See Every Millisecond That Matters
Traditional APM tools sample data and miss critical events. Netdata captures every metric every second with ML-powered anomaly detection that achieves 99% false positive reduction while cutting costs by 90%.

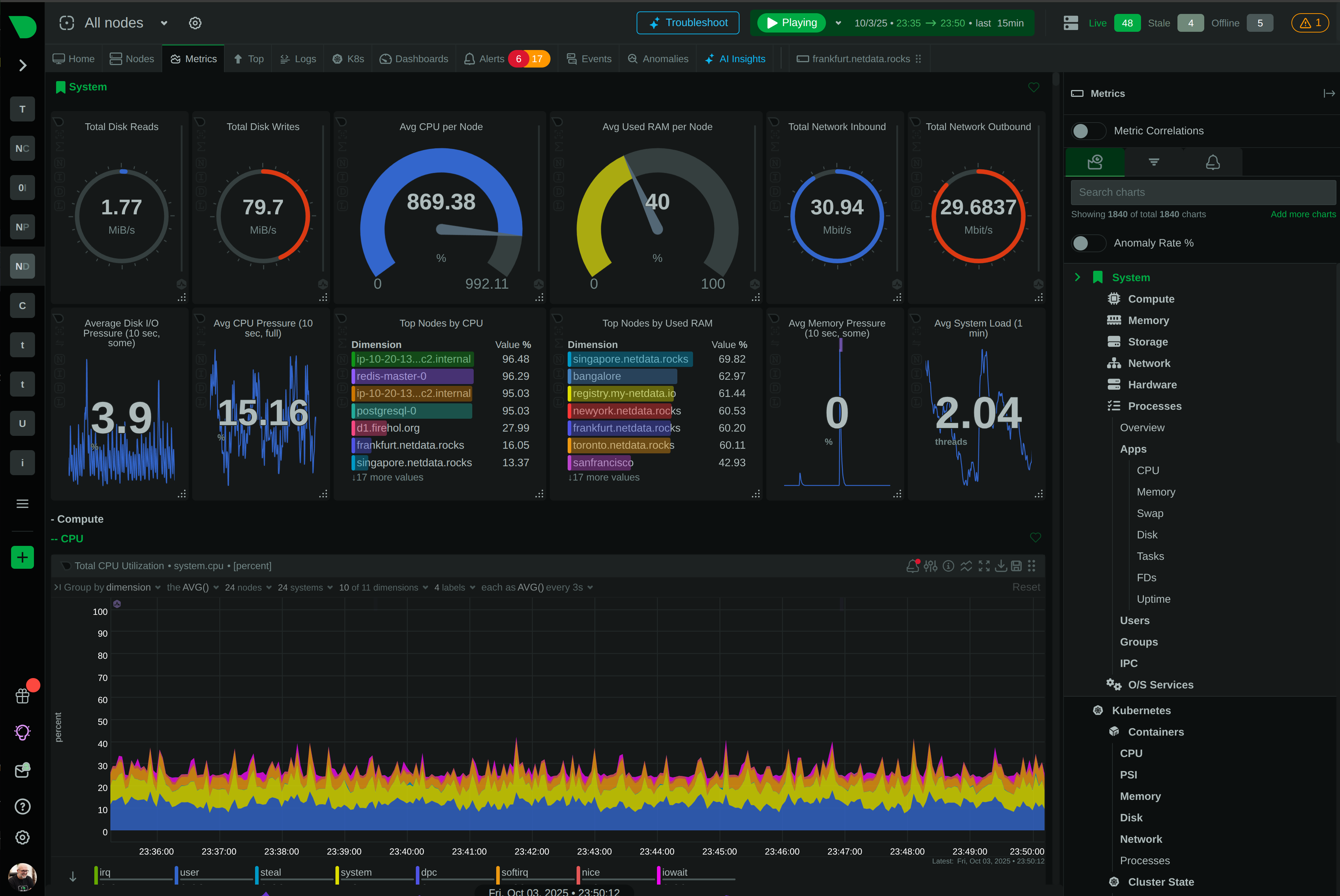
Traditional APM tools sample data and miss critical events. Netdata captures every metric every second with ML-powered anomaly detection that achieves 99% false positive reduction while cutting costs by 90%.
The only monitoring platform that combines per-second visibility, edge-native ML, and zero-configuration deployment
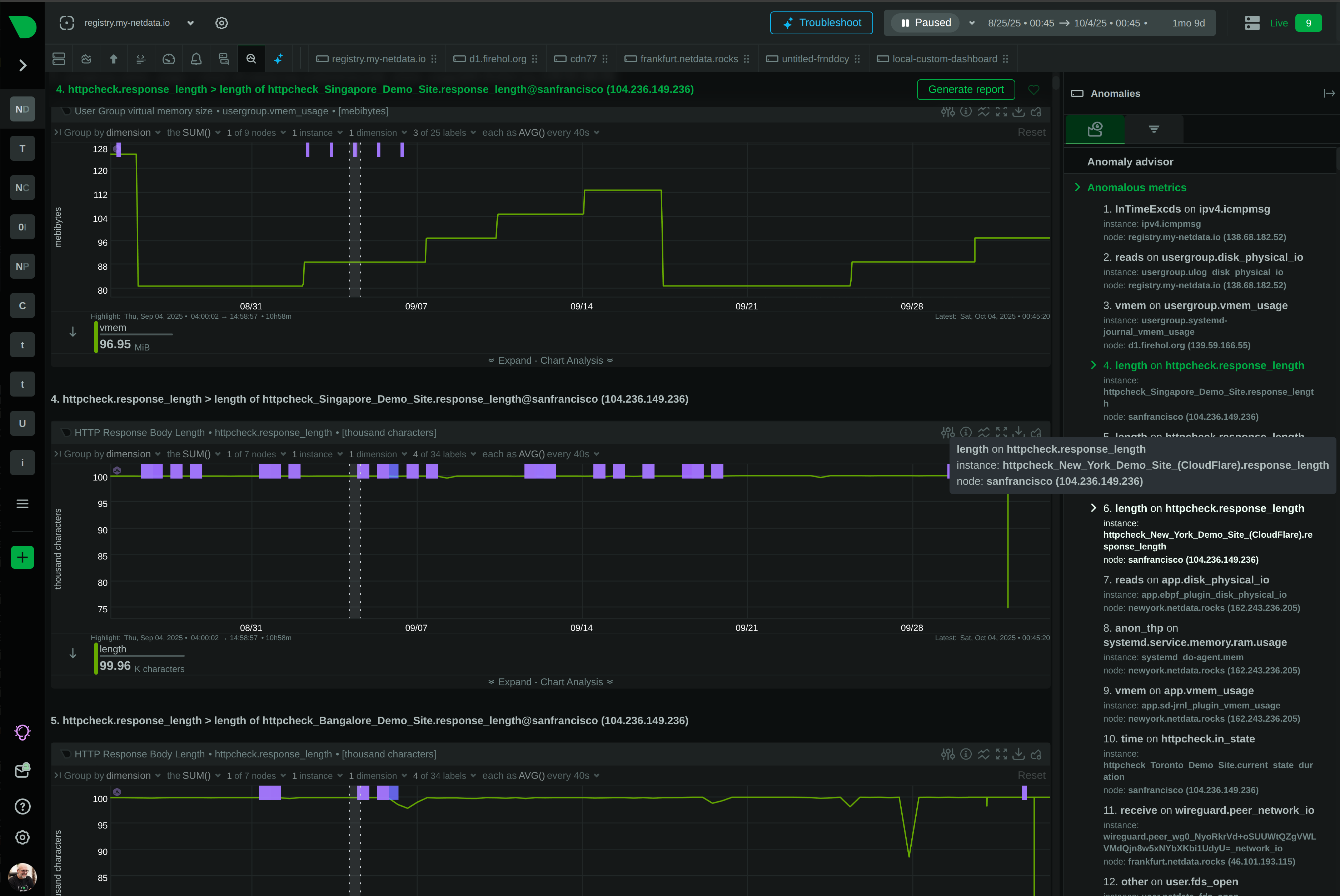
Per-second metrics and ML-powered Anomaly Advisor surface root causes in the top 30-50 results, eliminating hours of manual investigation
18-model ML consensus mechanism achieves 99% false positive reduction in anomaly detection while catching real issues other tools miss
Per-node pricing with unlimited metrics, logs, and users replaces expensive volume-based APM at a fraction of the cost
Zero-configuration deployment with automatic service discovery and algorithmic dashboards delivers immediate value
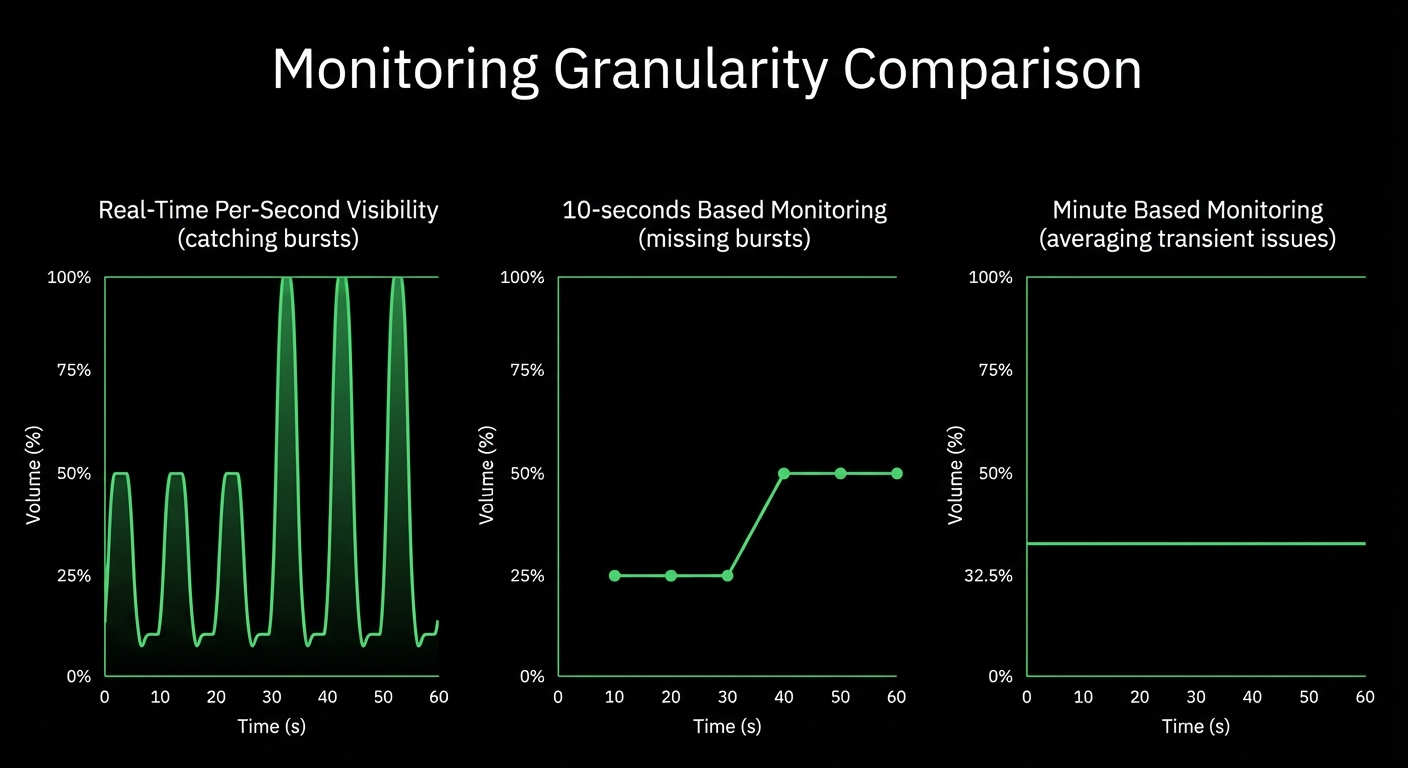
Per-second granularity captures microbursts and transient issues that 30-second monitoring completely misses
Natural language queries and automated root cause analysis accelerate incident response for teams of any skill level
Trusted by DevOps teams worldwide
10-60× more granular than traditional APM
Learn about real-time monitoring
18-model ML consensus
Explore ML anomaly detection
80% MTTR reduction
See root cause analysis
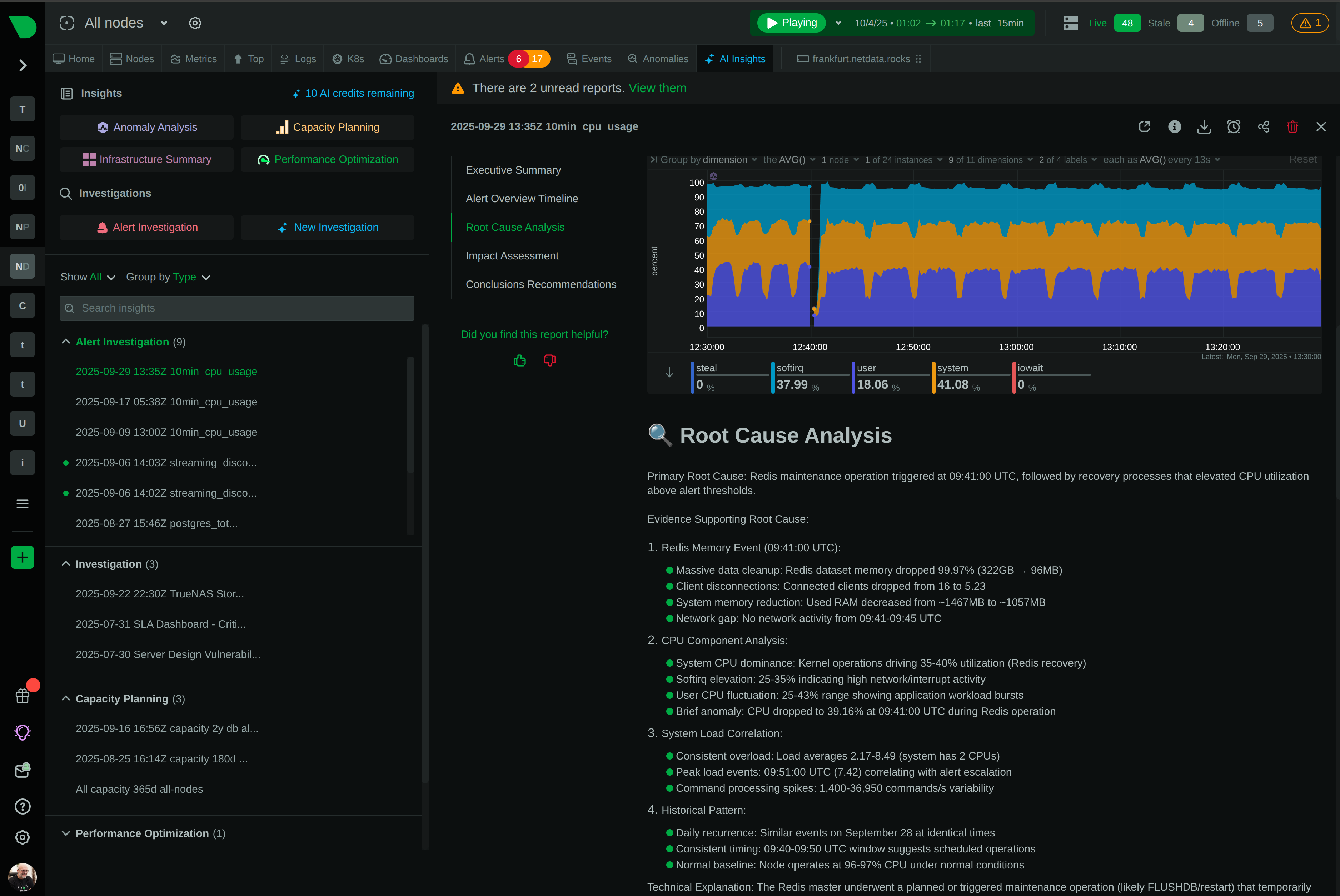
60 seconds to value
View quick start guide
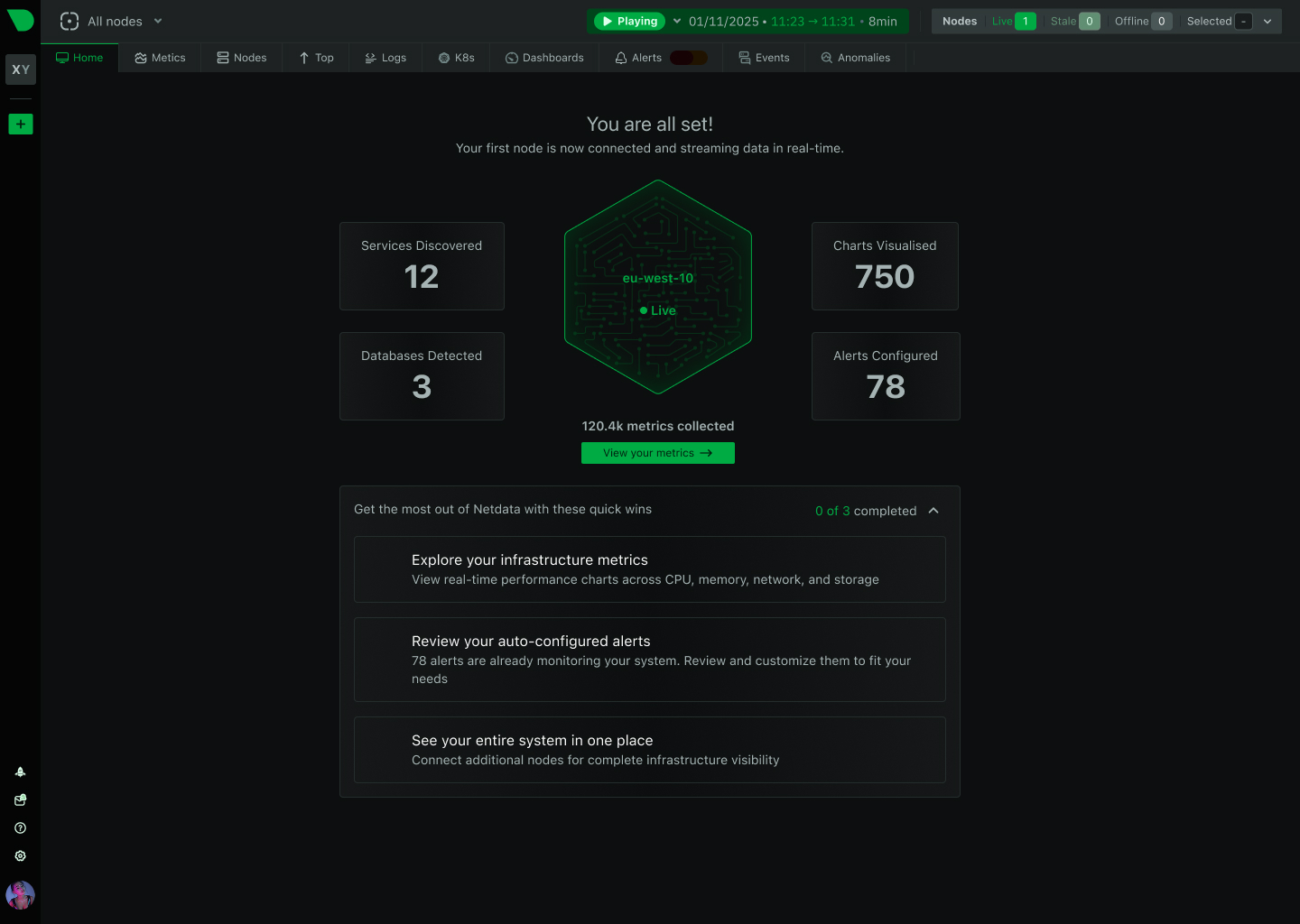
90% cost savings vs traditional APM
Compare pricing
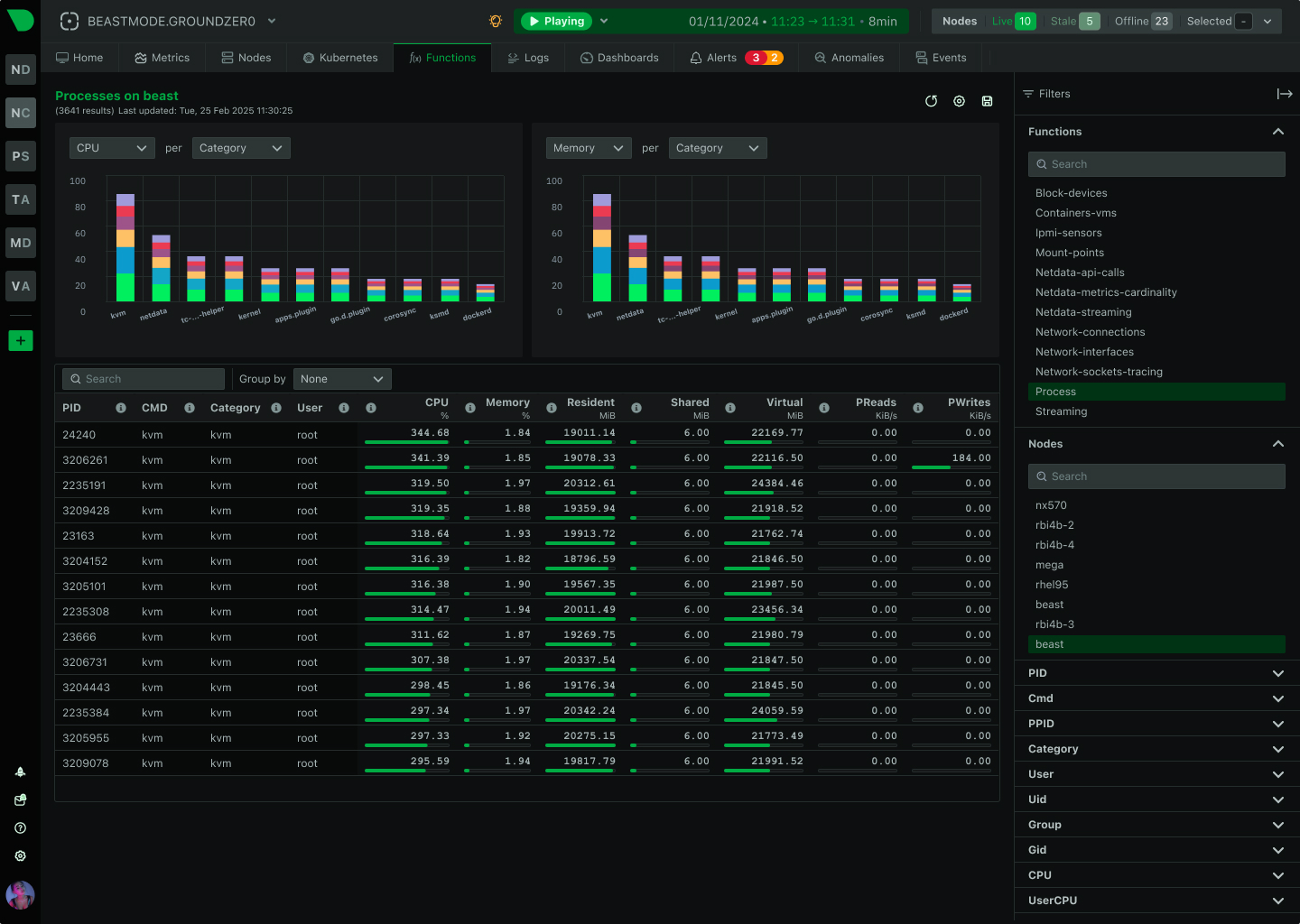
Console replacement with history
Explore Netdata Functions

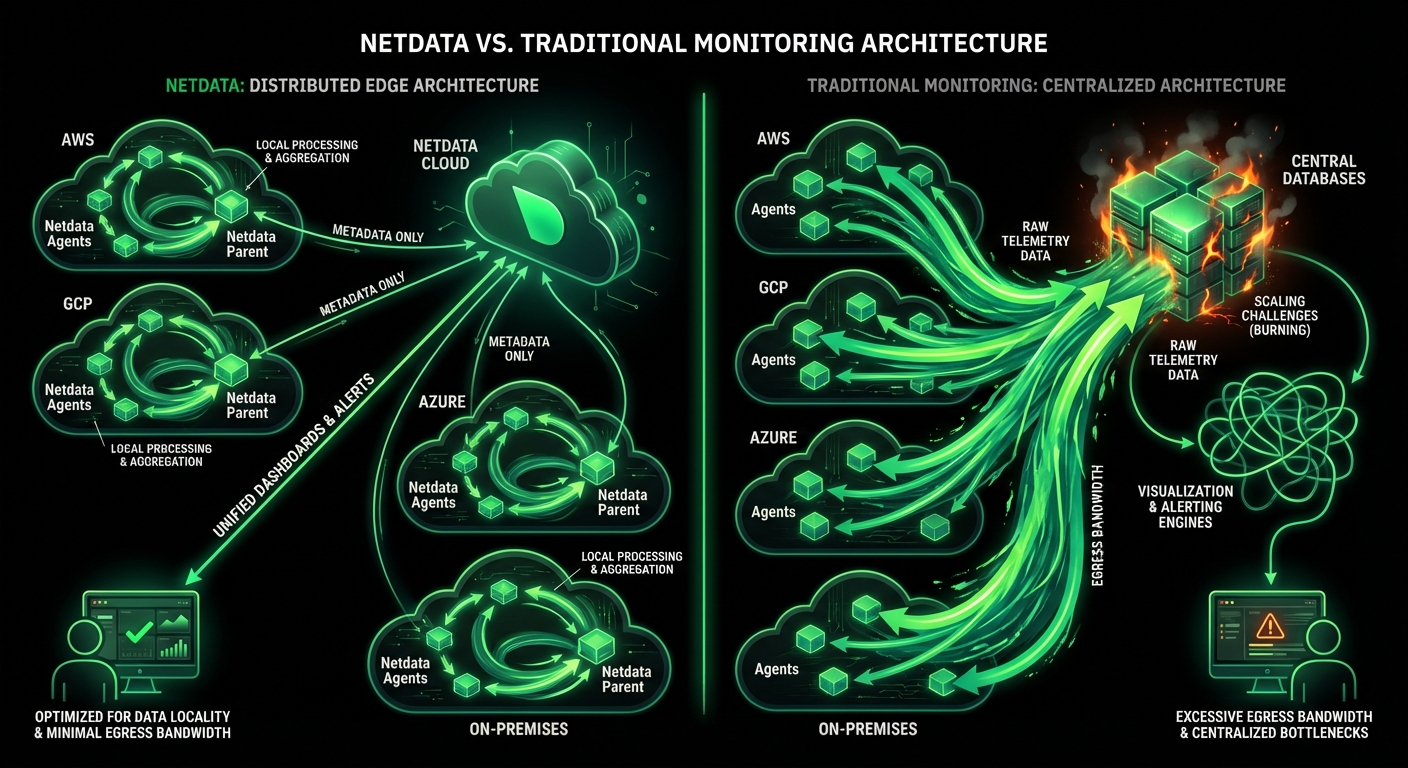
How Netdata Compares
See how Netdata’s edge-native architecture delivers superior performance monitoring at a fraction of traditional APM costs
Capability
Netdata
Traditional APM
Data Granularity
✅ Per-Second
Captures every metric every second
⚠️ 15-60 Seconds
Misses 90% of transient issues
Sample Completeness
✅ 100% Fidelity
Zero sampling, no data loss
⚠️ 85-95% Sampled
Critical traces often dropped
Anomaly Detection
✅ 18-Model ML
99% false positive reduction
⚠️ Single Model
High false positive rates
Setup Time
✅ 60 Seconds
Zero configuration required
⚠️ Days to Weeks
Extensive manual setup
Query Language
✅ None Required
Point-and-click NIDL framework
⚠️ PromQL/NRQL/SPL
Steep learning curve
Root Cause Analysis
✅ Automated
Top 30-50 results via ML
⚠️ Manual
Hours of investigation
Data Sovereignty
✅ 100% On-Premises
Zero metric data in cloud
❌ Cloud SaaS
All data centralized
Cost Model
✅ Per-Node Fixed
Predictable, no volume charges
❌ Volume-Based
Surprise bills common
Cost Comparison
✅ 90% Lower
Transparent P90 billing
❌ Premium Pricing
Plus volume charges
Agent Overhead
✅ <5% CPU
150-200MB RAM with ML
⚠️ 10-20% CPU
Higher resource usage
High Cardinality
✅ Unlimited
Edge processing eliminates limits
⚠️ Limited
Backends drop attributes
Kubernetes Support
✅ Native
Per-second container metrics
⚠️ Challenging
40% cite as top issue
Traditional APM centralizes data for analysis, creating bottlenecks and latency. Netdata trains 18 ML models per metric directly on each monitored system, enabling real-time anomaly detection with consensus-based accuracy that achieves 99% false positive reduction.
99% false positive reduction
Learn about ML architectureMonitor every layer of your application stack with per-second precision
CPU, memory, disk, network with per-second granularity across servers, VMs, and containers
Per-container resource tracking with automatic Kubernetes and Docker discovery
Zero-pipeline log management via systemd-journal with 200× more accurate analysis
Real-time visibility into active connections, bandwidth, and connection states
Per-process CPU, memory, I/O with automatic service grouping and classification
Query performance, connection pools, and resource usage for major databases
Request rates, response times, and error tracking for NGINX, Apache, IIS
18-model consensus on every metric achieving 99% false positive reduction
Automated correlation engine surfaces root causes in top 30-50 results

February 3, 2026
Join Netdata at the Howard Conference and Expo 'Game On' event, February 24-26, 2026 in Fairhope, Alabama. Learn how real-time, high-fidelity monitoring helps you stay ahead of infrastructure challenges.

February 3, 2026
Visit Netdata at Tech Show London, March 4-5 at ExCeL London. Stop by Booth F223 in the Cloud & AI Infrastructure zone to see how high-fidelity monitoring transforms your infrastructure operations.

February 3, 2026
Join Netdata as a Silver Partner at the 10th Edition India DevOps Show on February 13, 2026 in Bengaluru. Discover how high-fidelity, real-time monitoring empowers DevOps teams to move faster with confidence.