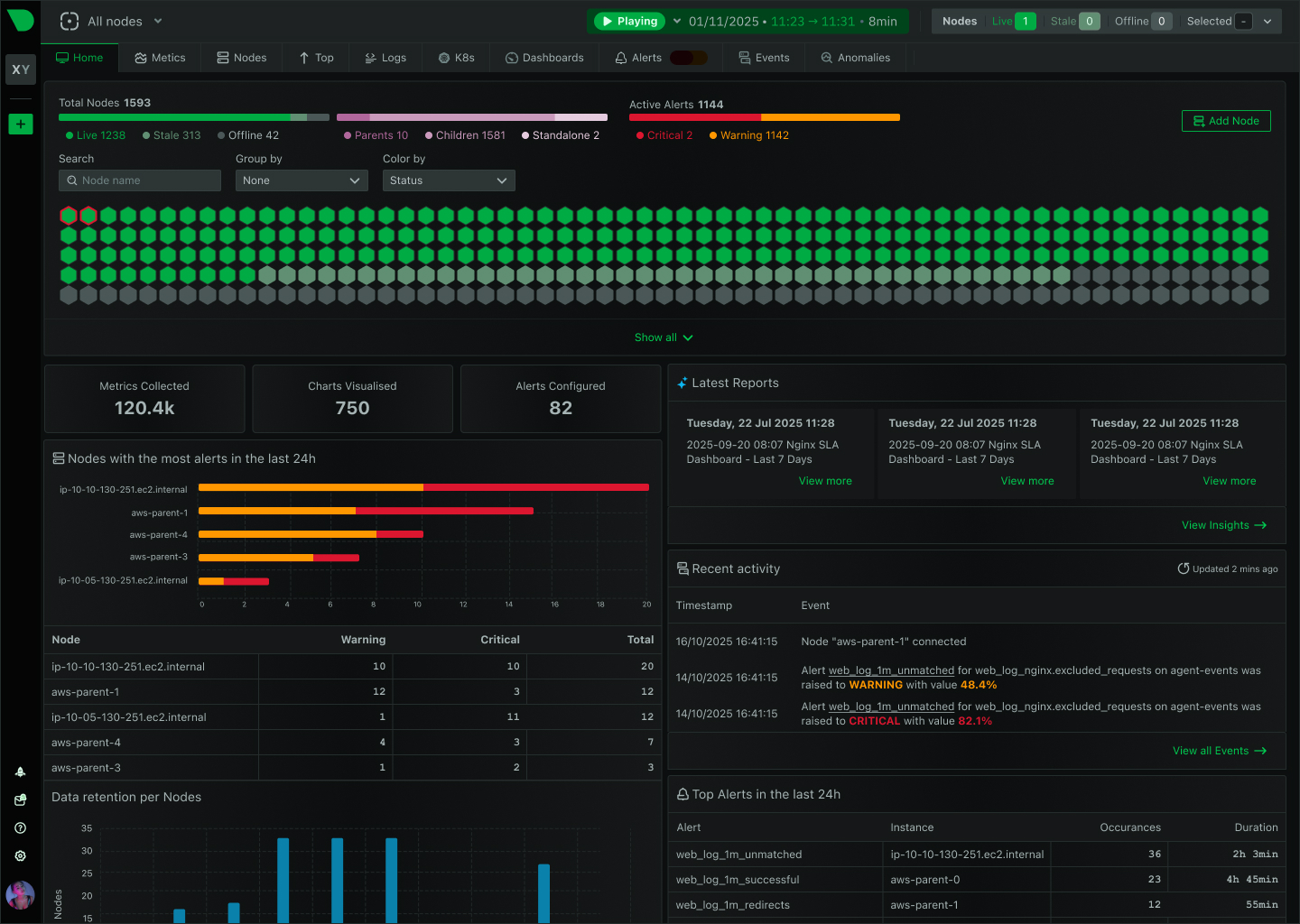
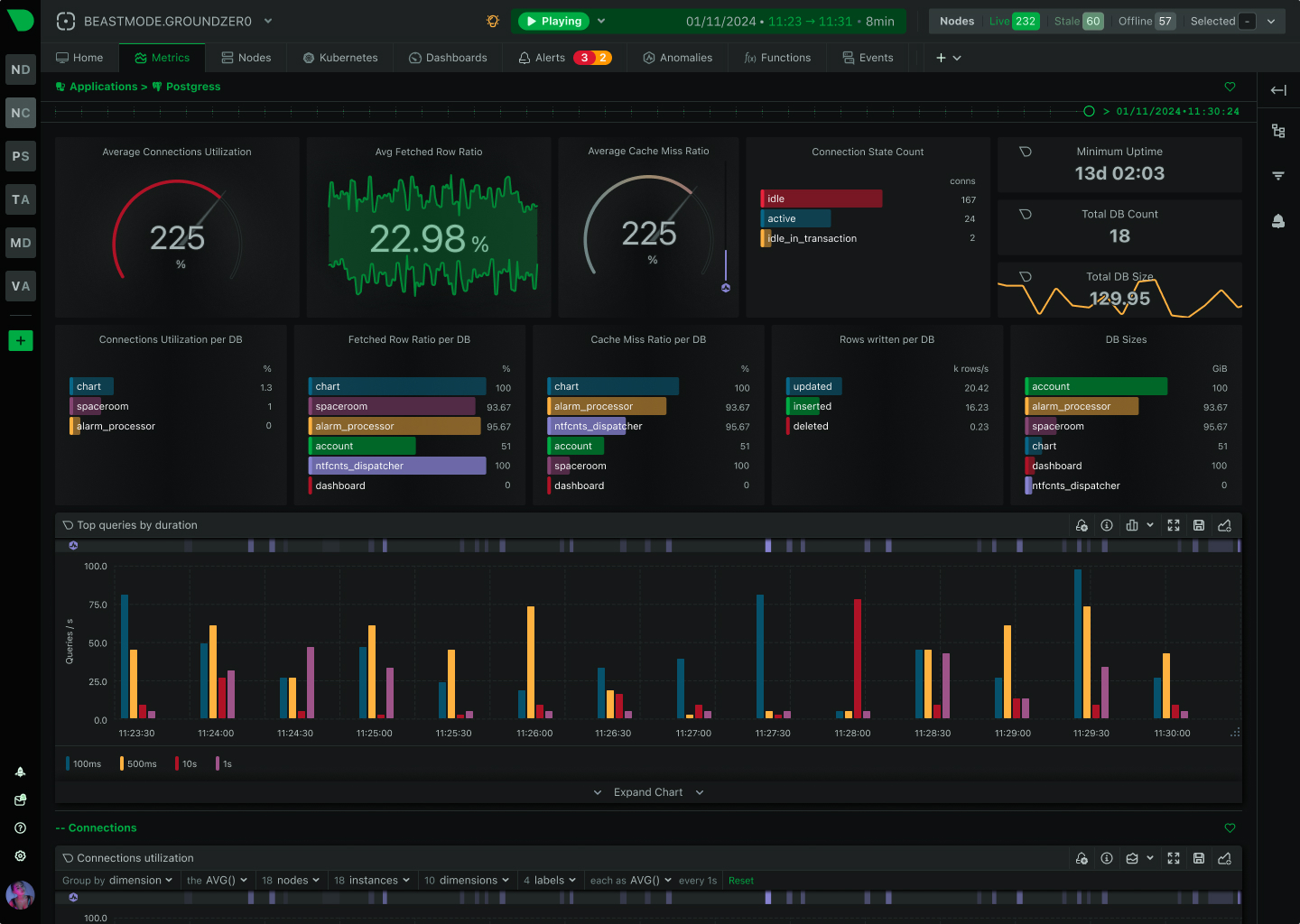
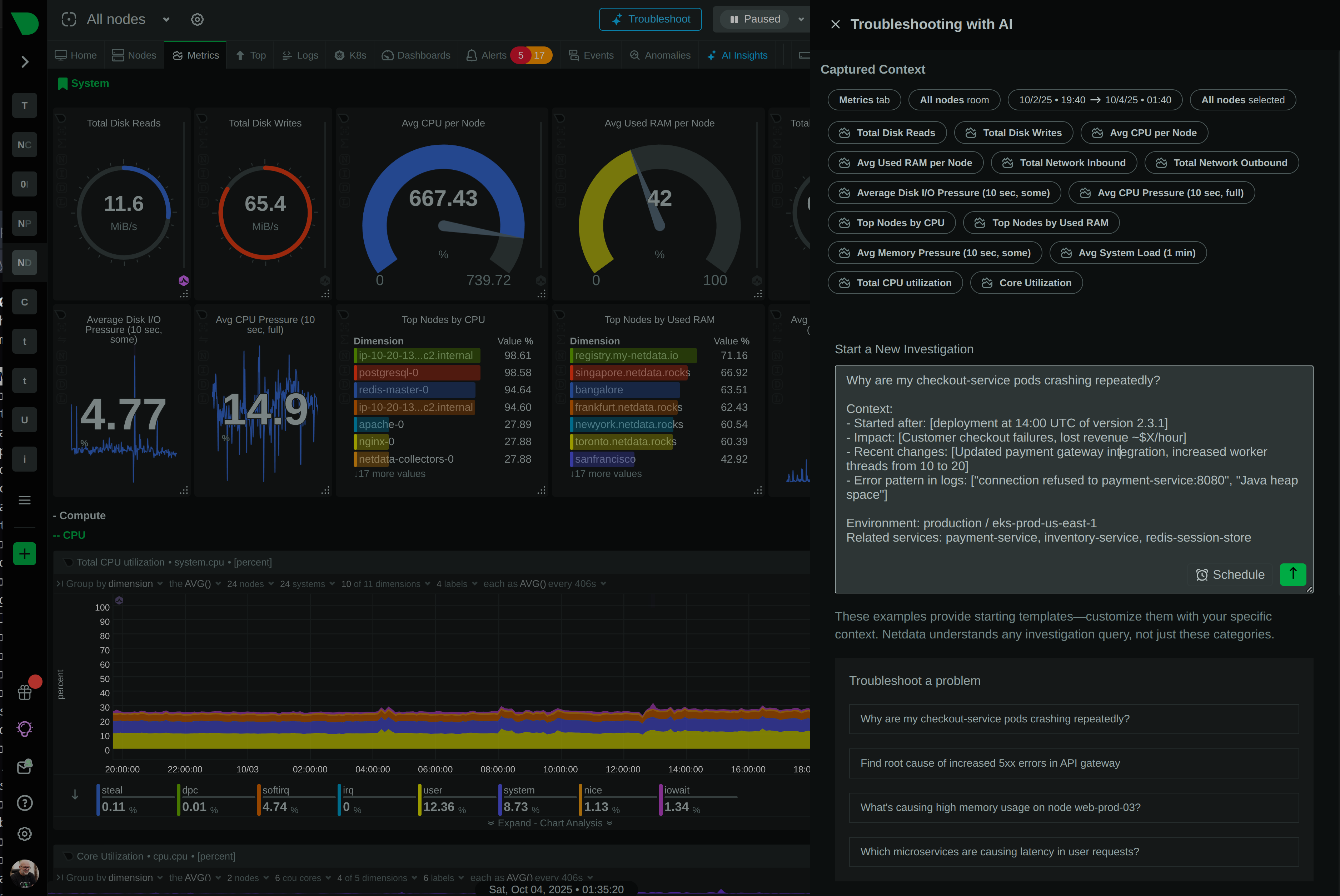
Netdata and Sentry are complementary tools that together provide complete visibility across your entire stack. Netdata monitors infrastructure health in real-time, while Sentry tracks application errors and performance. Discover how using both tools delivers faster incident resolution, lower costs, and comprehensive observability.