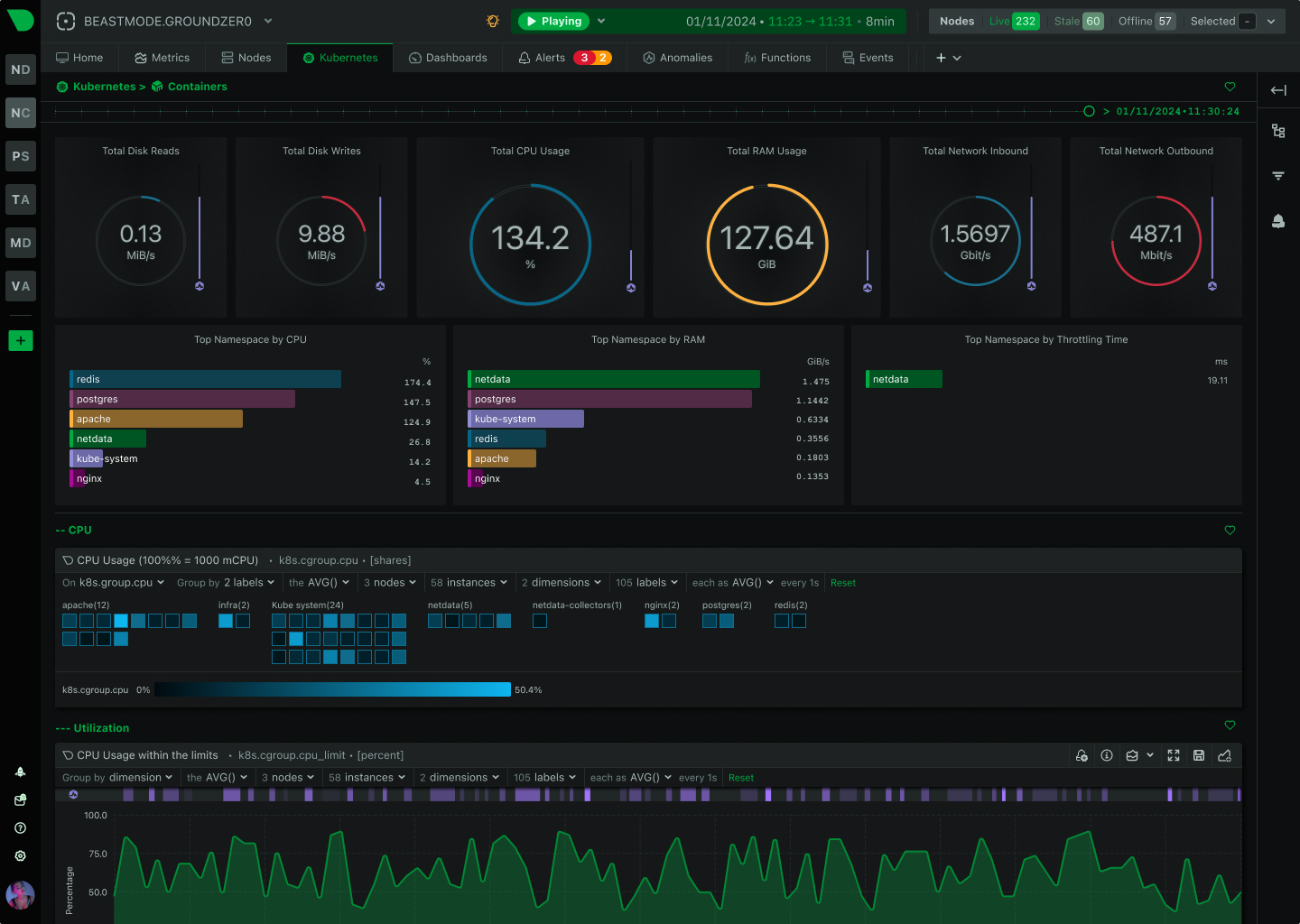
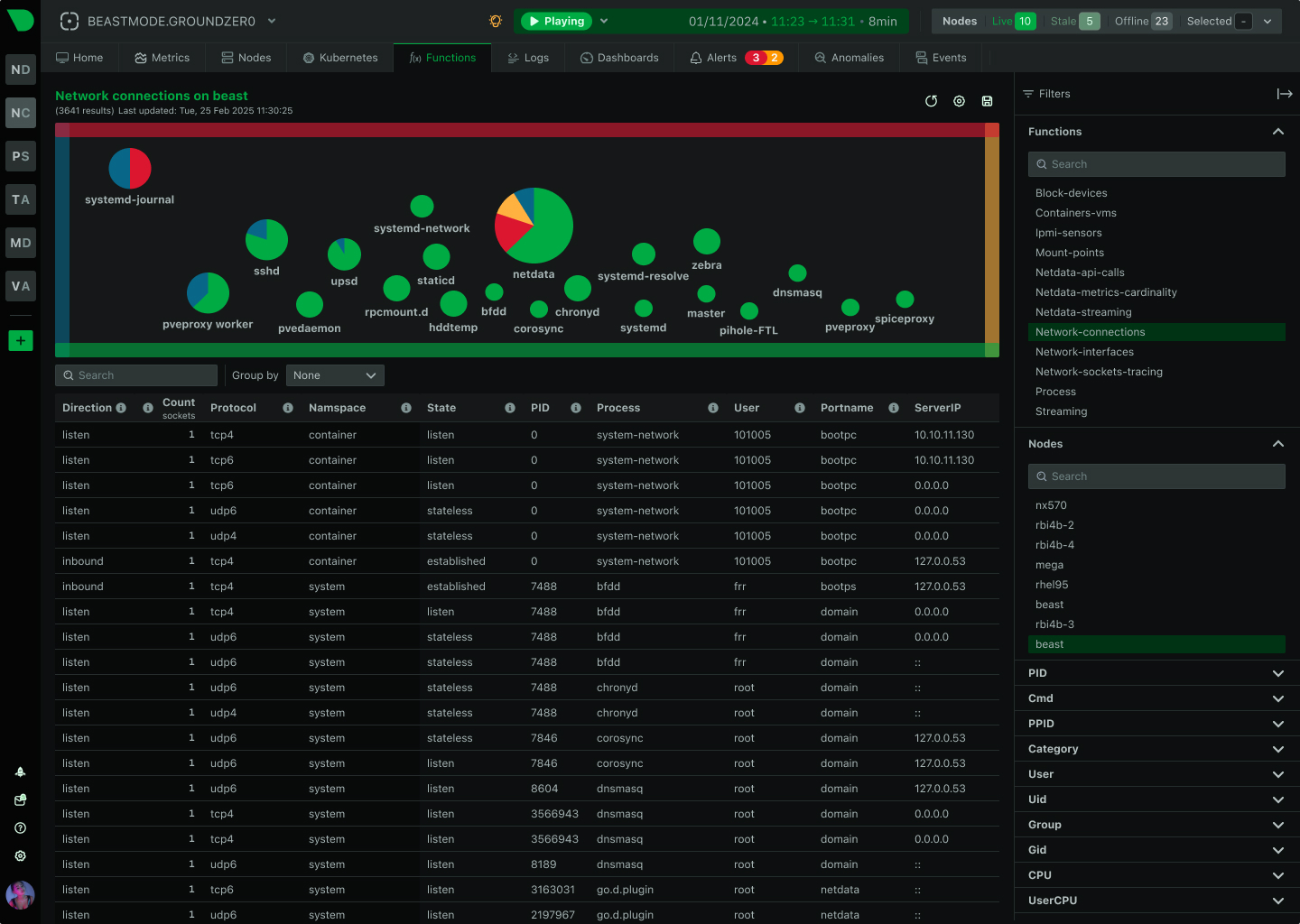
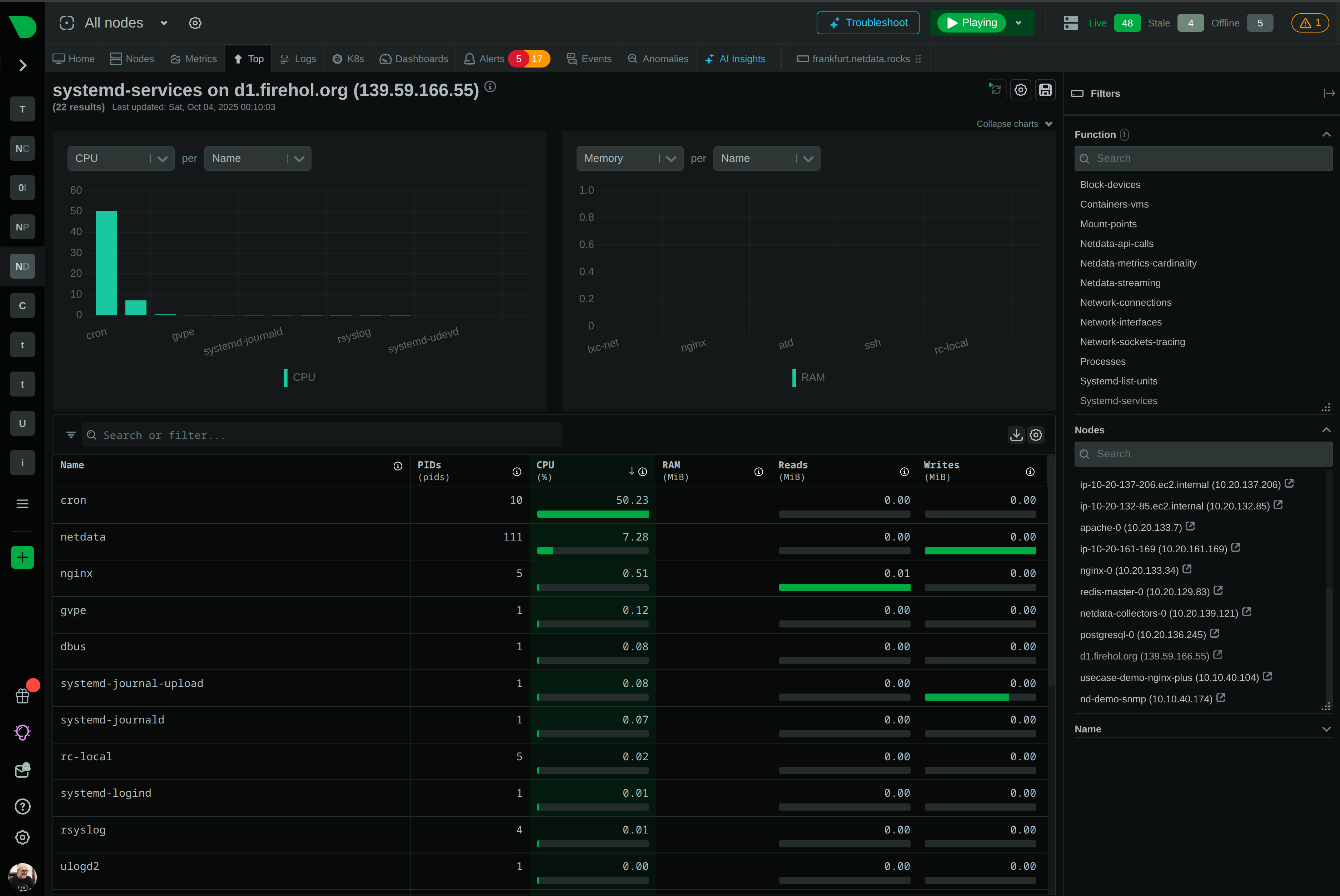
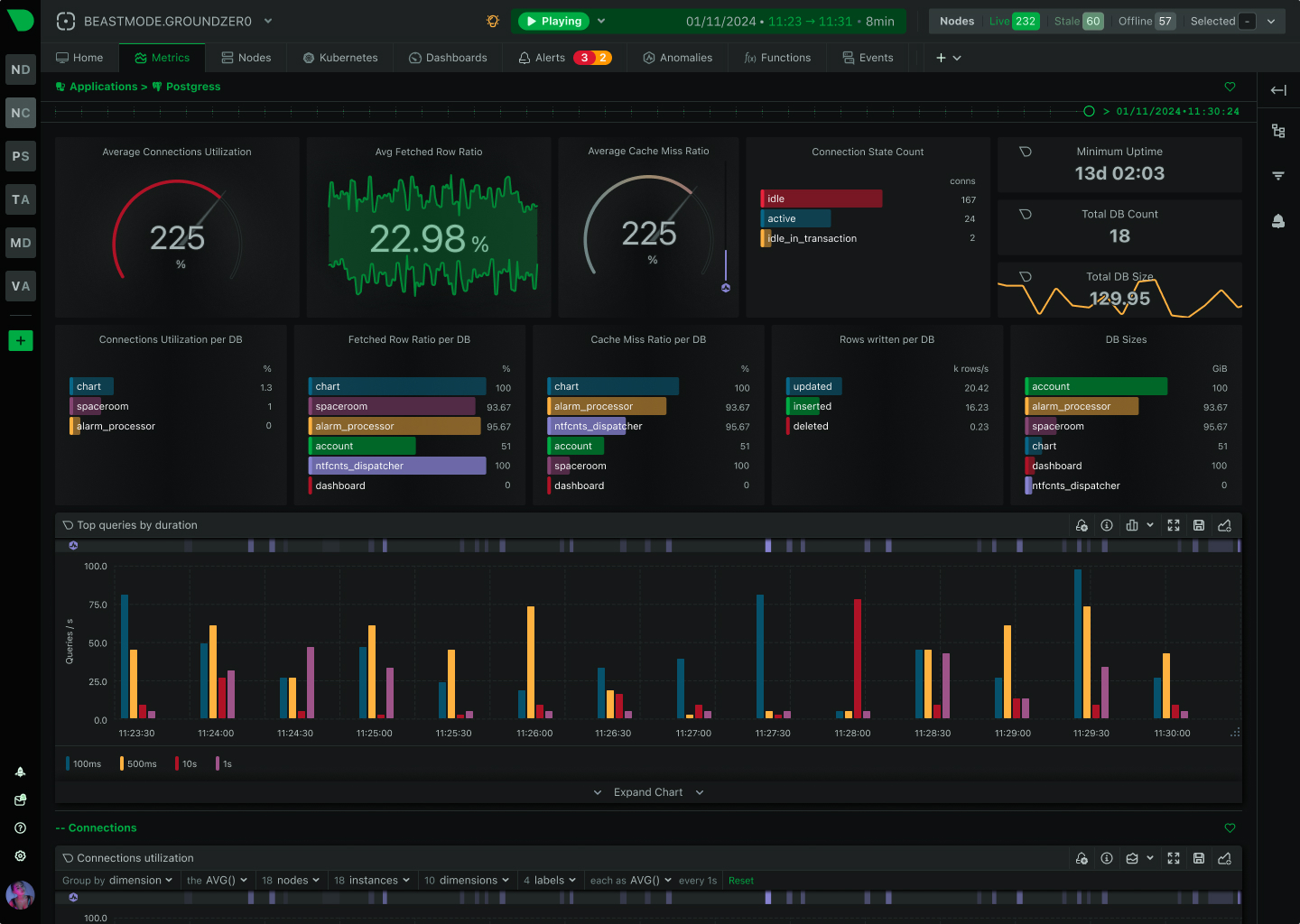
Real-Time Functions, Executed on Your Nodes
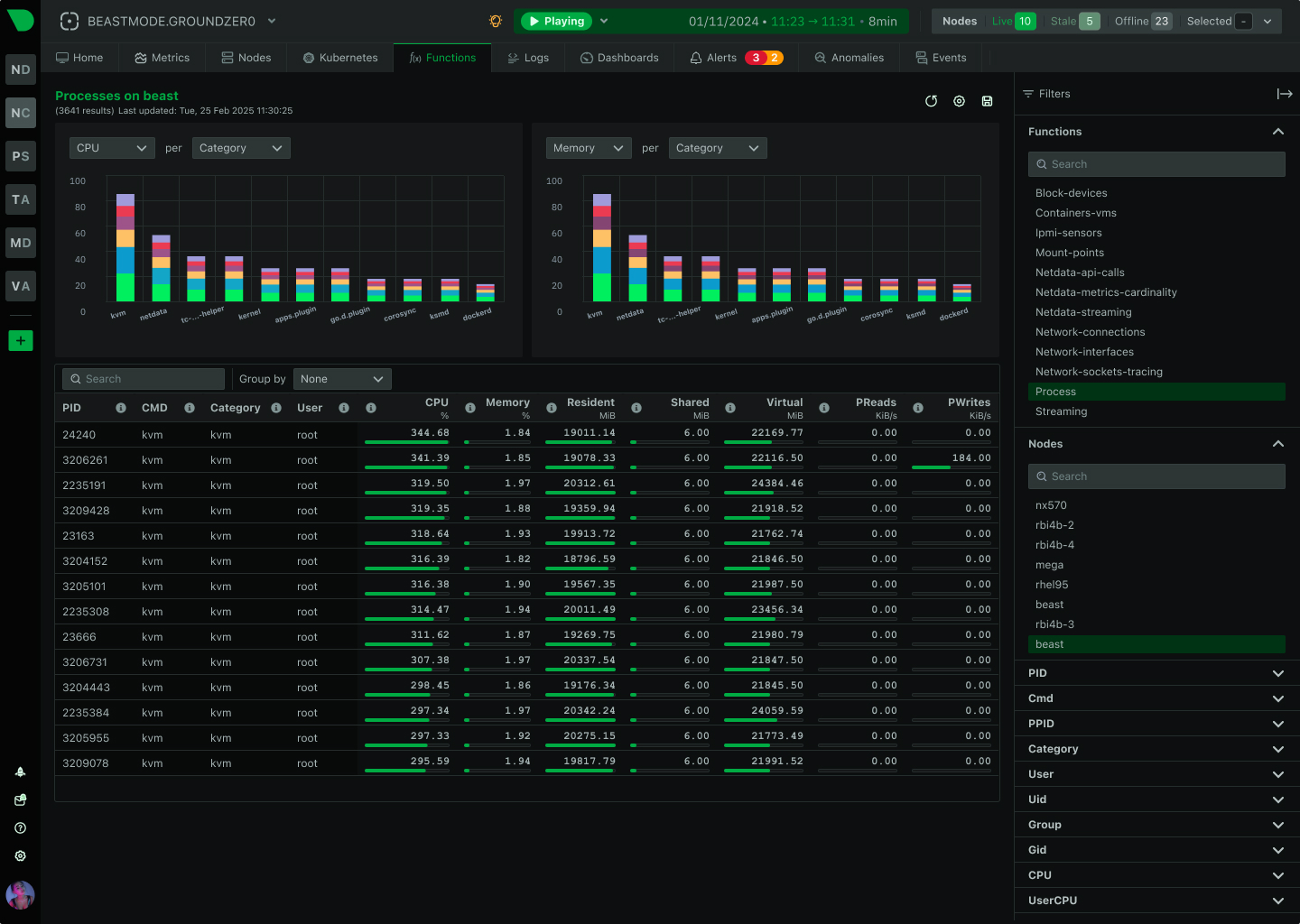
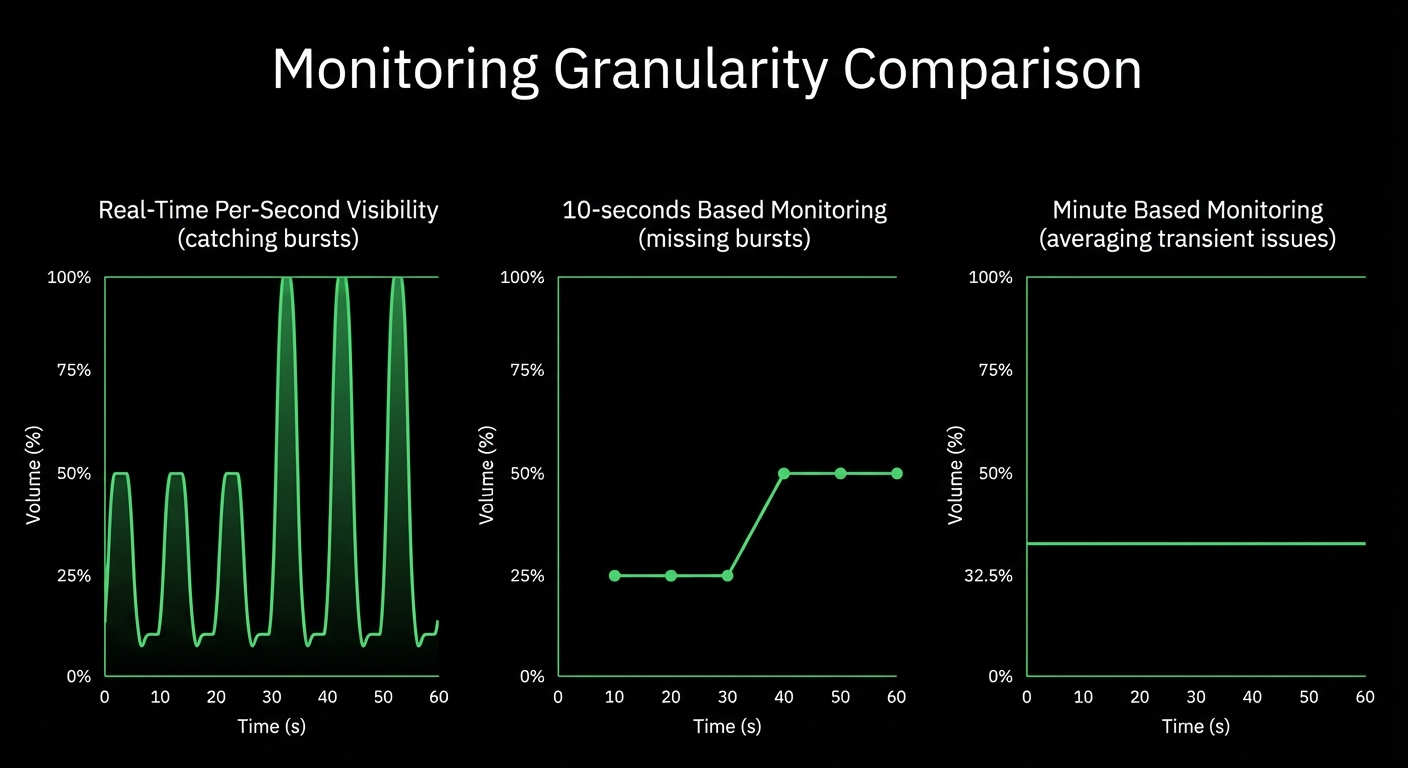
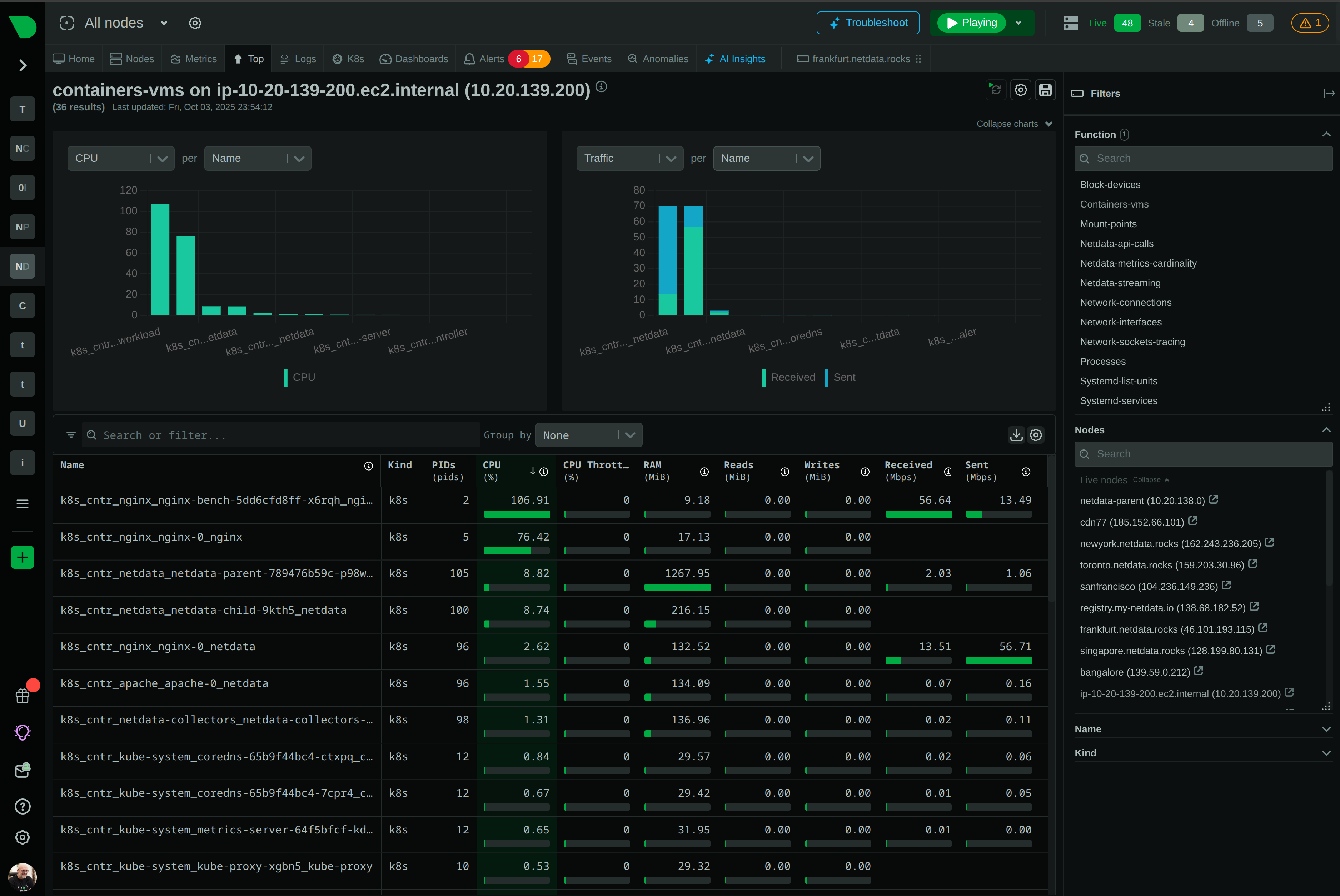
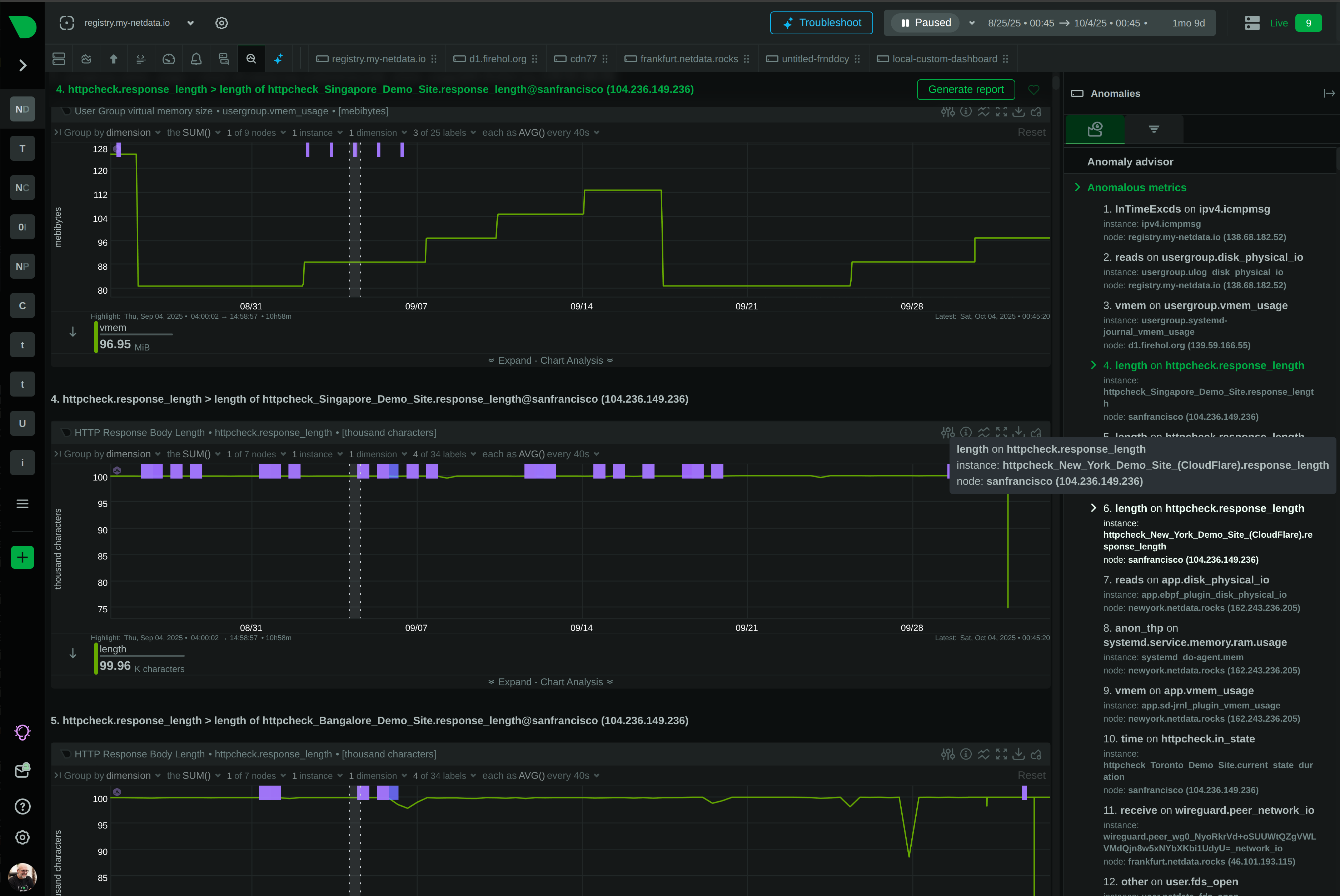
The Live tab gives you real-time access to Netdata Functions - specialized routines provided by collectors that deliver live information from your monitored nodes. Process explorers, database monitoring, network topology maps, diagnostics, and troubleshooting actions - all from your browser.