See Every Container Heartbeat in Real Time
Monitor Docker containers, Kubernetes pods, and microservices with per-second precision. Zero configuration, instant insights, and 90% lower costs than traditional monitoring.

Monitor Docker containers, Kubernetes pods, and microservices with per-second precision. Zero configuration, instant insights, and 90% lower costs than traditional monitoring.
Everything you need for Docker and Kubernetes observability
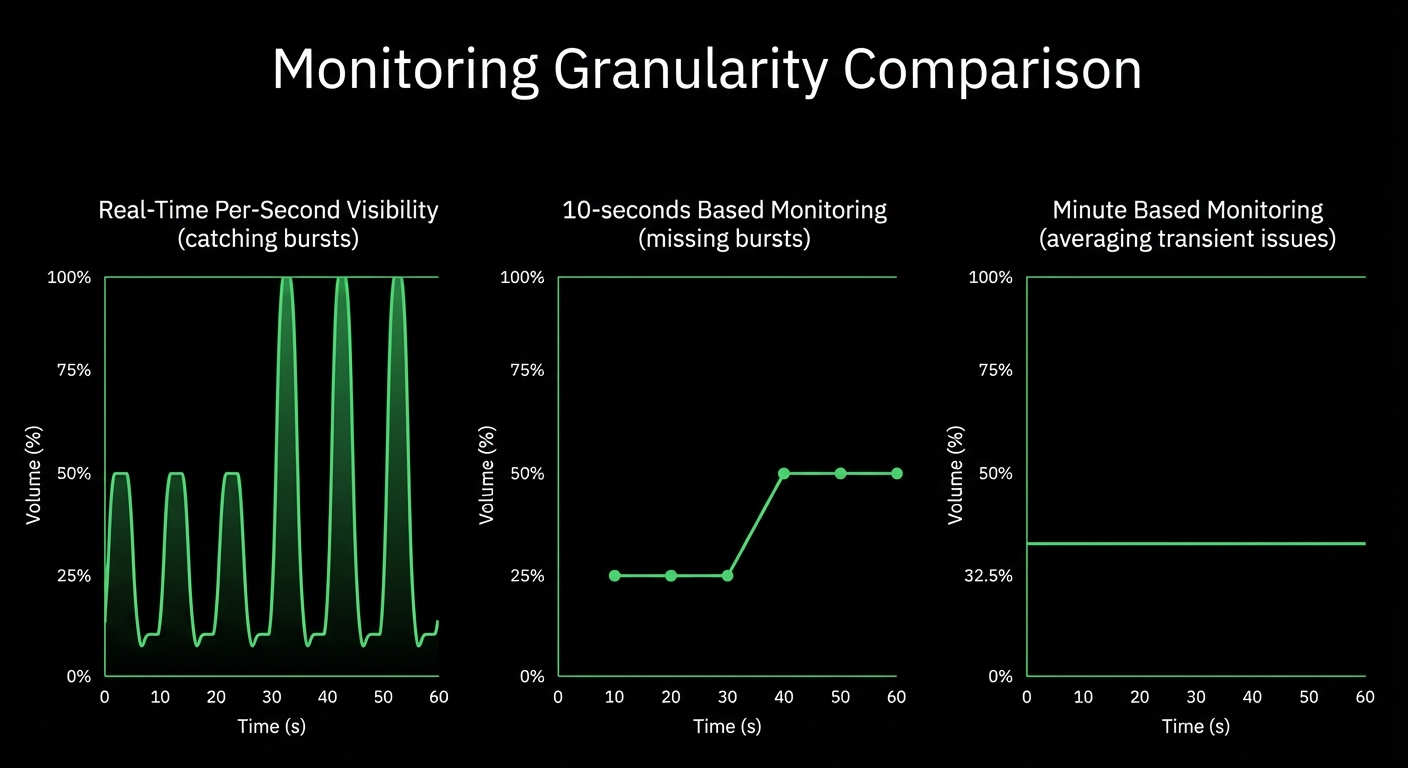
Catch microbursts and transient spikes invisible to 30-second monitoring. See what’s actually happening, not averaged approximations.
Auto-discovers containers, generates dashboards, and configures alerts in under 60 seconds. No YAML, no PromQL, no manual setup.
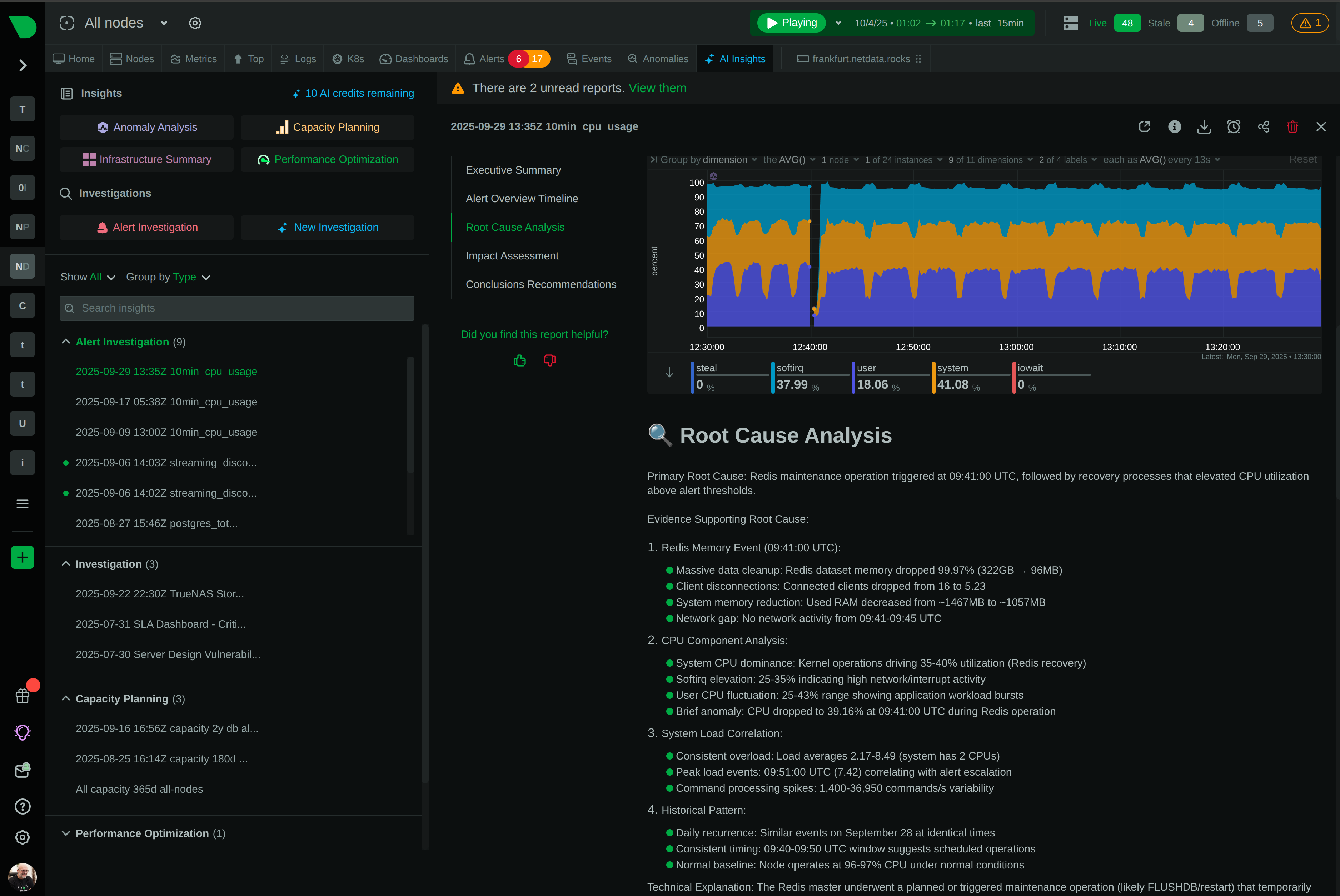
18 models per metric detect issues automatically with 99% false positive reduction. Unsupervised learning requires no configuration.
Pay per node, not per container or metric. Unlimited containers, unlimited metrics, unlimited logs - 90% cost reduction validated.
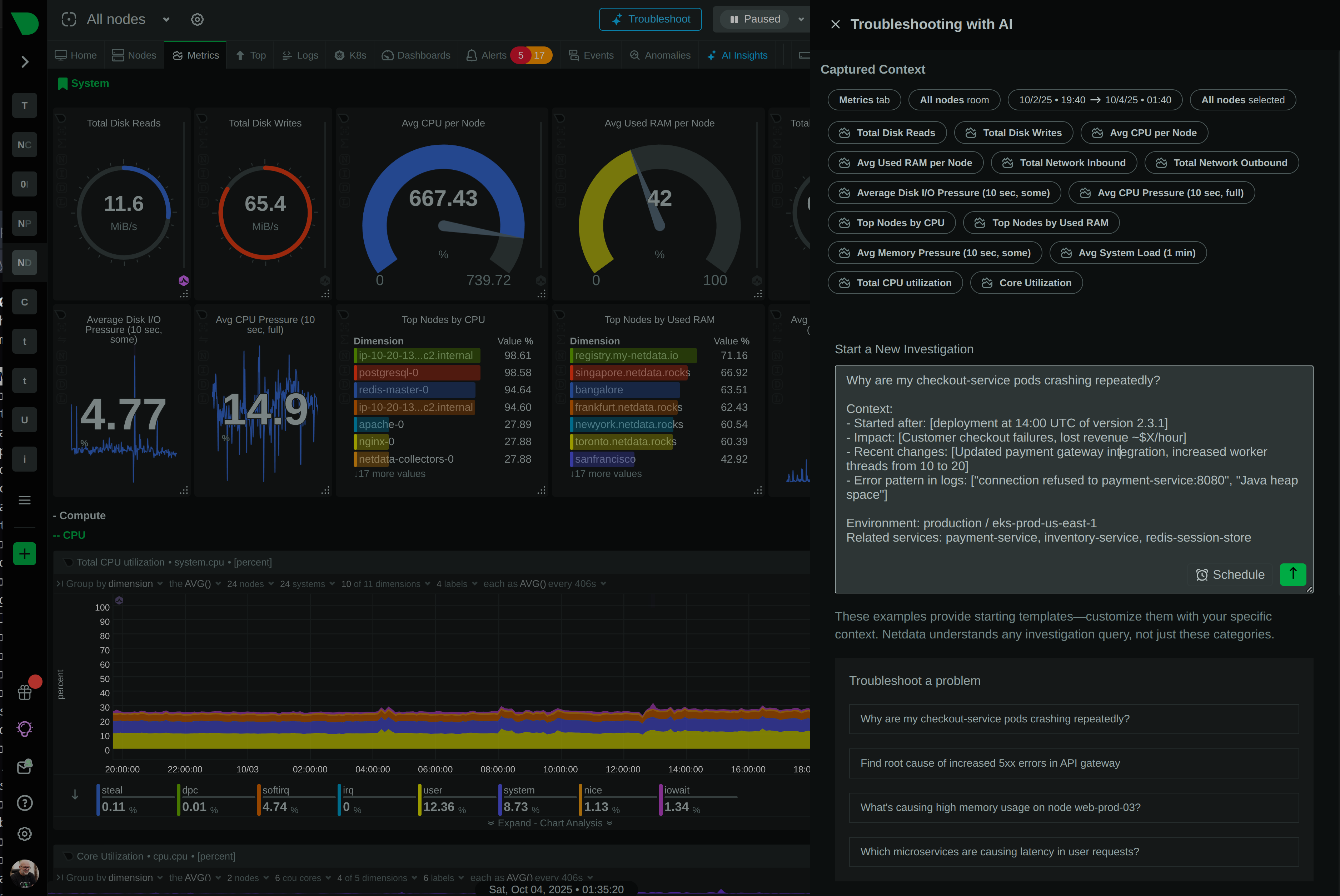
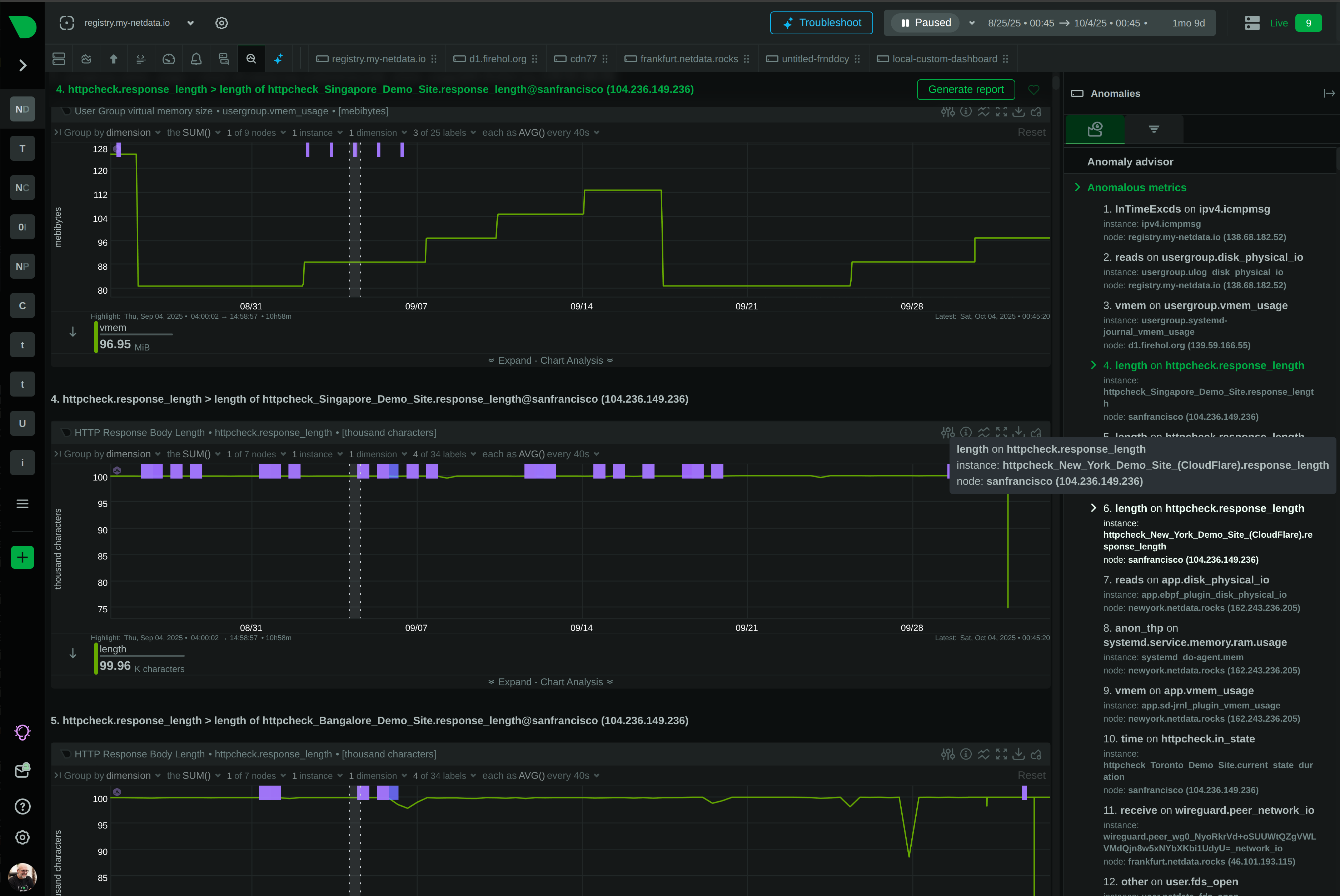
Anomaly Advisor correlates thousands of metrics to surface the top 30-50 causing issues. Find problems in seconds, not hours.
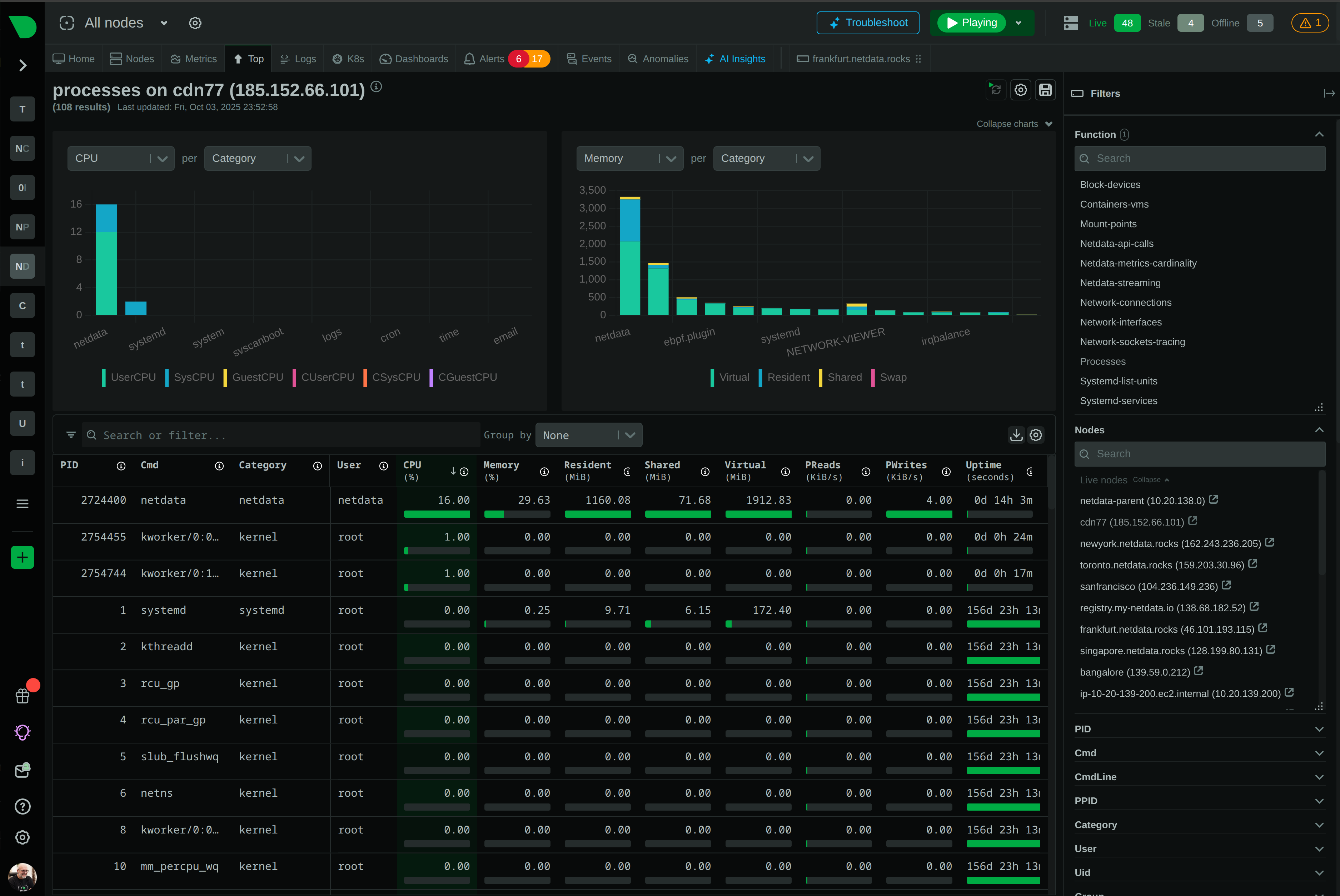
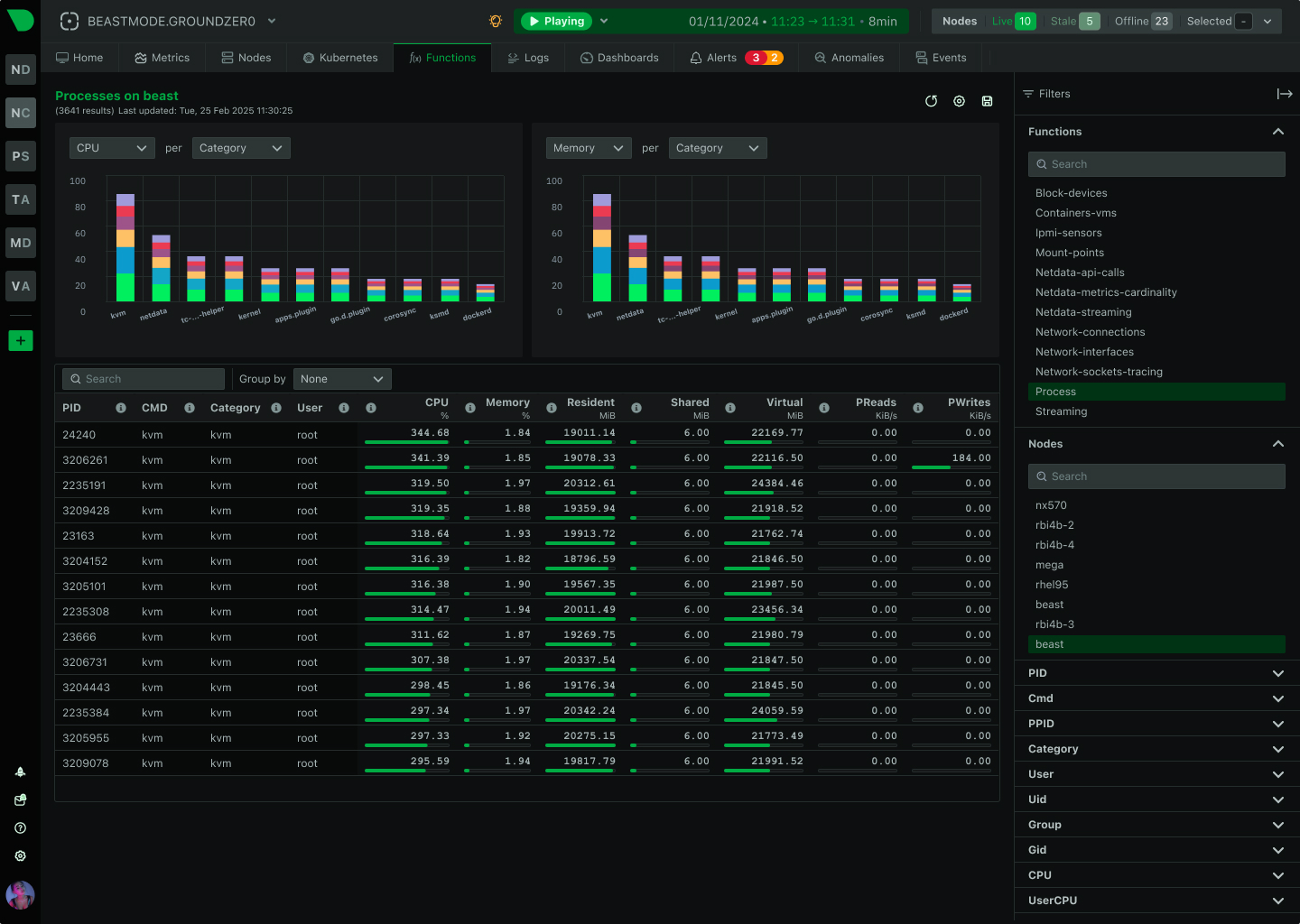
Debug containers without SSH. Get top, iostat, netstat equivalents in your browser - with history and ML insights included.
Trusted by DevOps teams worldwide
Per-second granularity
Learn about real-time monitoring
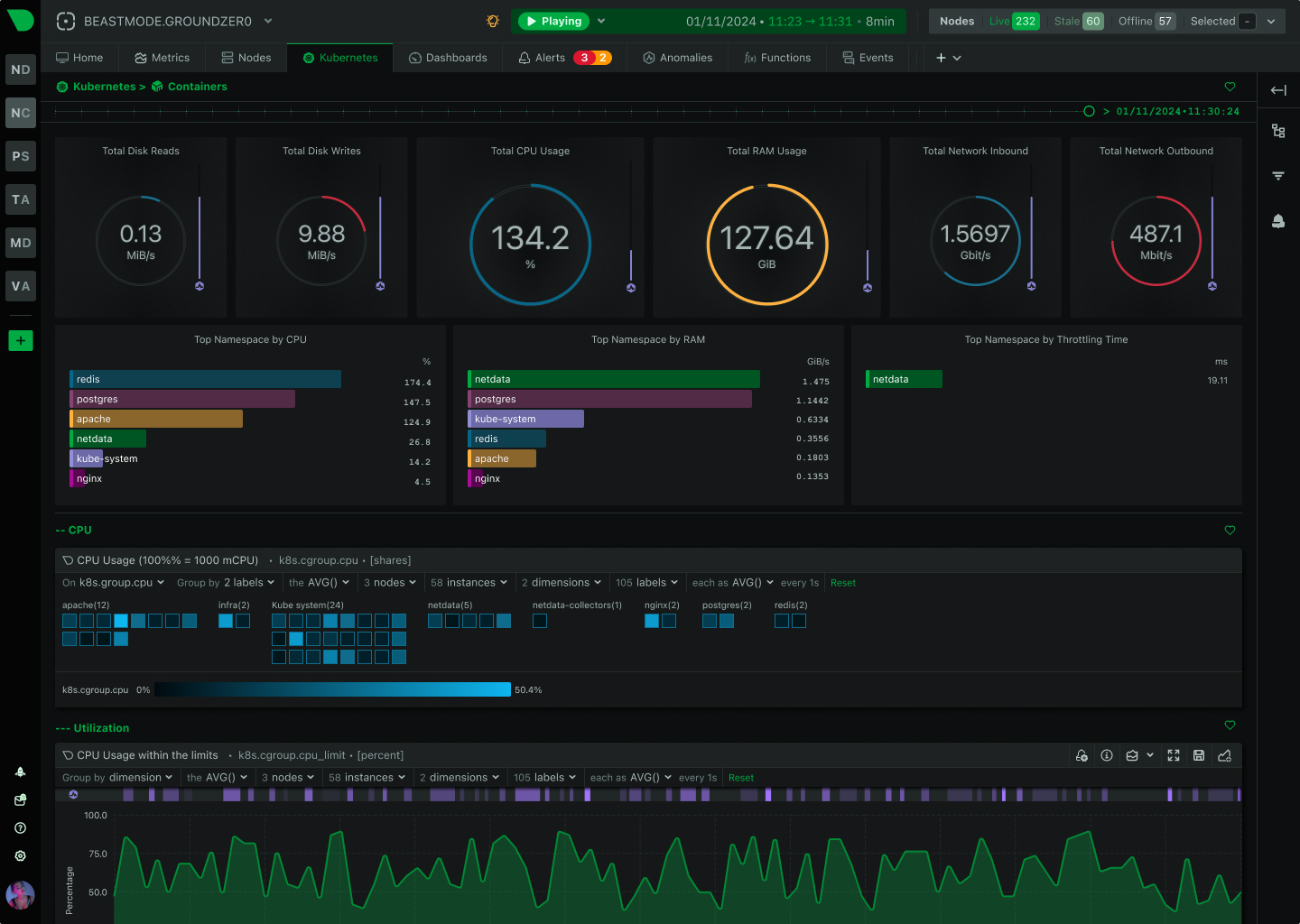
Console replacement
Explore Netdata Functions
90% cost reduction
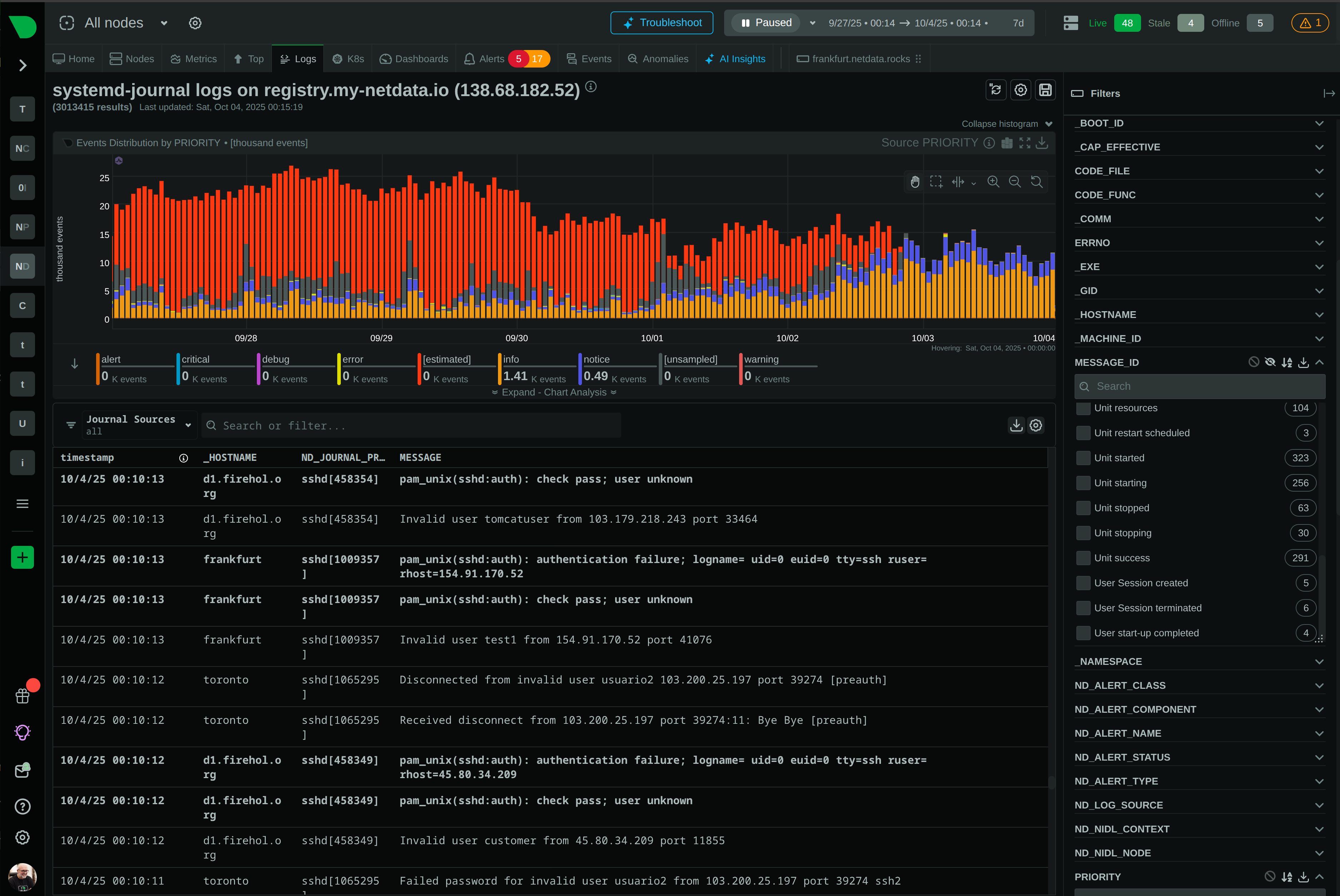
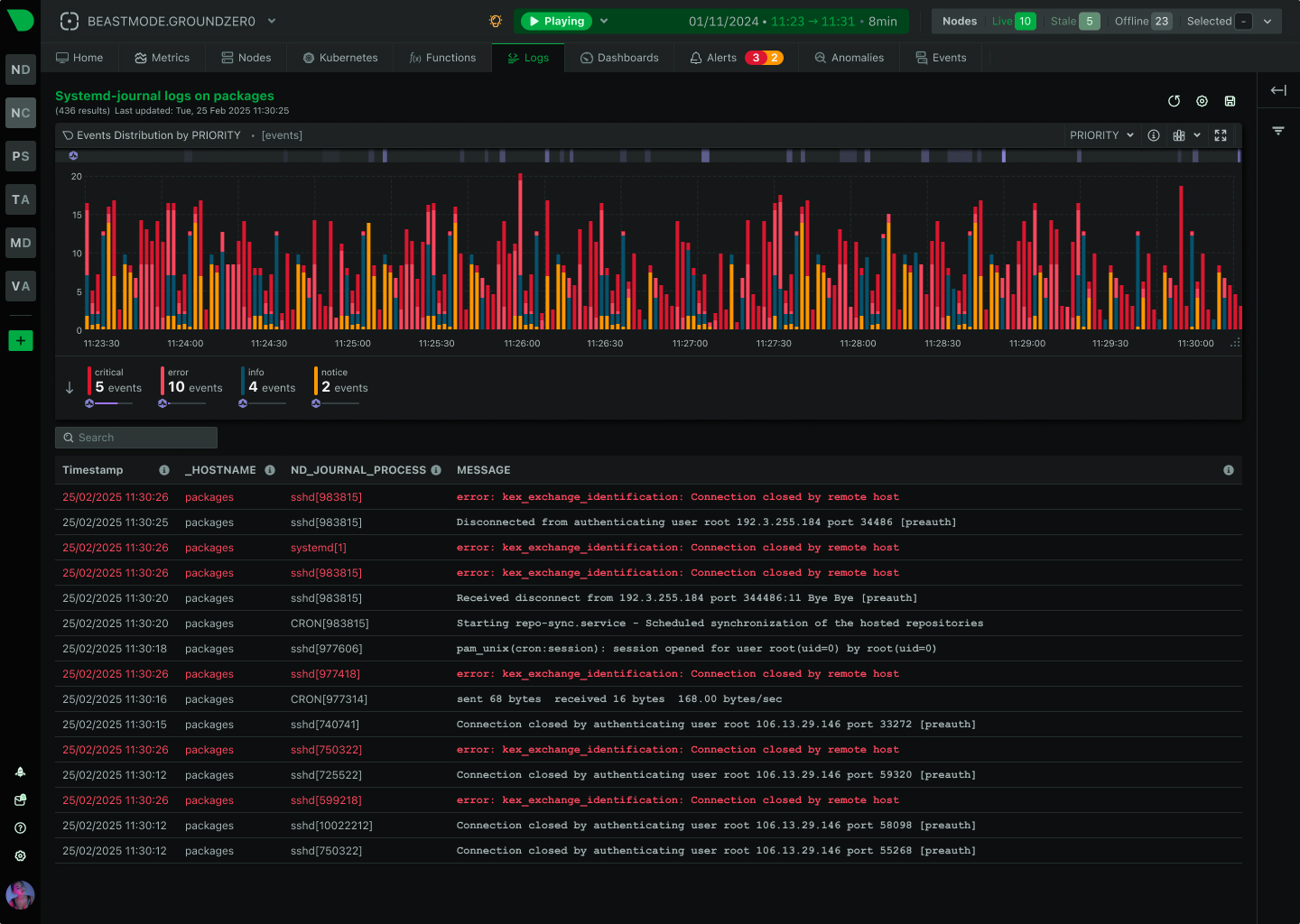
Discover zero-pipeline logs
99% false positive reduction
Learn about ML anomaly detection
100,000+ nodes
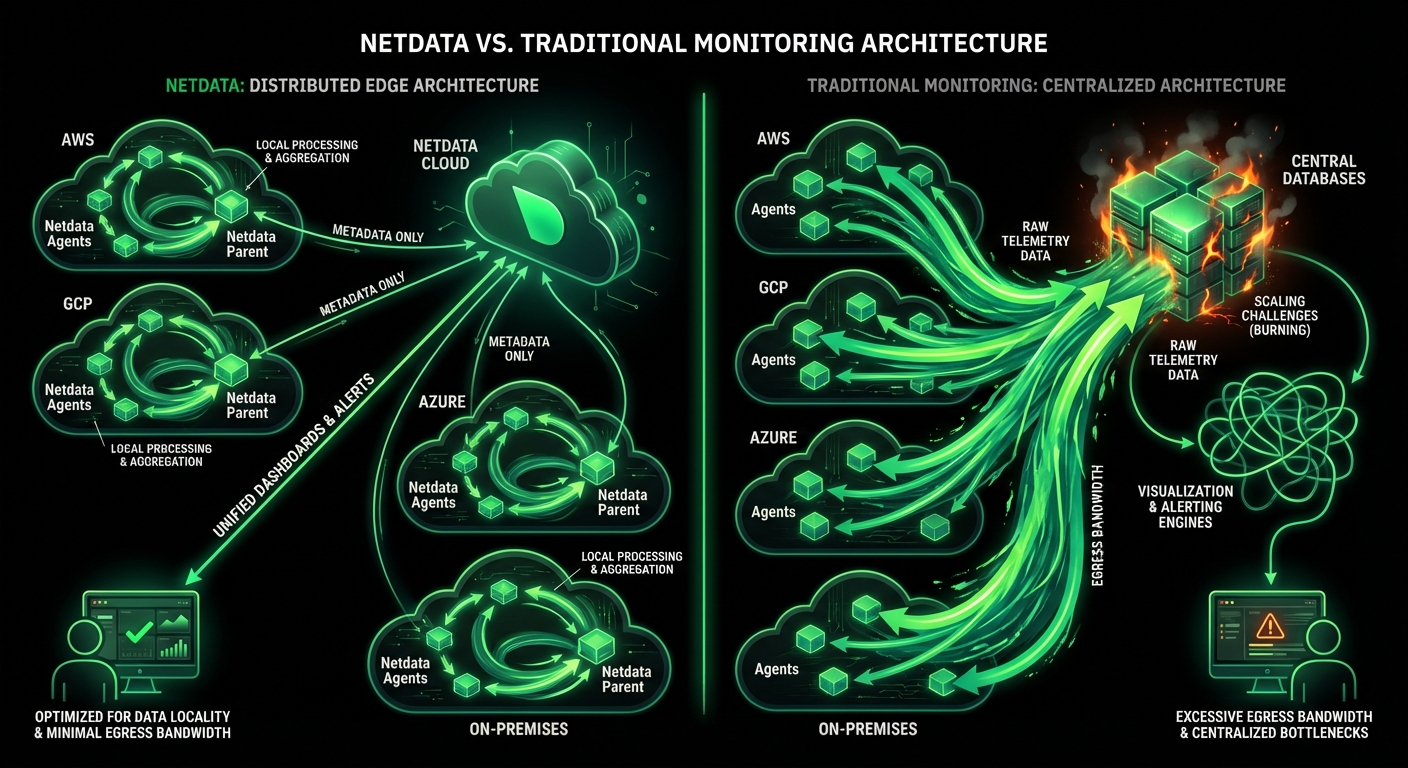
Understand distributed architecture
60-second deployment
Deploy on Kubernetes

Why Teams Choose Netdata
Traditional monitoring tools weren’t built for containers. Netdata was designed from day one for ephemeral, high-cardinality, dynamic environments.
Capability
Netdata
Traditional Monitoring
Data Granularity
✅ Per-second
Catch transient spikes and microbursts
⚠️ 10-60 seconds
Miss 90% of short-lived issues
Setup Time
✅ Under 60 seconds
Auto-discovery, auto-dashboards, auto-alerts
⚠️ Days to weeks
Manual configuration, dashboard building
Container Discovery
✅ Automatic
Docker, Kubernetes, Podman, containerd
⚠️ Manual registration
Requires configuration per container
Pricing Model
✅ Predictable per-node
Unlimited containers, metrics, logs
❌ Per-container or per-metric
Costs multiply with scale
Cardinality Handling
✅ Unlimited
Distributed storage, no bottlenecks
❌ Limited
Central aggregation causes explosions
ML Anomaly Detection
✅ Every metric, edge-based
99% false positive reduction
⚠️ Selected metrics, cloud-based
High false positive rates
Log Management
✅ Zero-pipeline
Direct journal access, 90% cost reduction
❌ Expensive pipelines
ELK/Splunk infrastructure required
Query Language
✅ None required
Point-and-click NIDL framework
⚠️ PromQL/SQL required
Steep learning curve
Resource Overhead
✅ <5% CPU, 150-200 MB RAM
Most energy-efficient (validated)
⚠️ 10-30% CPU overhead
Significant performance impact
Troubleshooting
✅ Browser-based console
SSH replacement with history
⚠️ SSH required
Manual console tool usage
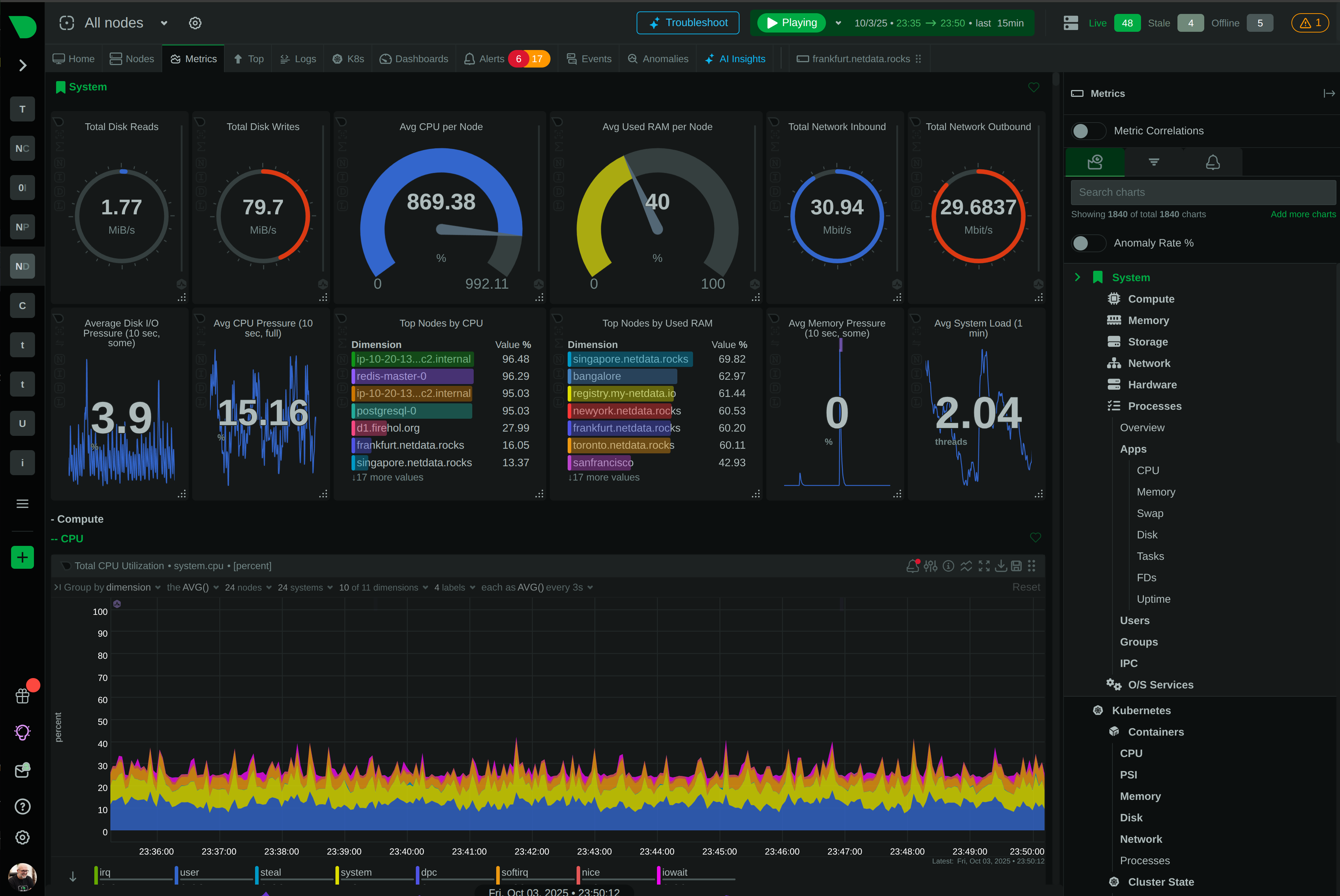
CPU usage, throttling, memory consumption, OOM events, network bandwidth, packet errors, disk I/O, and container lifecycle - all per-second with zero configuration.
Per-second precision
Explore container metricsReal results from organizations monitoring containers at scale
Per-second granularity reveals transient spikes and microbursts that 30-second monitoring completely misses. See what’s actually happening, not averaged approximations.
Pay per node, not per container or metric. Unlimited containers, unlimited metrics, unlimited logs - 90% cost reduction compared to traditional monitoring.
Auto-discovers containers, generates dashboards, and configures alerts automatically. No YAML, no PromQL, no manual setup required.
ML-based anomaly detection uses 18 models per metric requiring unanimous agreement. Detect real issues while ignoring noise in your metrics.
Anomaly Advisor correlates thousands of metrics to surface the top 30-50 causing issues. Reduce MTTR by 80% with instant root cause identification.
Browser-based console replacement provides process monitoring, network connections, and logs - all with history and ML insights included.
Distributed architecture eliminates cardinality bottlenecks. Proven at 100,000+ nodes processing 4.5+ billion metrics per second globally.
Zero-pipeline log management queries systemd-journal directly. Correlate logs with metrics instantly, reduce log costs by 90%.
Deploy via Helm chart with automatic DaemonSet architecture. Monitor nodes, pods, containers, and cluster resources with zero configuration.

May 20, 2022
Learn how to monitor Kubernetes workloads without direct cooperation from applications. Gain insights with zero-code changes. Read the full guide now!

May 3, 2022
Solve Kubernetes throttling issues with real-time monitoring and smarter resource management. Learn how to optimize performance—read the guide now!

May 5, 2021
Master Kubernetes monitoring and troubleshooting with Netdata. Gain real-time insights, detect issues faster & optimize performance. Start monitoring now!