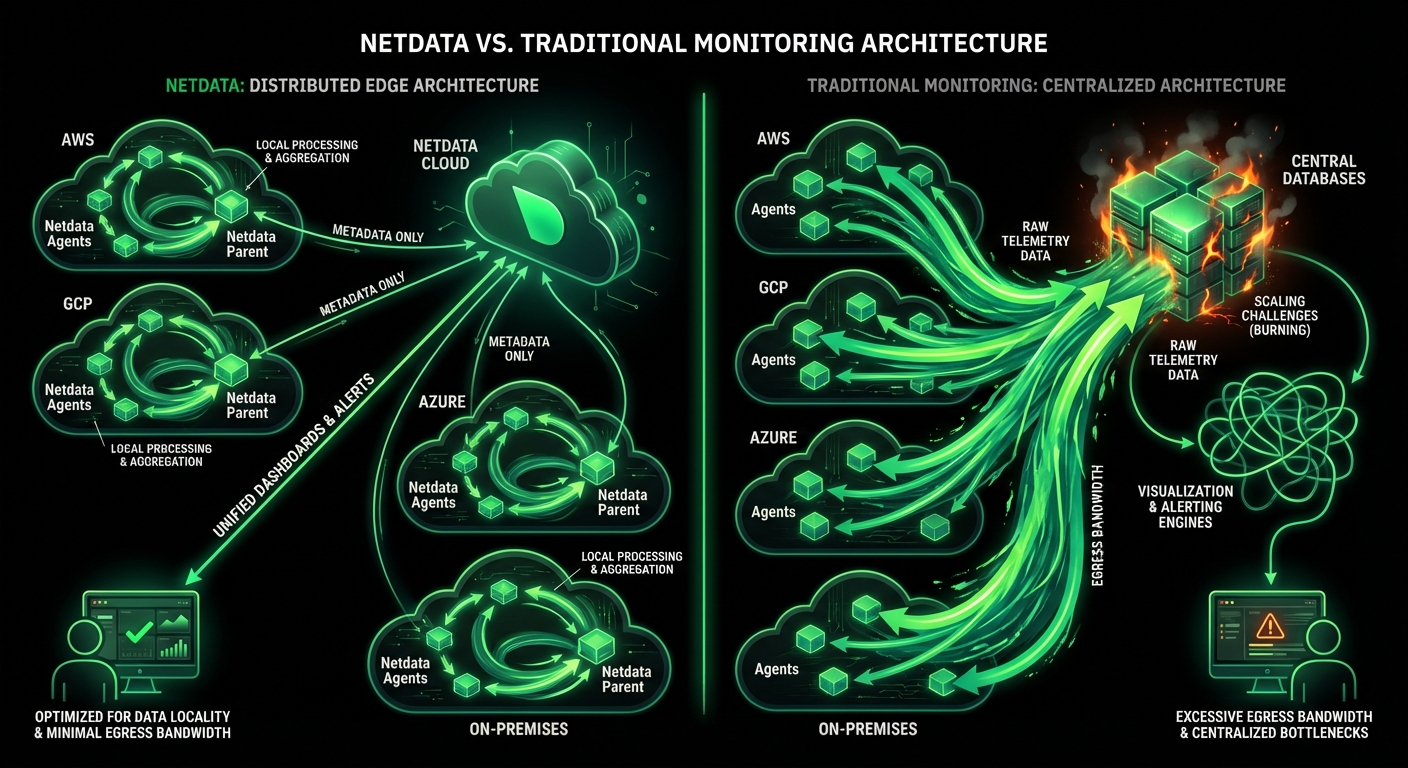
Transform Alerts Into Answers
UptimeRobot tells you when your service is down. Netdata tells you why it happened, what caused it, and how to prevent it. Move beyond symptom alerts to AI-powered root cause analysis with per-second precision.

UptimeRobot tells you when your service is down. Netdata tells you why it happened, what caused it, and how to prevent it. Move beyond symptom alerts to AI-powered root cause analysis with per-second precision.
Six capabilities that transform monitoring from reactive to proactive
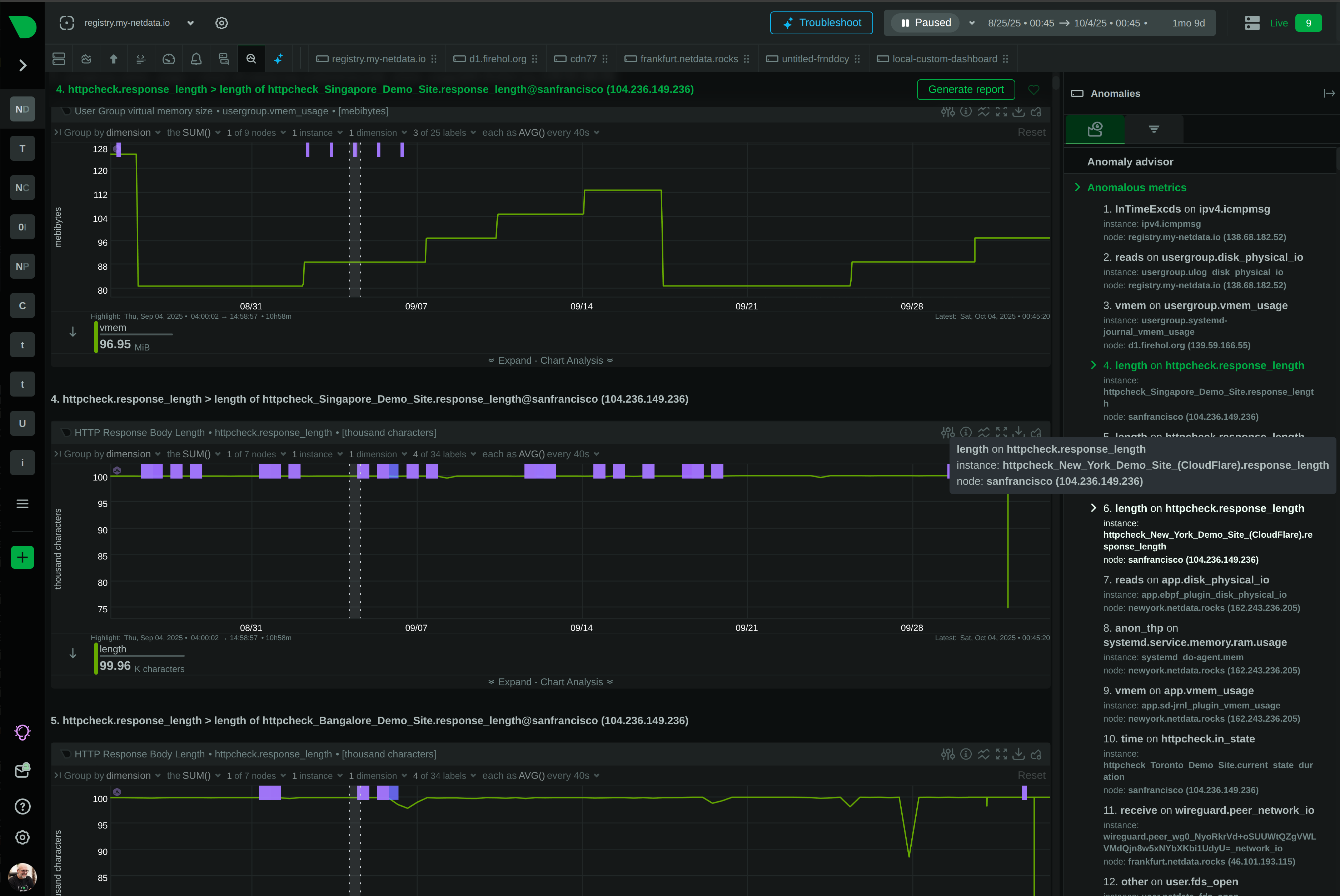
Anomaly Advisor correlates issues across 10,000+ metrics per node, surfacing root causes in the top 30-50 results - not just symptoms.
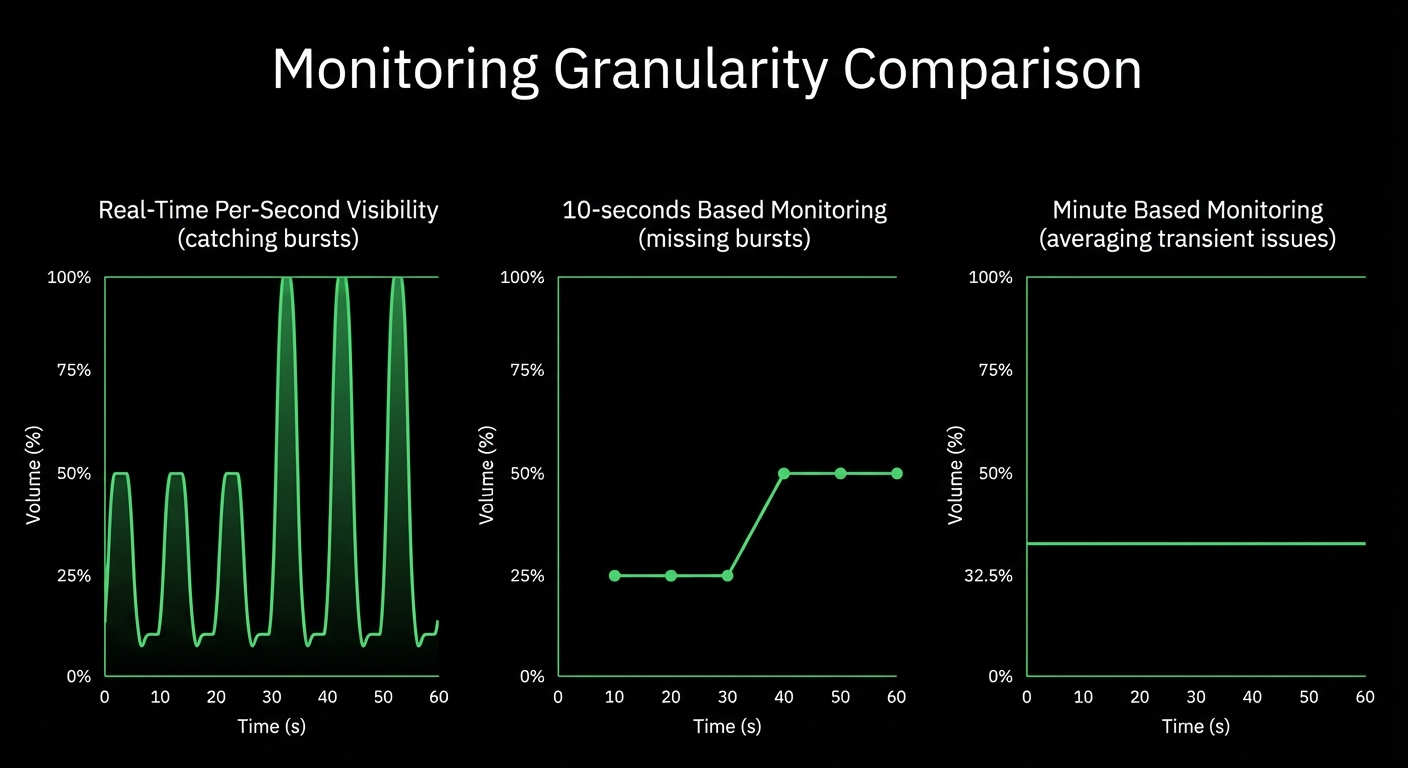
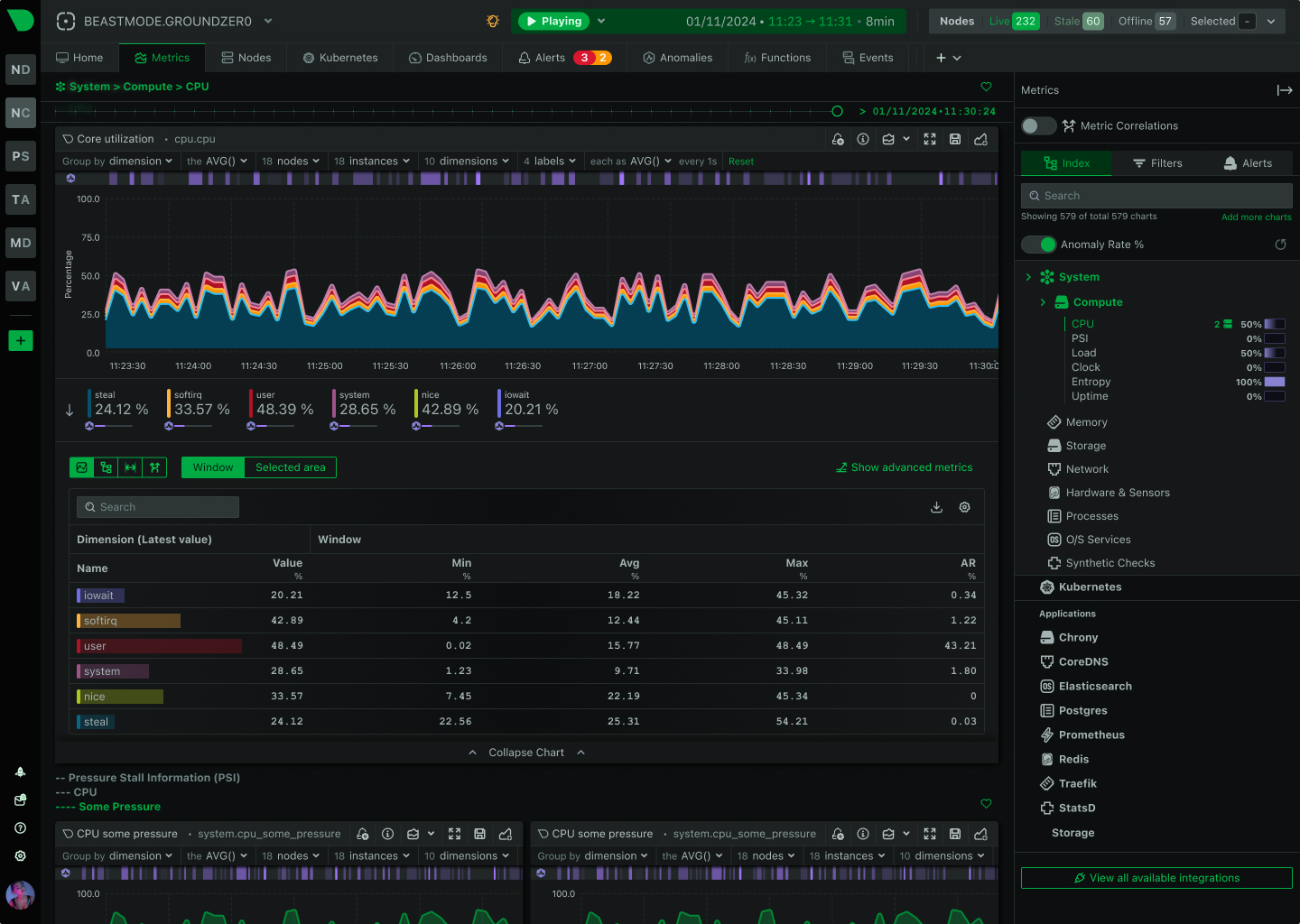
Per-second data collection with sub-2-second latency catches transient issues that 5-minute checks miss entirely.
18 ML models per metric achieve consensus-based detection with theoretical 10^-36 false positive rate for anomaly identification.
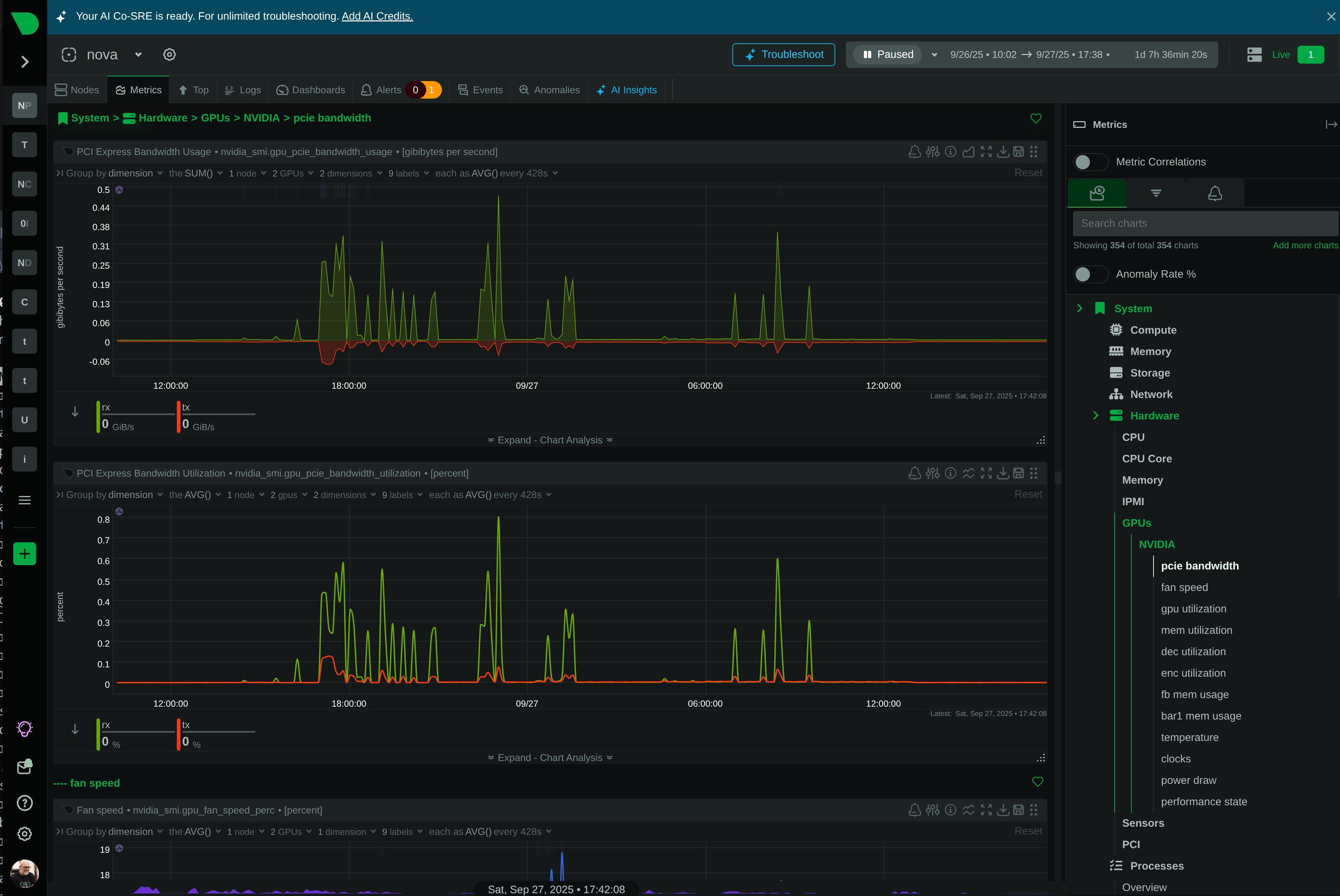
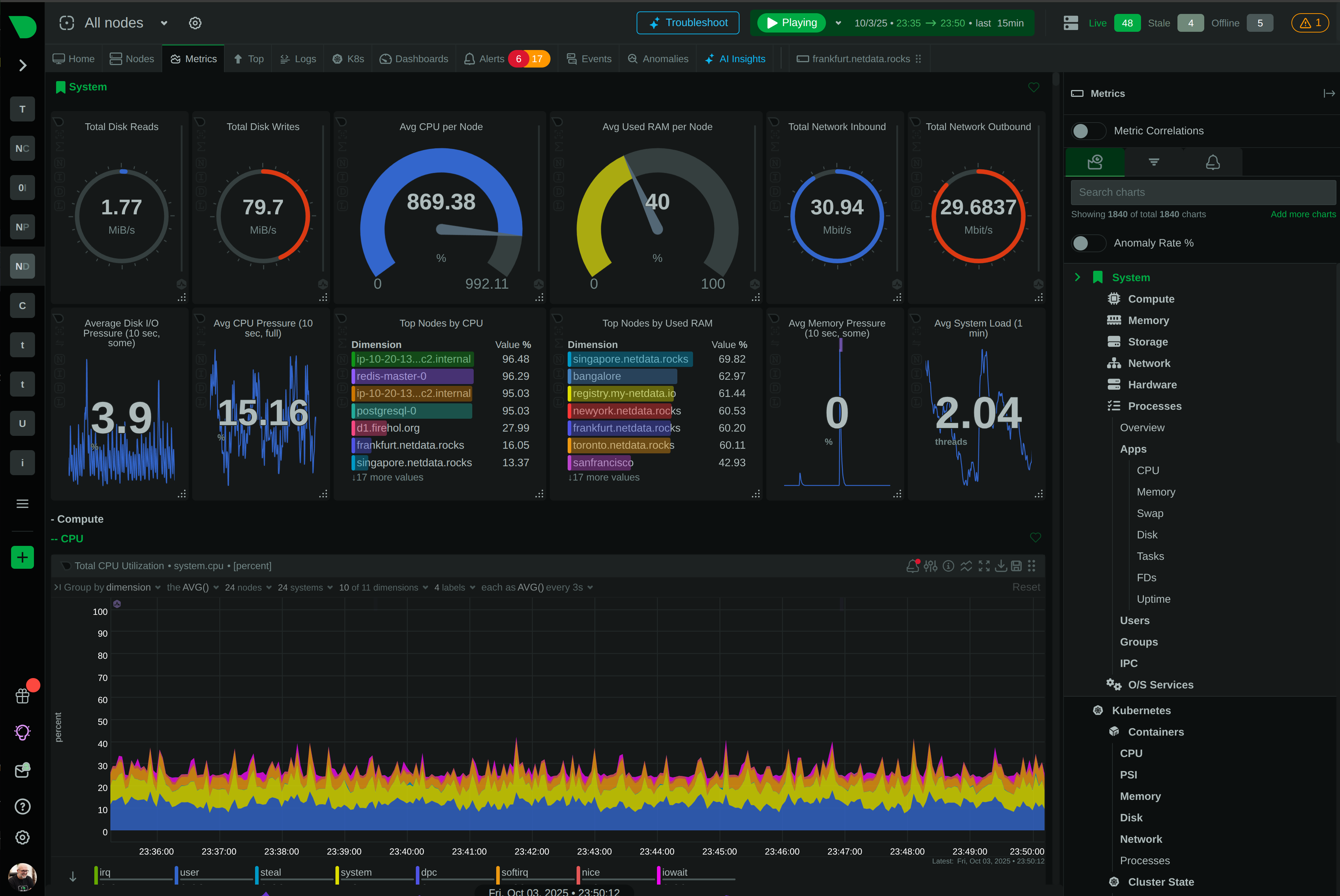
Monitor CPU, memory, disk, network, processes, containers, databases, and 800+ integrations - not just HTTP status codes.
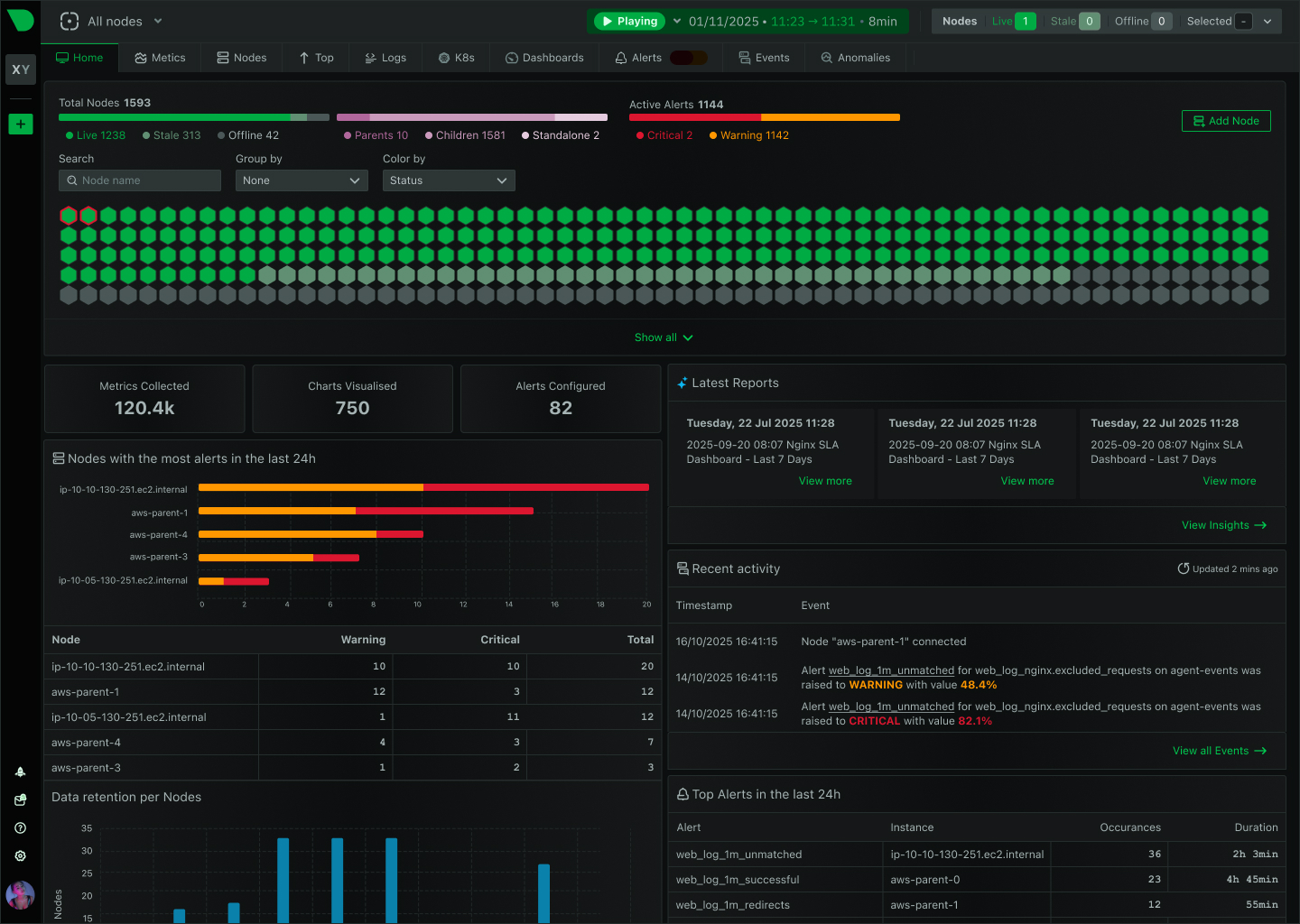
Auto-discovery finds all services instantly. Algorithmic dashboards generate automatically. ML trains on your data from day one.
Unlimited metrics per node with predictable pricing. No surprise bills from data volume spikes or feature restrictions.
Trusted by operations teams worldwide

Platform Comparison
Understanding the fundamental differences between external uptime monitoring and internal infrastructure observability
Capability
Netdata
UptimeRobot
Monitoring Type
✅ Internal Infrastructure
Agent-based deep observability
✅ External Synthetic
Agentless availability checks
Data Granularity
✅ Per-Second
1-second collection and visualization
⚠️ 30s-5min
Misses transient issues
Metrics Per Node
✅ 10,000-20,000
Complete system visibility
⚠️ 2-3
Status and response time only
ML Anomaly Detection
✅ Advanced
18 models per metric, high accuracy
❌ Not Available
Static thresholds only
Root Cause Analysis
✅ AI-Powered
Automated correlation and diagnosis
❌ Not Available
Symptom alerts only
Alert Approach
✅ Component-Level
400+ preconfigured intelligent alerts
⚠️ Basic
Static threshold checks
Infrastructure Monitoring
✅ Comprehensive
CPU, memory, disk, network, processes
❌ Not Available
External checks only
Logs Management
✅ Included
systemd-journal and Windows Event Logs
❌ Not Available
No log capabilities
Data Sovereignty
✅ On-Premises
All data stays on your infrastructure
⚠️ Cloud-Only
SaaS architecture
Pricing Model
✅ Per-Node
Predictable pricing, unlimited metrics
⚠️ Per-Monitor
Scales with check count
Open Source
✅ Yes
GPLv3+, 76,000+ GitHub stars
❌ No
Proprietary SaaS
Best For
✅ Infrastructure Teams
DevOps, SRE, operations centers
✅ External Monitoring
Public status pages, uptime checks
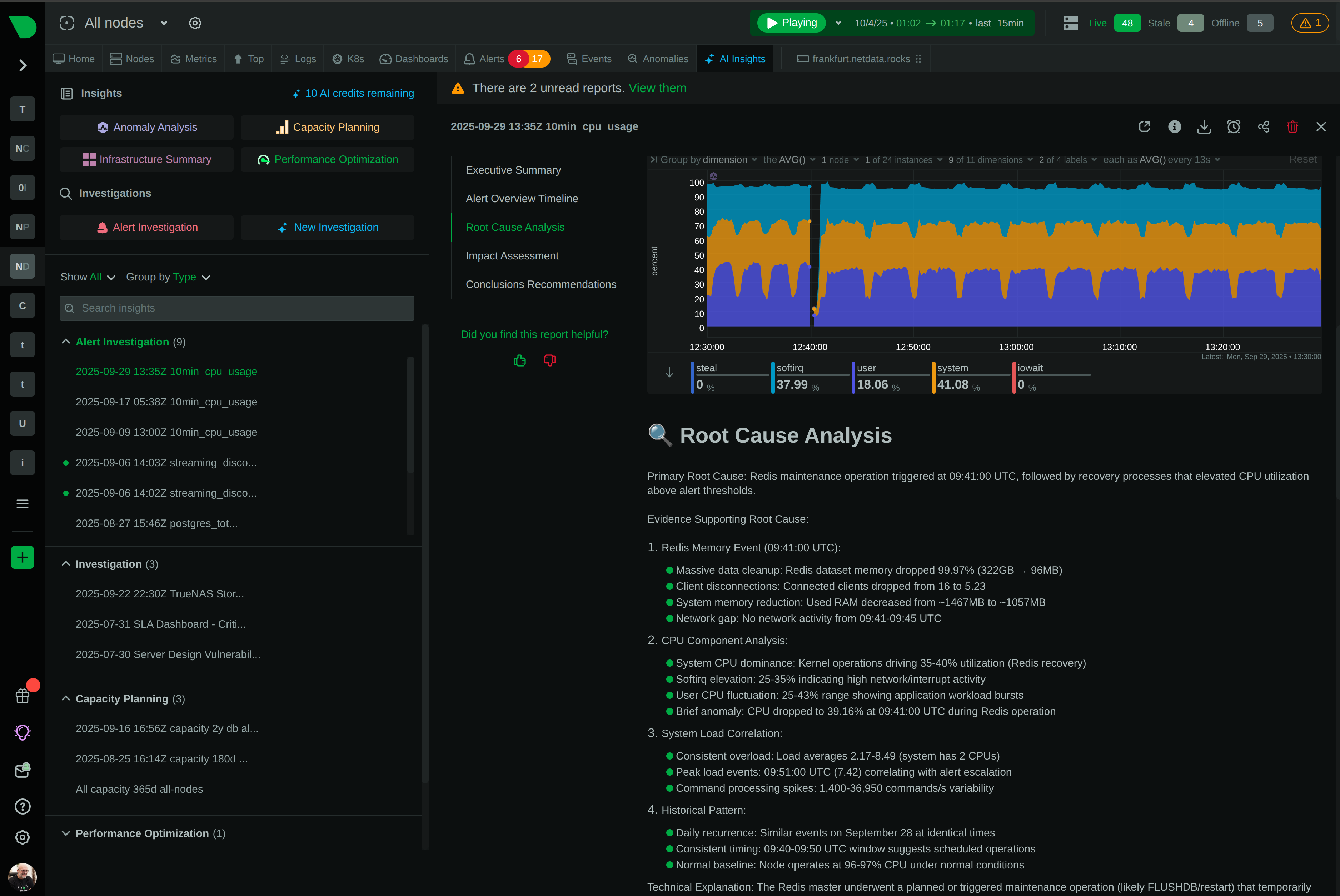
80% MTTR Reduction
See Root Cause Analysis
10-60× Faster Detection
Learn About Real-Time Monitoring
18 Models Per Metric
Explore ML Anomaly Detection
Console Replacement
See Netdata Functions
Feature Comparison
Comprehensive comparison of monitoring capabilities and coverage
Feature Category
Netdata
UptimeRobot
System Metrics
✅ Comprehensive
CPU, memory, disk, network, sensors
❌ Not Available
External checks only
Process Monitoring
✅ Per-Process
CPU, memory, I/O per process
❌ Not Available
No internal visibility
Container Monitoring
✅ Native
Docker, Kubernetes, LXC, Podman
❌ Not Available
External endpoints only
Database Monitoring
✅ 50+ Databases
MySQL, PostgreSQL, MongoDB, Redis
❌ Not Available
HTTP checks only
Network Monitoring
✅ Advanced
Connections, bandwidth, eBPF
⚠️ Basic
Ping and port checks
External Uptime Checks
⚠️ Limited
Via integrations and synthetic checks
✅ Advanced
Multi-location availability
SSL/TLS Monitoring
✅ Internal
Certificate expiration, service health
✅ External
Certificate validity checks
DNS Monitoring
✅ Service-Level
BIND, dnsmasq, PowerDNS
✅ External
DNS resolution checks
Heartbeat/Cron
✅ Reliable
systemd units, internal monitoring
⚠️ Limited
External ping-based checks
SNMP Monitoring
✅ Auto-Discovery
Network devices, switches, routers
❌ Not Available
No SNMP support
Hardware Monitoring
✅ Comprehensive
IPMI, sensors, GPUs, EDAC ECC
❌ Not Available
No hardware visibility
Custom Metrics
✅ Unlimited
StatsD, OpenMetrics, OpenTelemetry
⚠️ Limited
HTTP endpoints only
18 unsupervised ML models per metric train locally on each node. Consensus-based detection provides a separate signal for identifying anomalies with high accuracy.
10^-36 theoretical false positive rate
Learn About MLUse Case Comparison
When to use each tool for maximum operational effectiveness
Use Case
Netdata
UptimeRobot
Infrastructure Monitoring
✅ Ideal
Complete system visibility
❌ Not Applicable
External checks only
Root Cause Analysis
✅ AI-Powered
Automated correlation and diagnosis
❌ Not Available
Symptom alerts only
Live Troubleshooting
✅ Console Replacement
Browser-based debugging with history
❌ Not Available
No troubleshooting tools
Capacity Planning
✅ Advanced
AI-generated forecasts and reports
⚠️ Basic
Historical uptime data only
External Uptime Checks
⚠️ Limited
Via synthetic checks and integrations
✅ Advanced
Multi-location availability
Public Status Pages
⚠️ Basic
Limited customer-facing features
✅ Advanced
White-label status pages
APM (Application Performance)
⚠️ Partial
Infrastructure-focused, traces planned
❌ Not Available
No APM capabilities

February 27, 2026
Connect AI coding agents like Claude Code, Codex, and Cursor to your entire infrastructure with a single endpoint. The Netdata Cloud MCP Server brings infrastructure-wide observability to any MCP-compatible AI tool.

October 14, 2025
Discover the top SolarWinds alternatives for 2025. Compare modern monitoring platforms built for cloud-native infrastructure with transparent pricing and real-time insights.

October 10, 2025
Understanding recent SolarWinds pricing changes following private equity acquisition and exploring your options for infrastructure monitoring.