Stop managing alert fatigue. Prevent it.
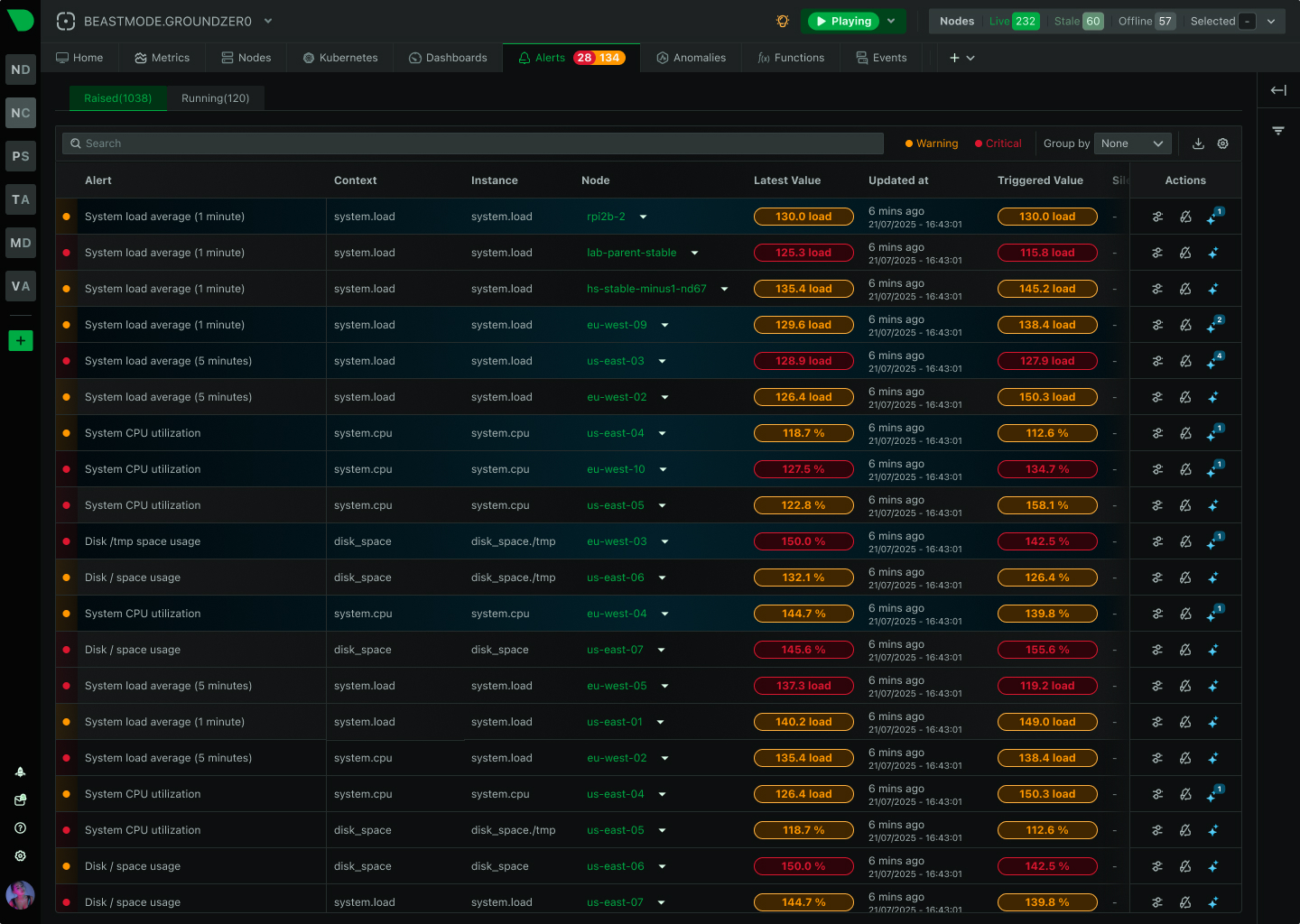
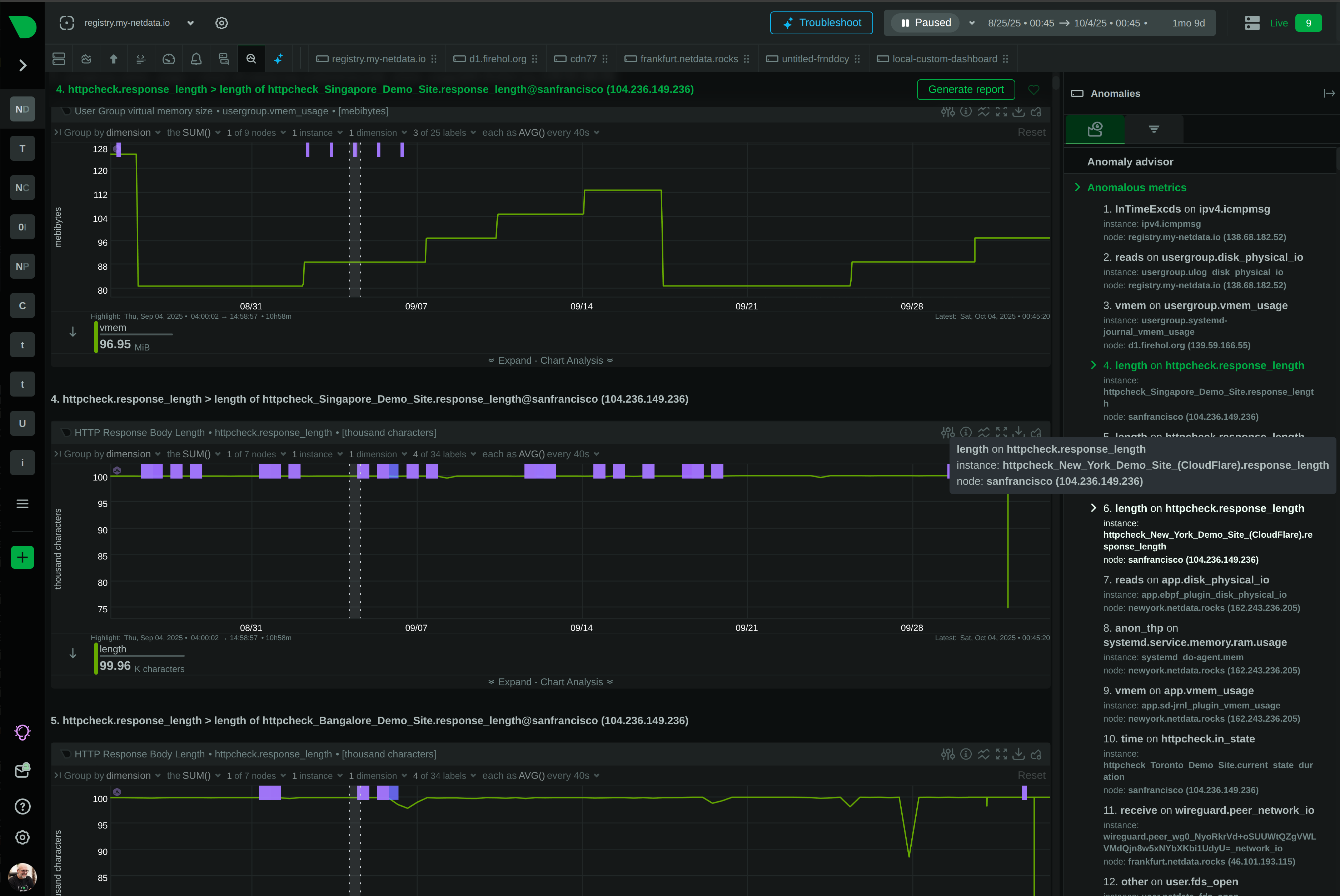
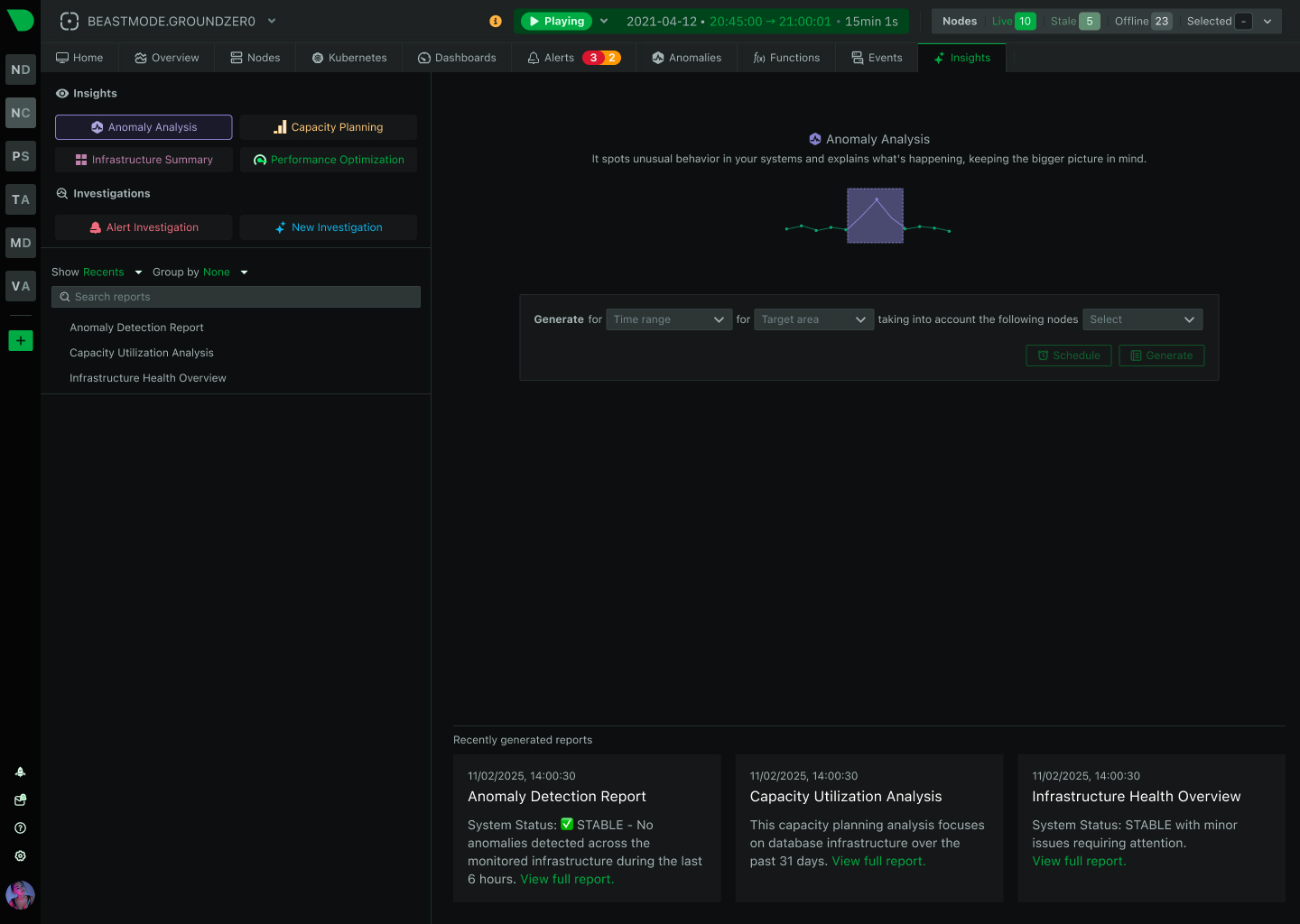
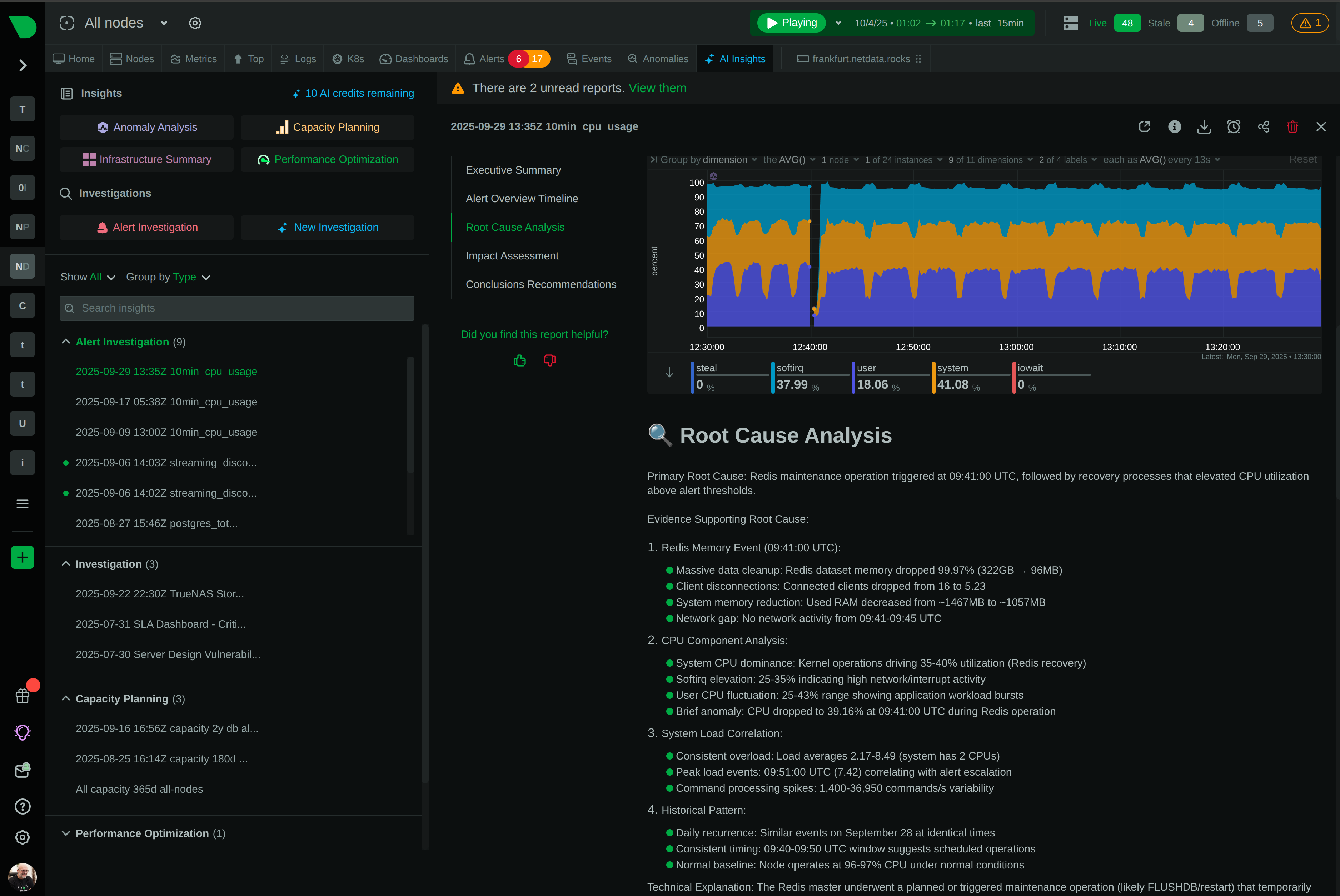
Most alert-fatigue tools cluster, correlate, and suppress the noise after it fires. That’s symptom management. Netdata prevents the noise at the source — per-metric ML with consensus voting means only anomalies that multiple independent models agree on ever become alerts.