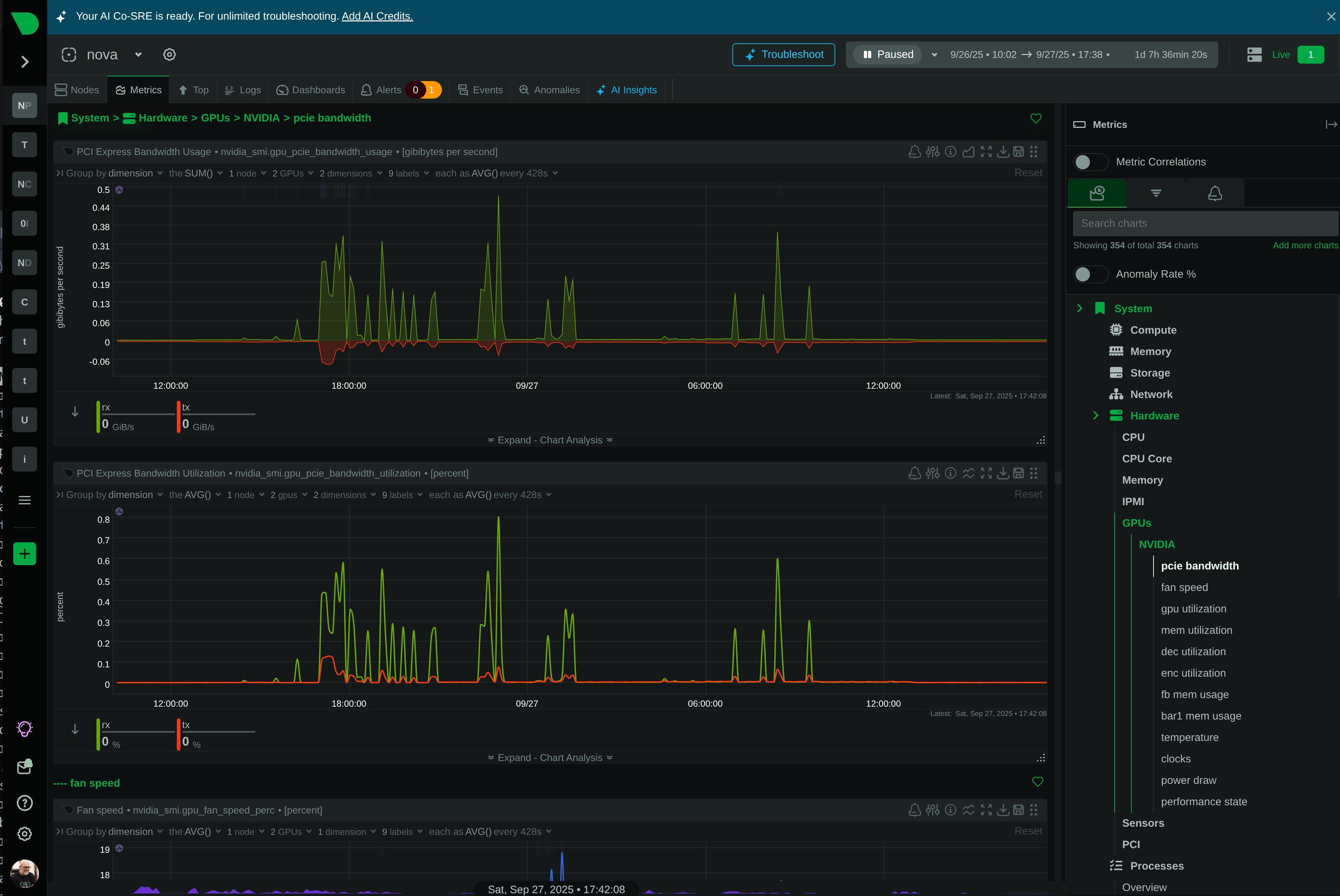
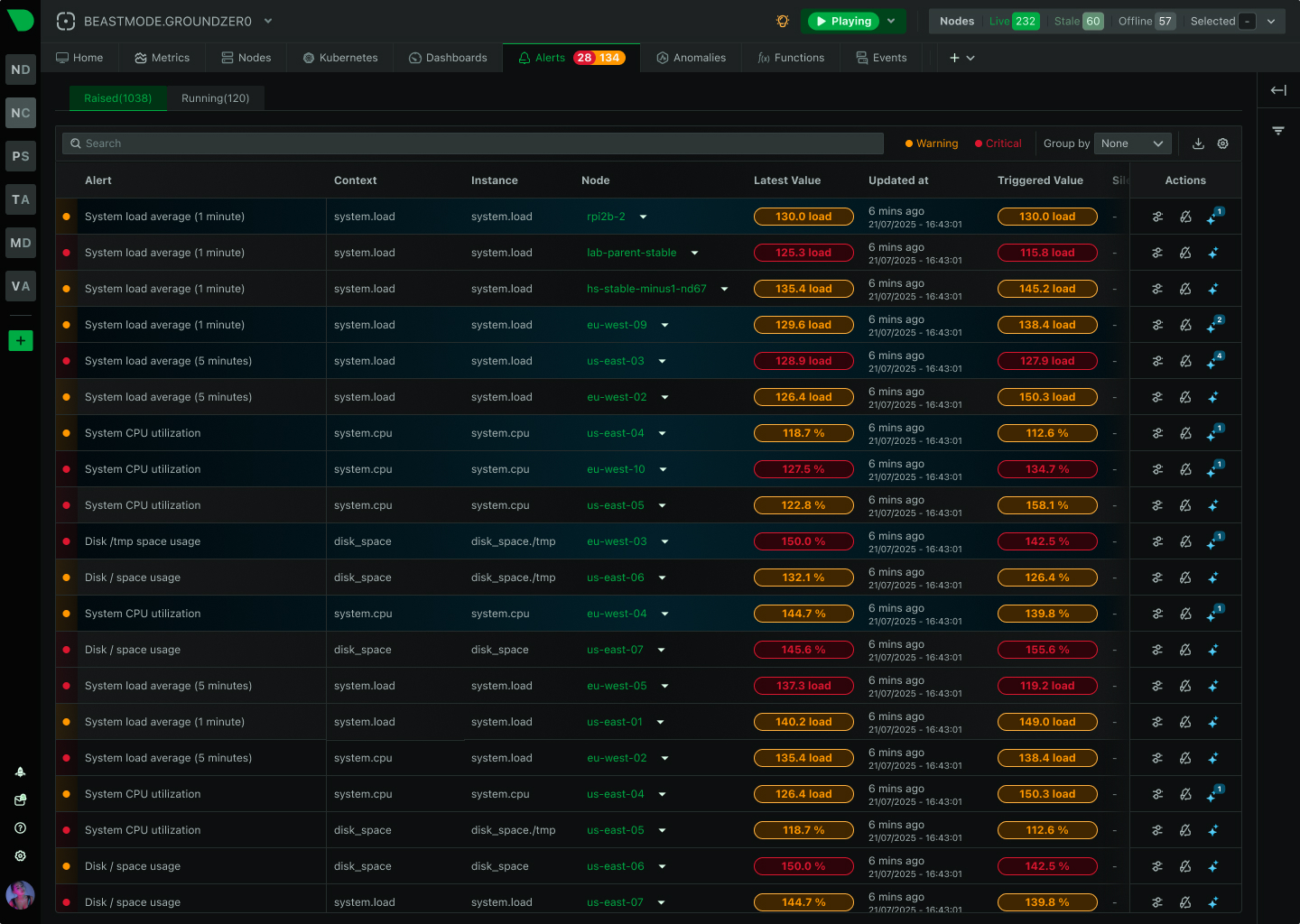
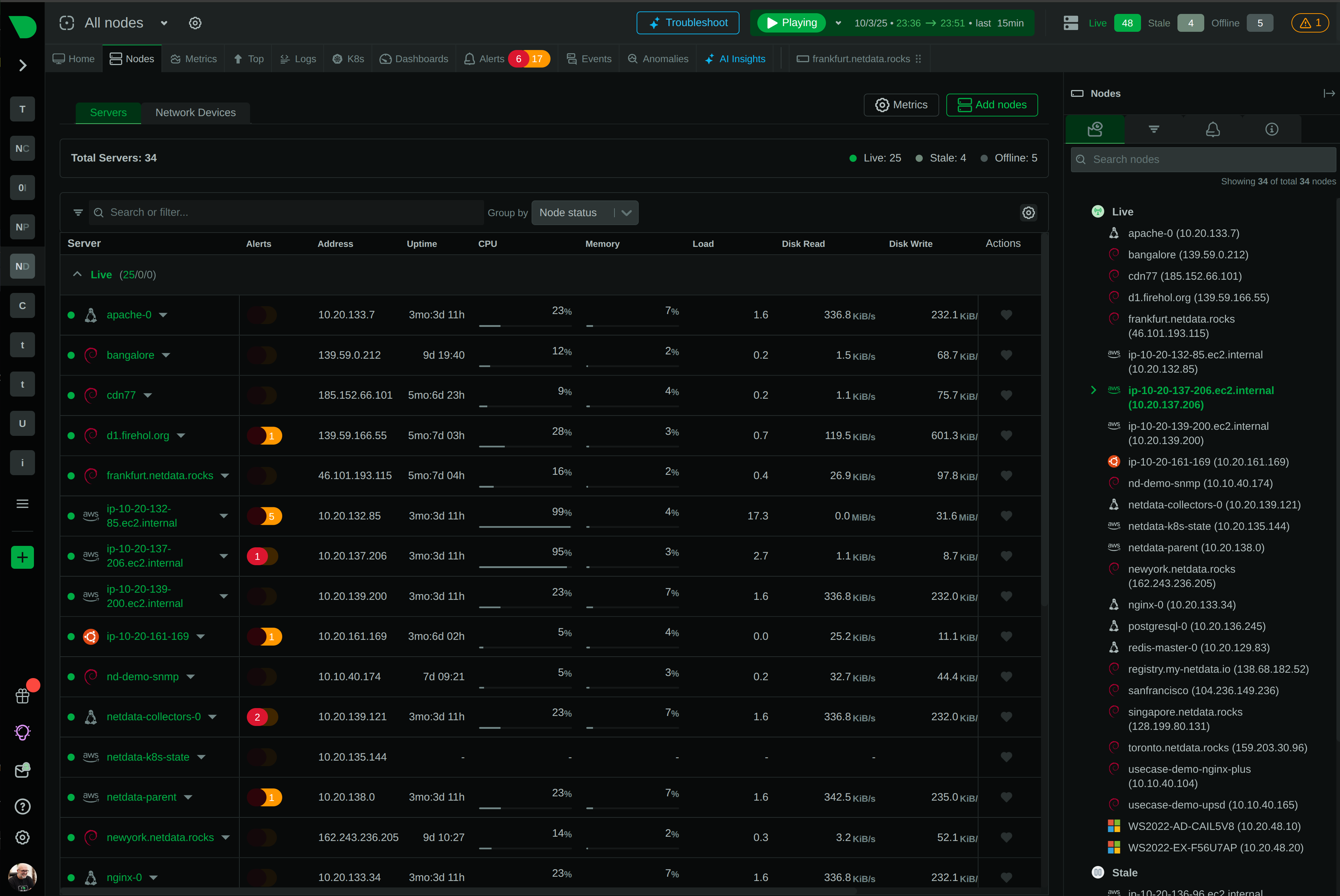
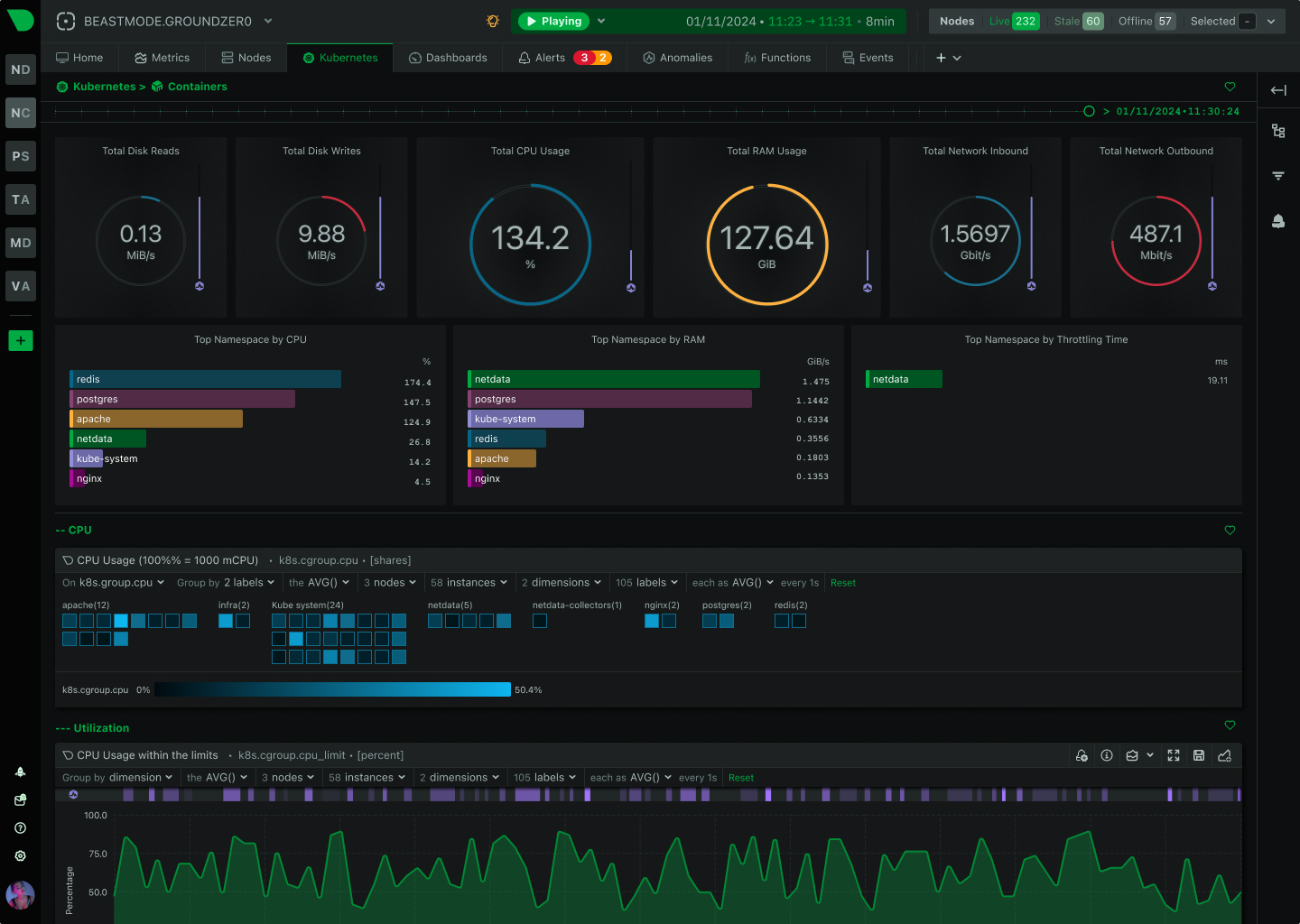
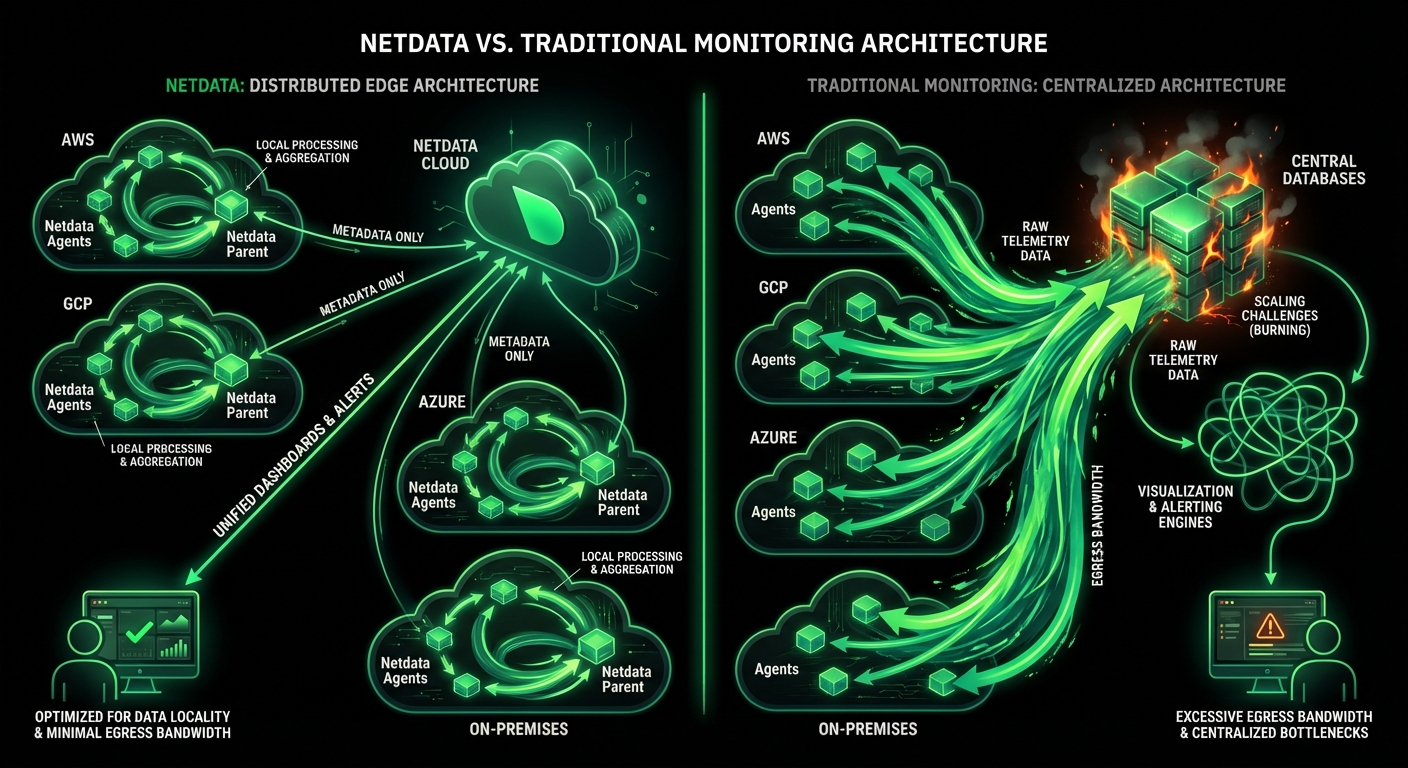
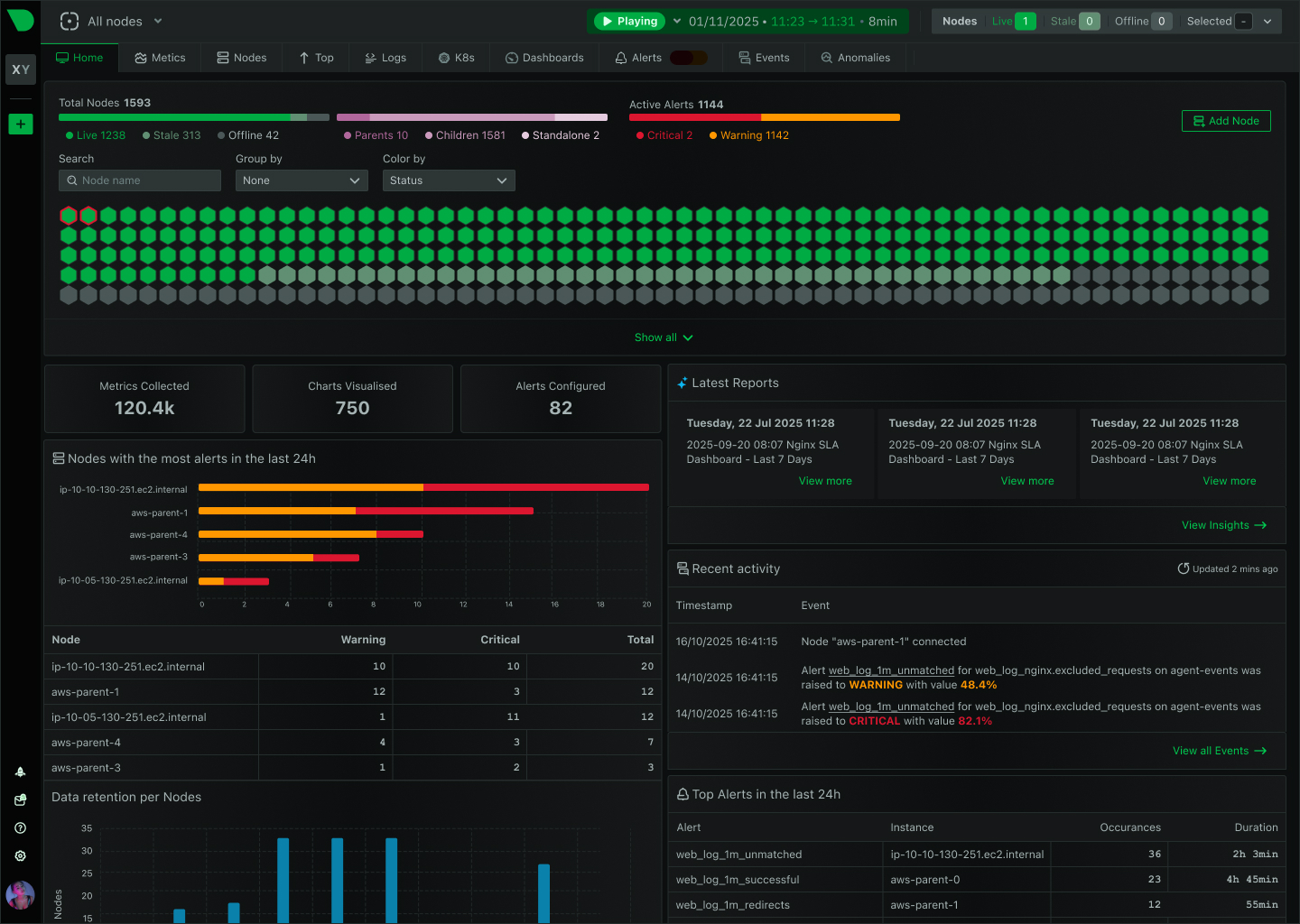
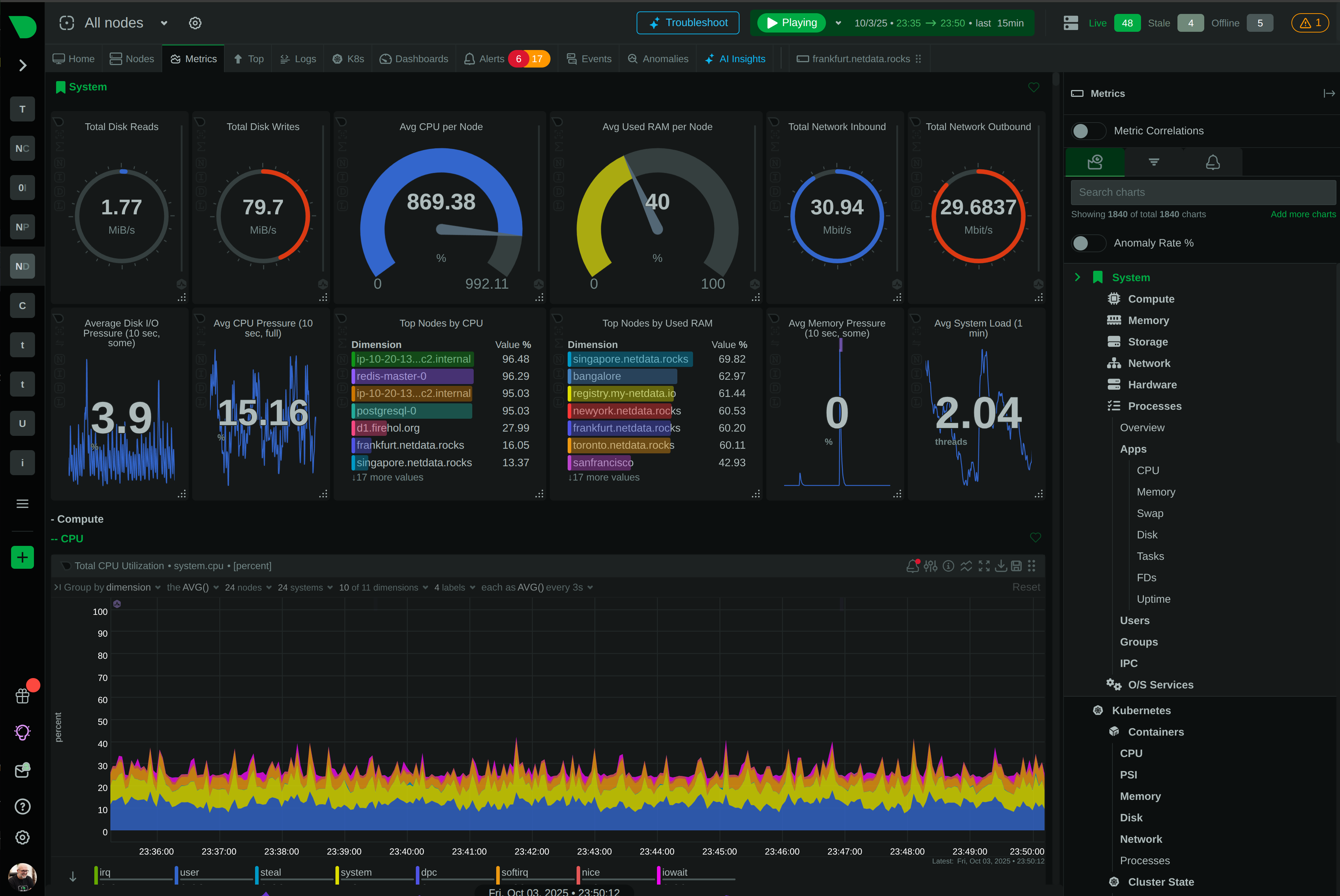
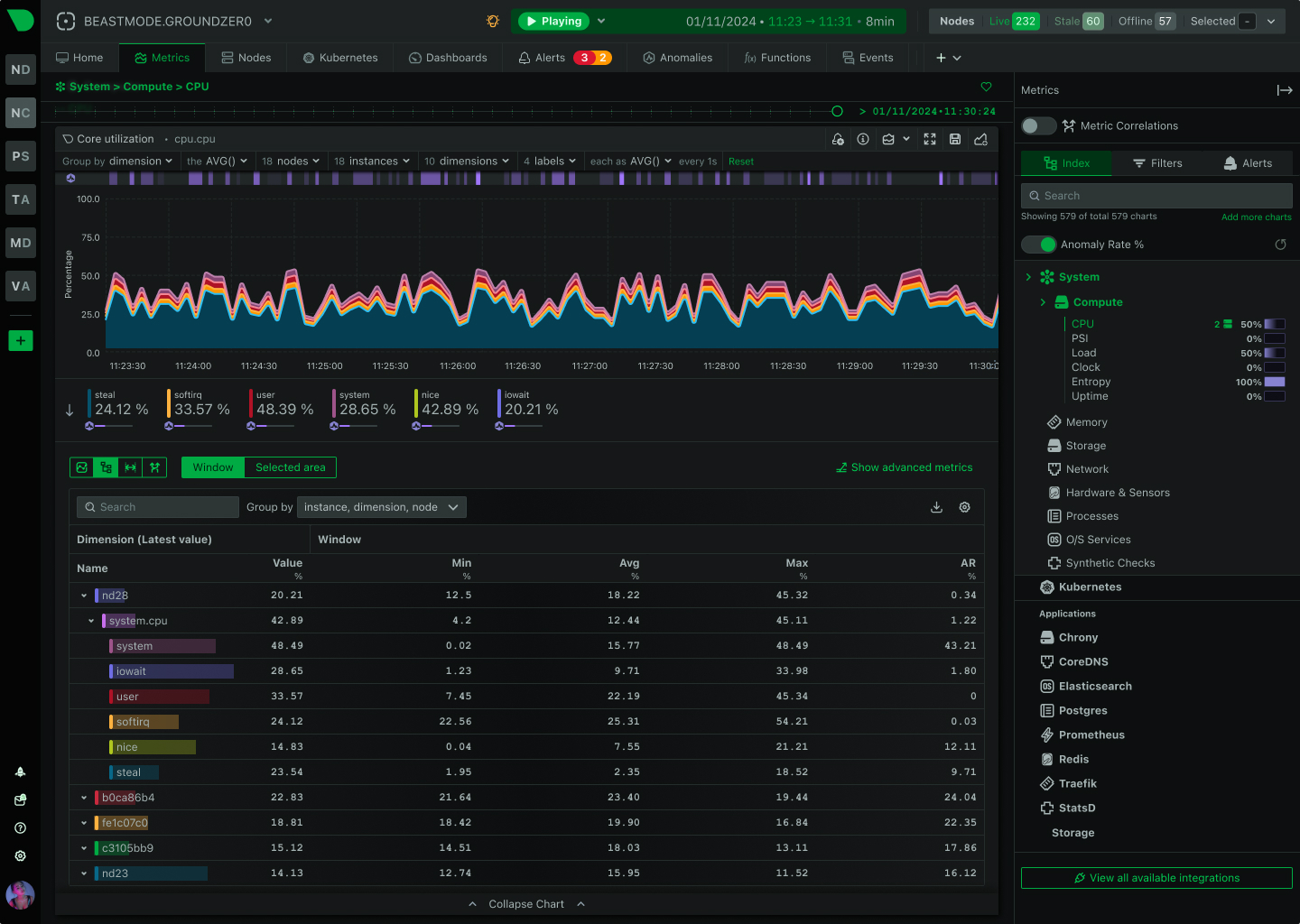
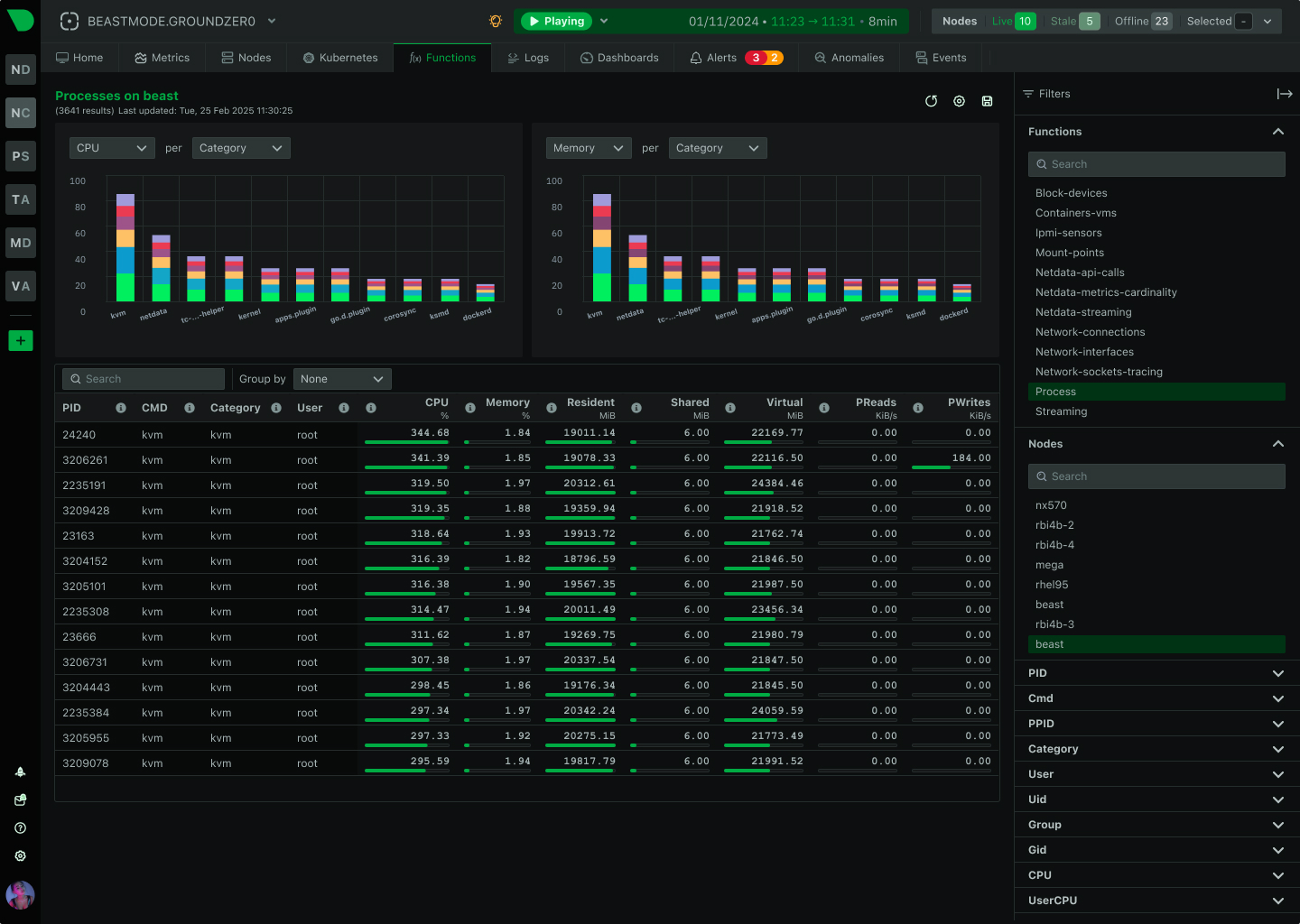
See Every GPU Cycle, Catch Every Anomaly, Control Every Cost
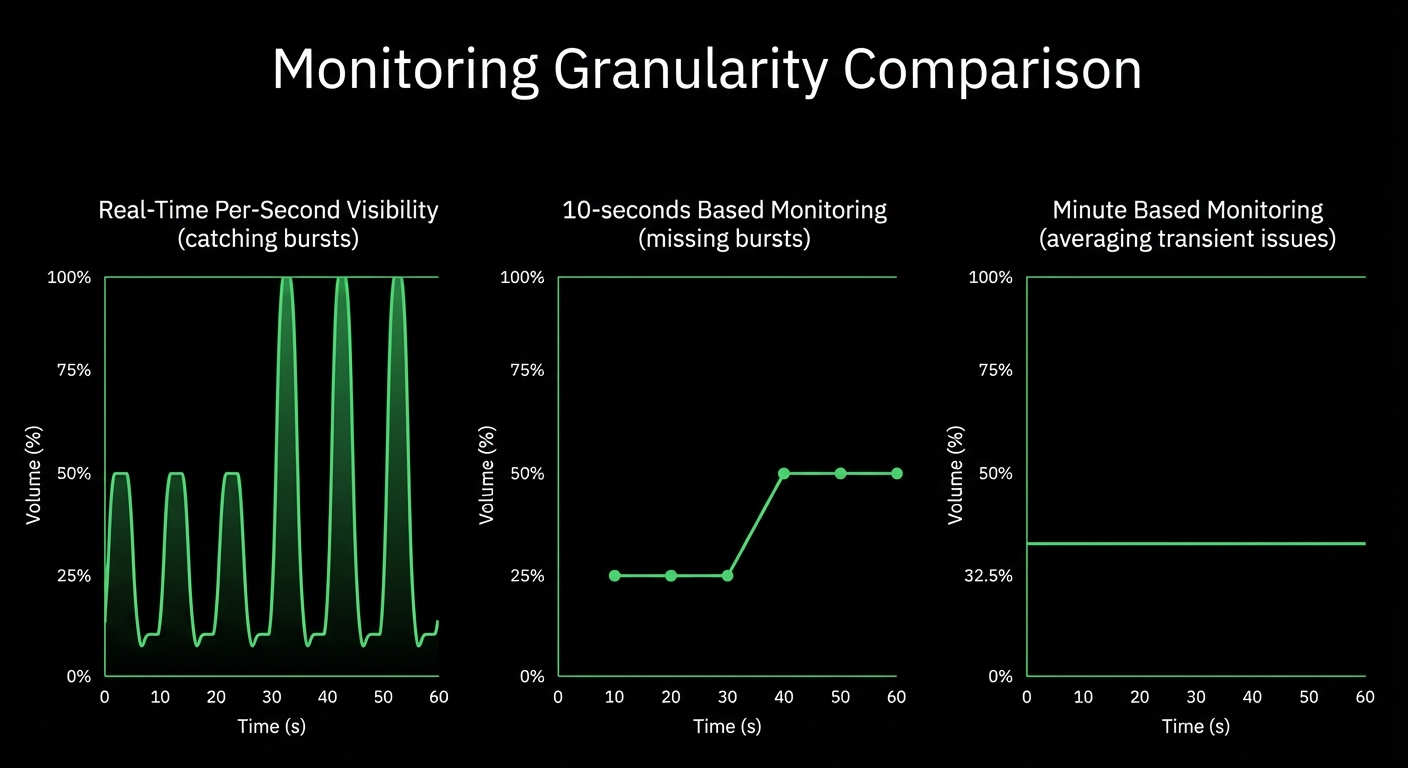
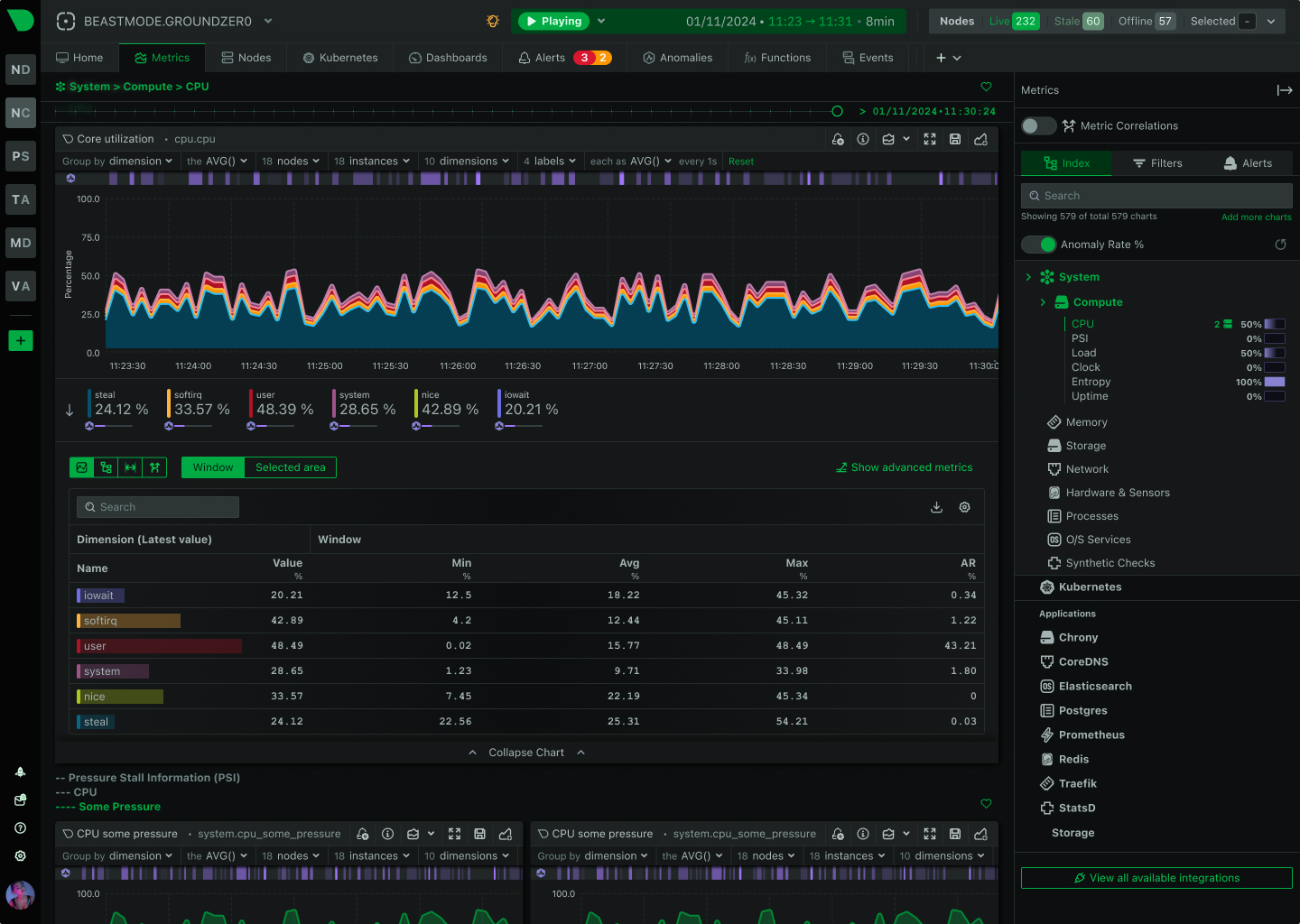
Monitor AI training clusters, inference APIs, and ML workloads with per-second precision. Netdata delivers real-time visibility into GPU utilization, resource bottlenecks, and infrastructure health - without the complexity or cost explosion of traditional monitoring.