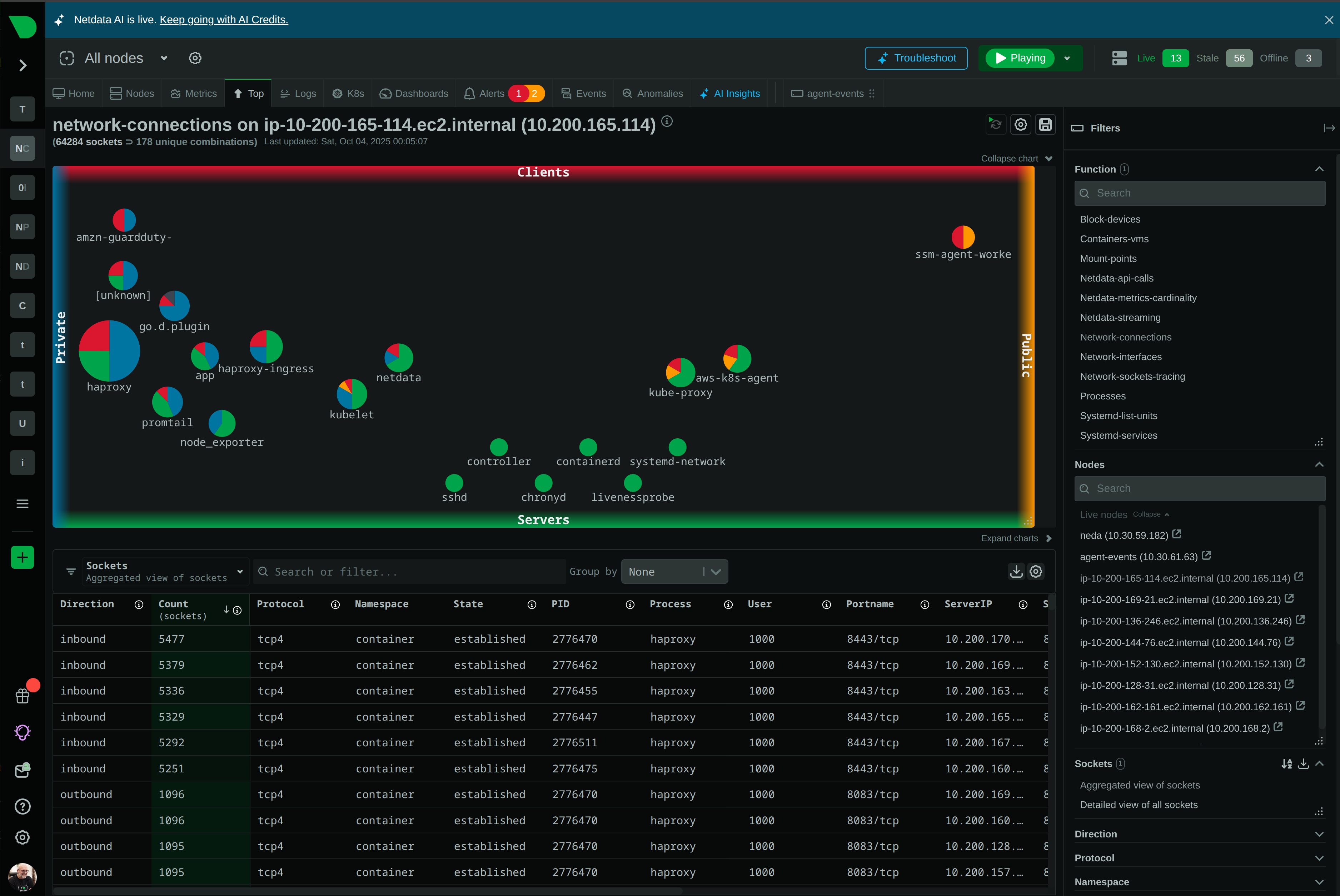
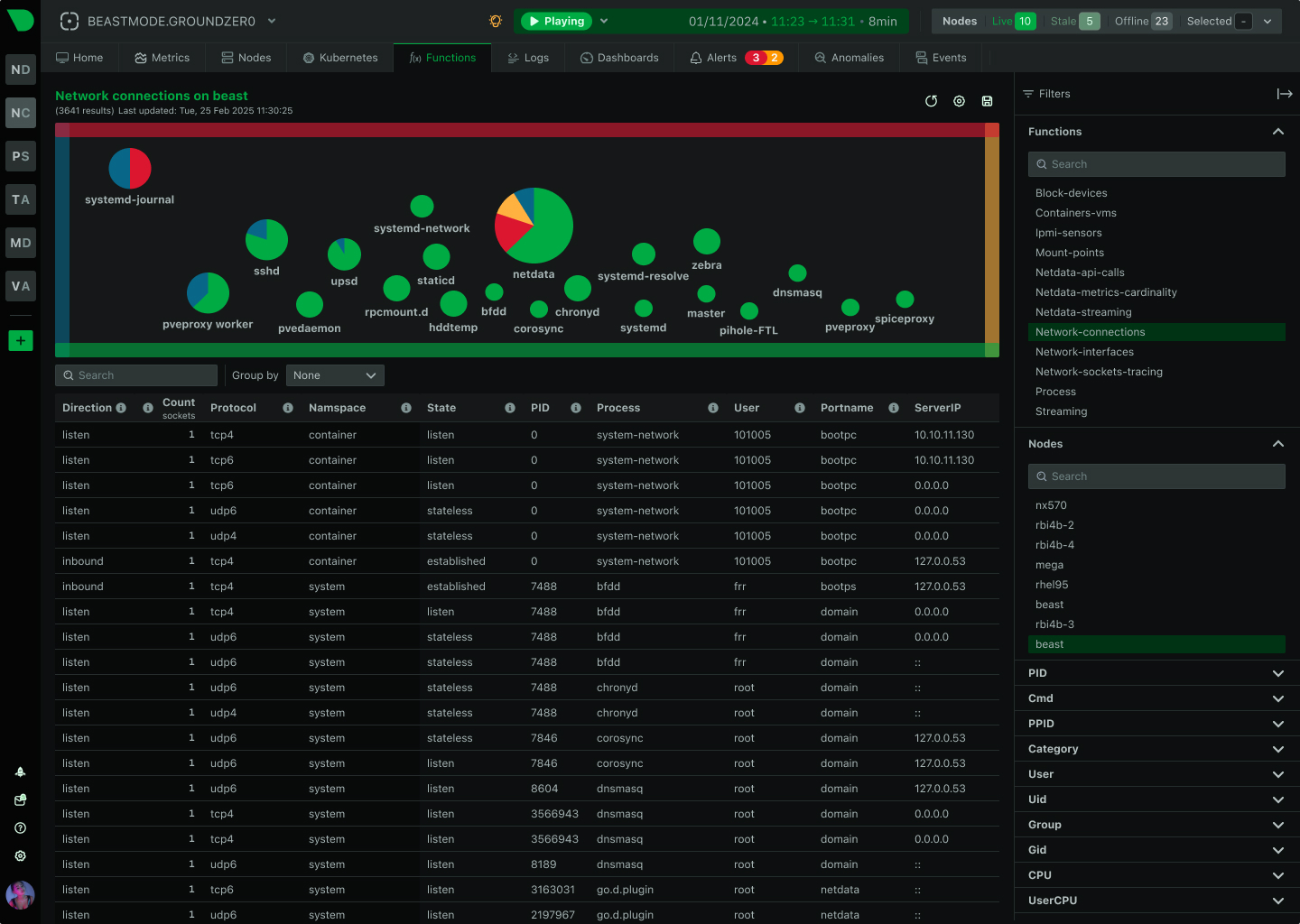
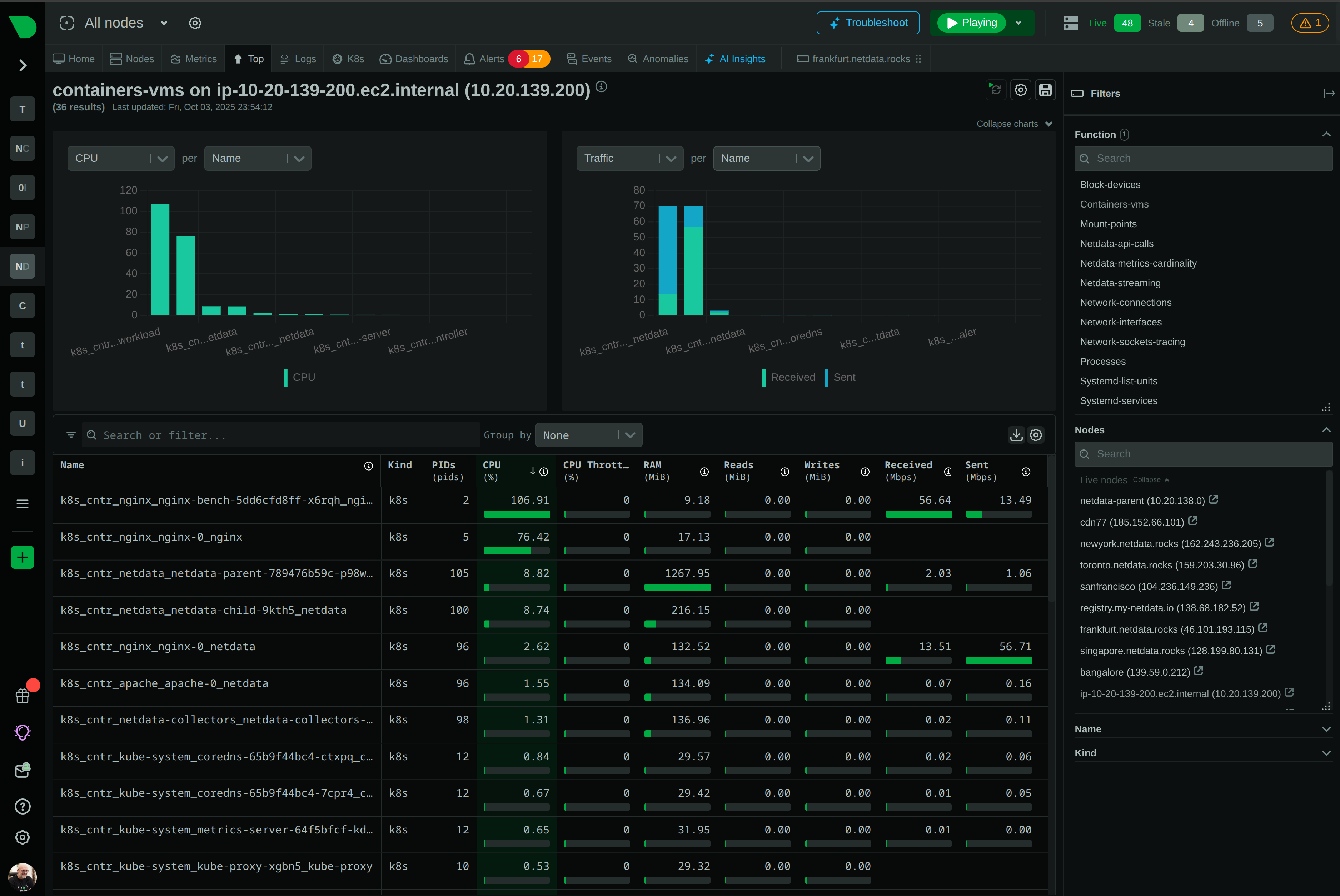
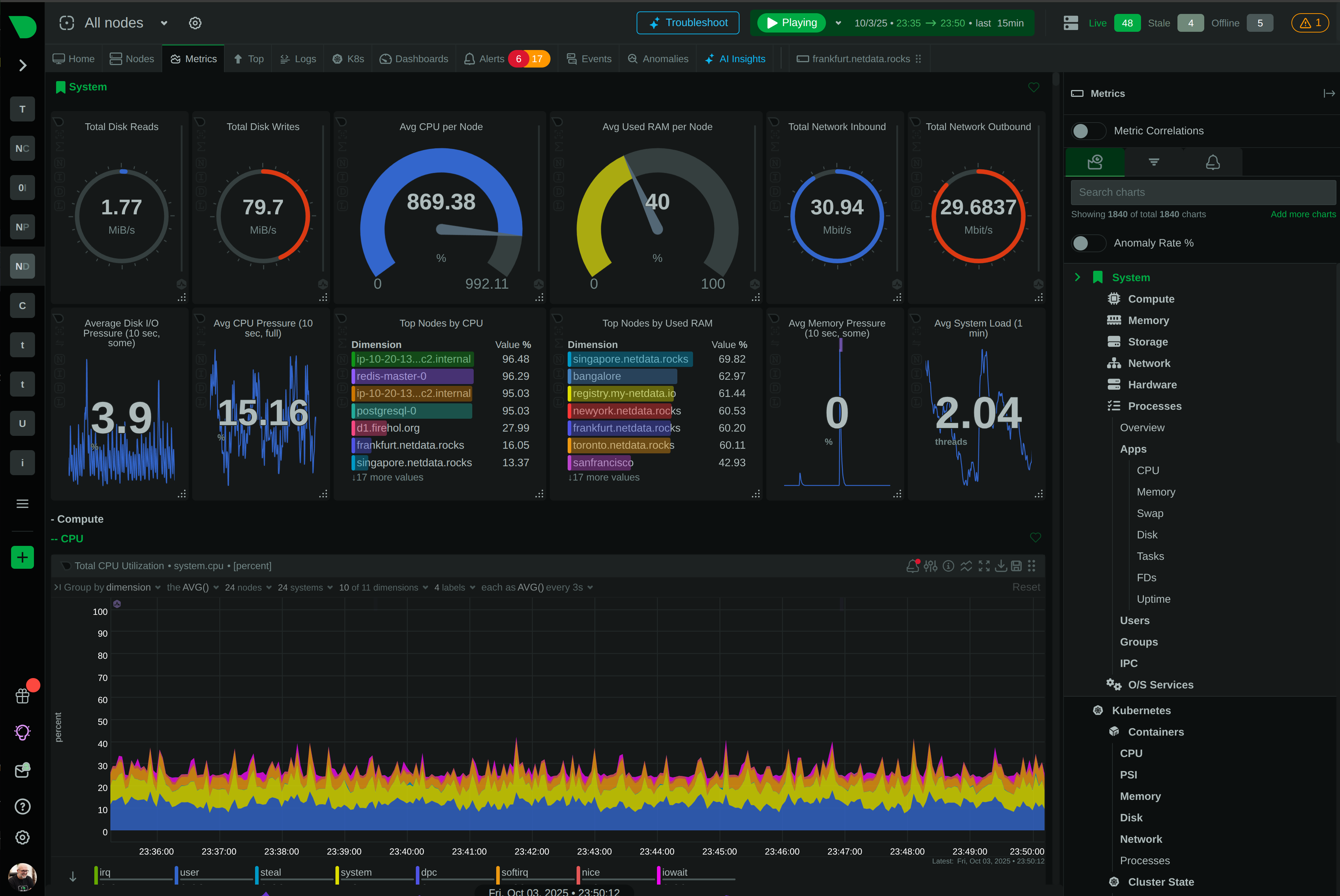
See Every Microsecond That Matters in Your HPC Infrastructure
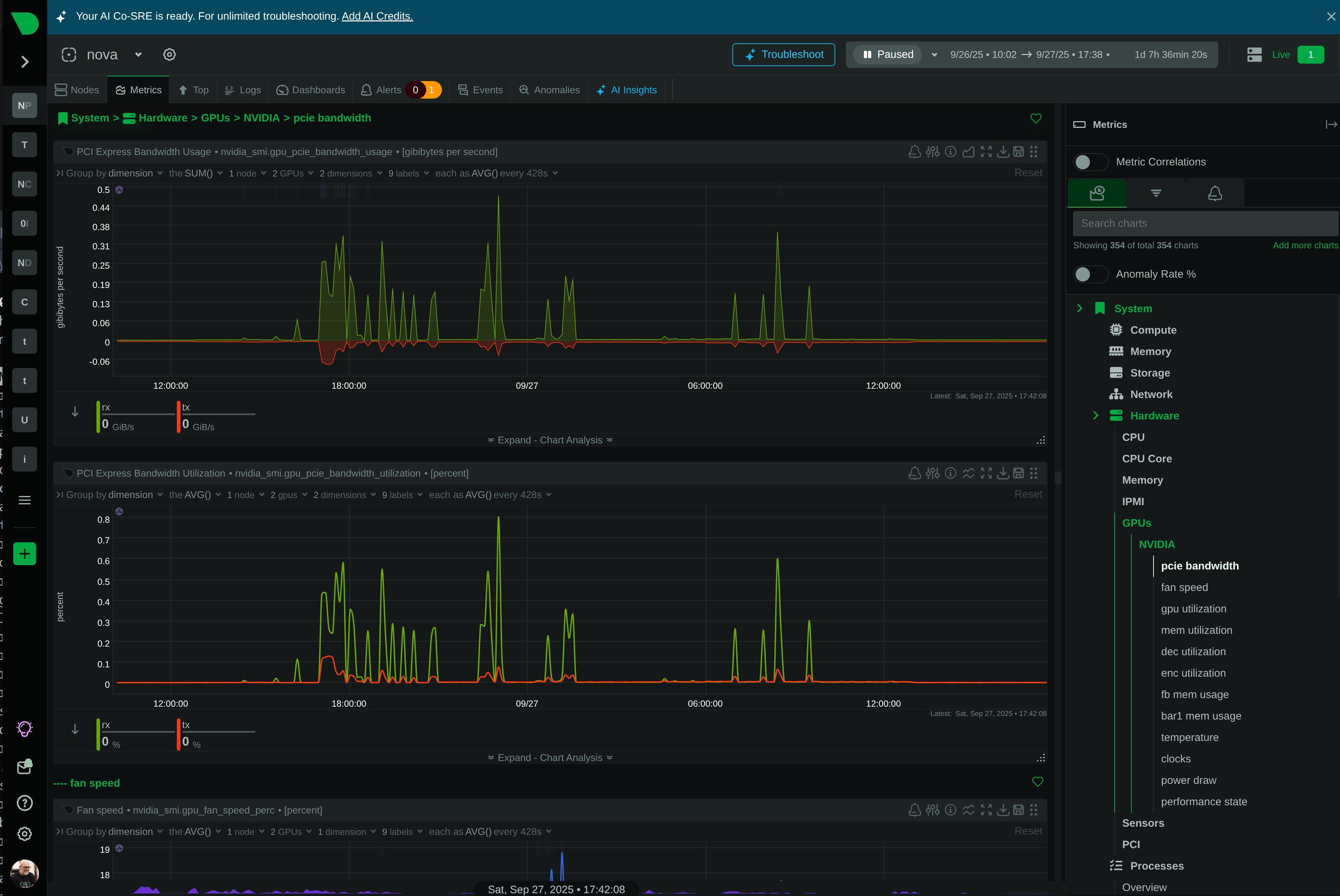
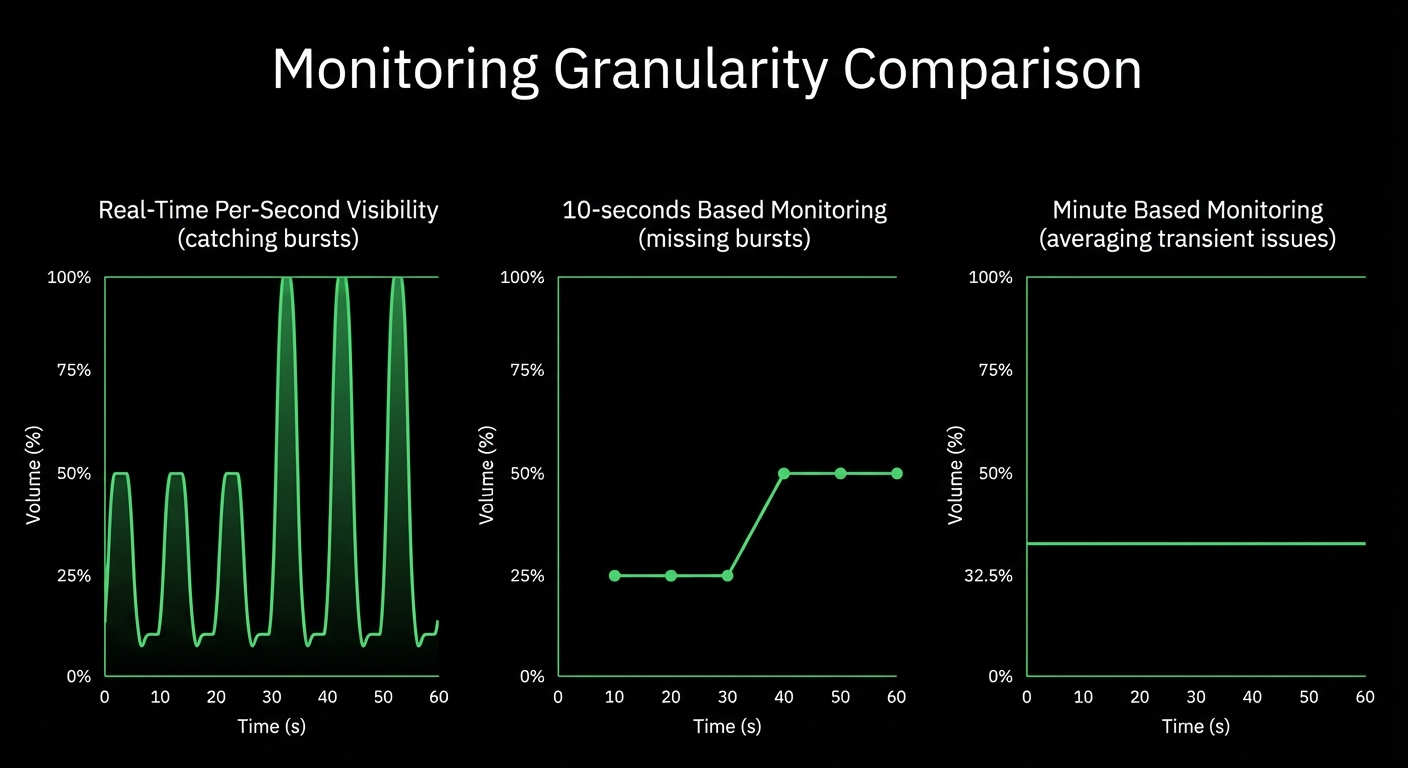
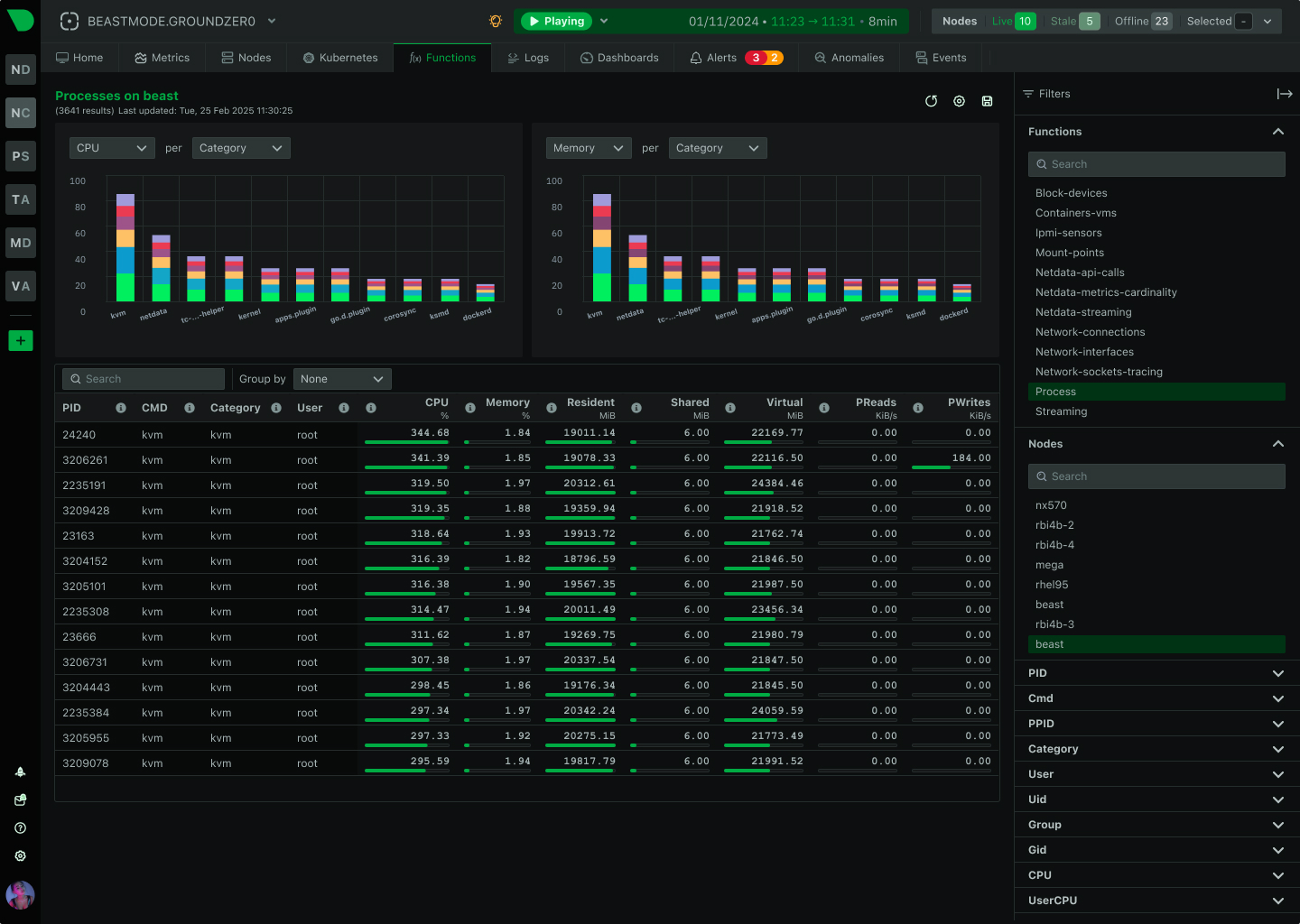
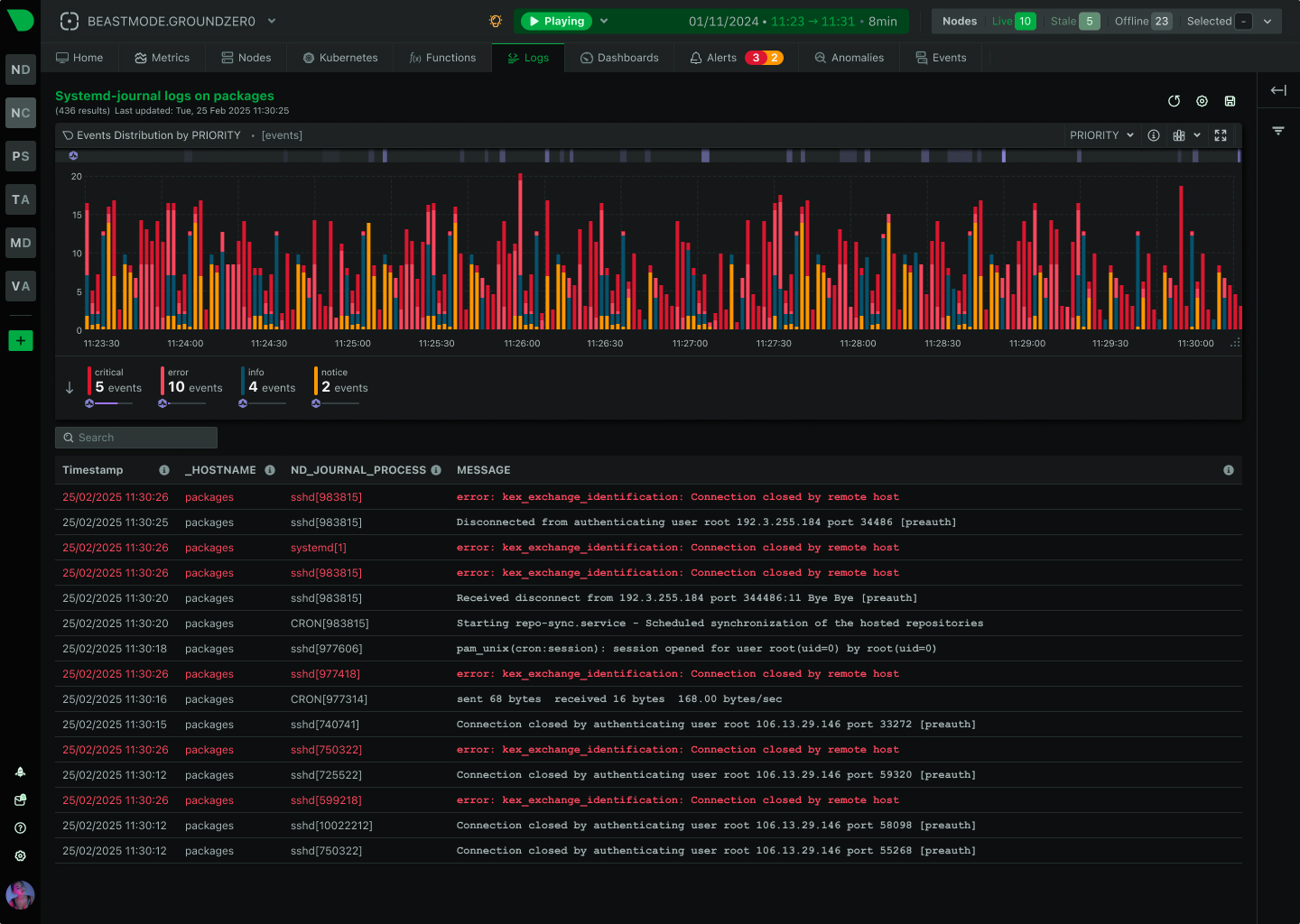
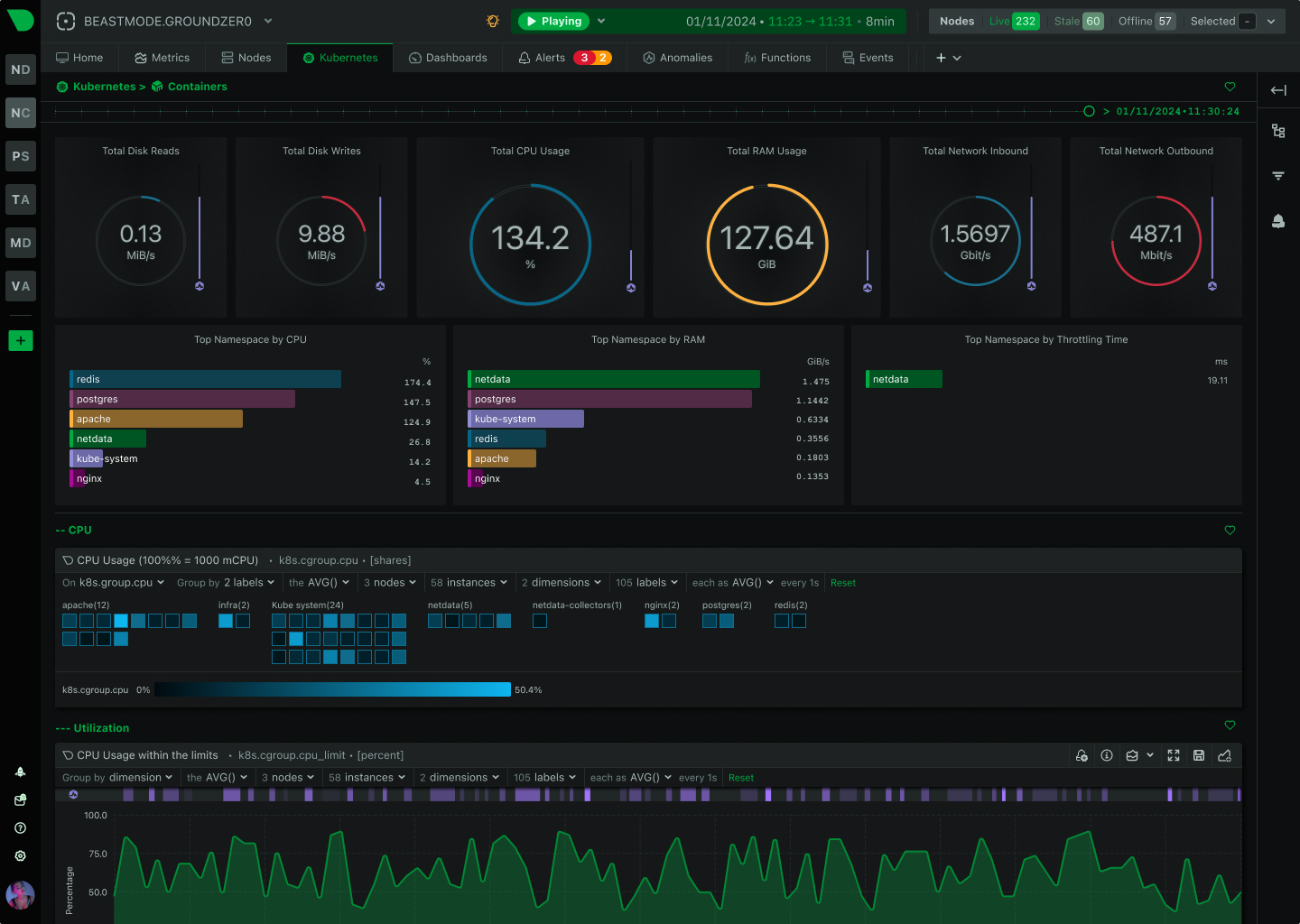
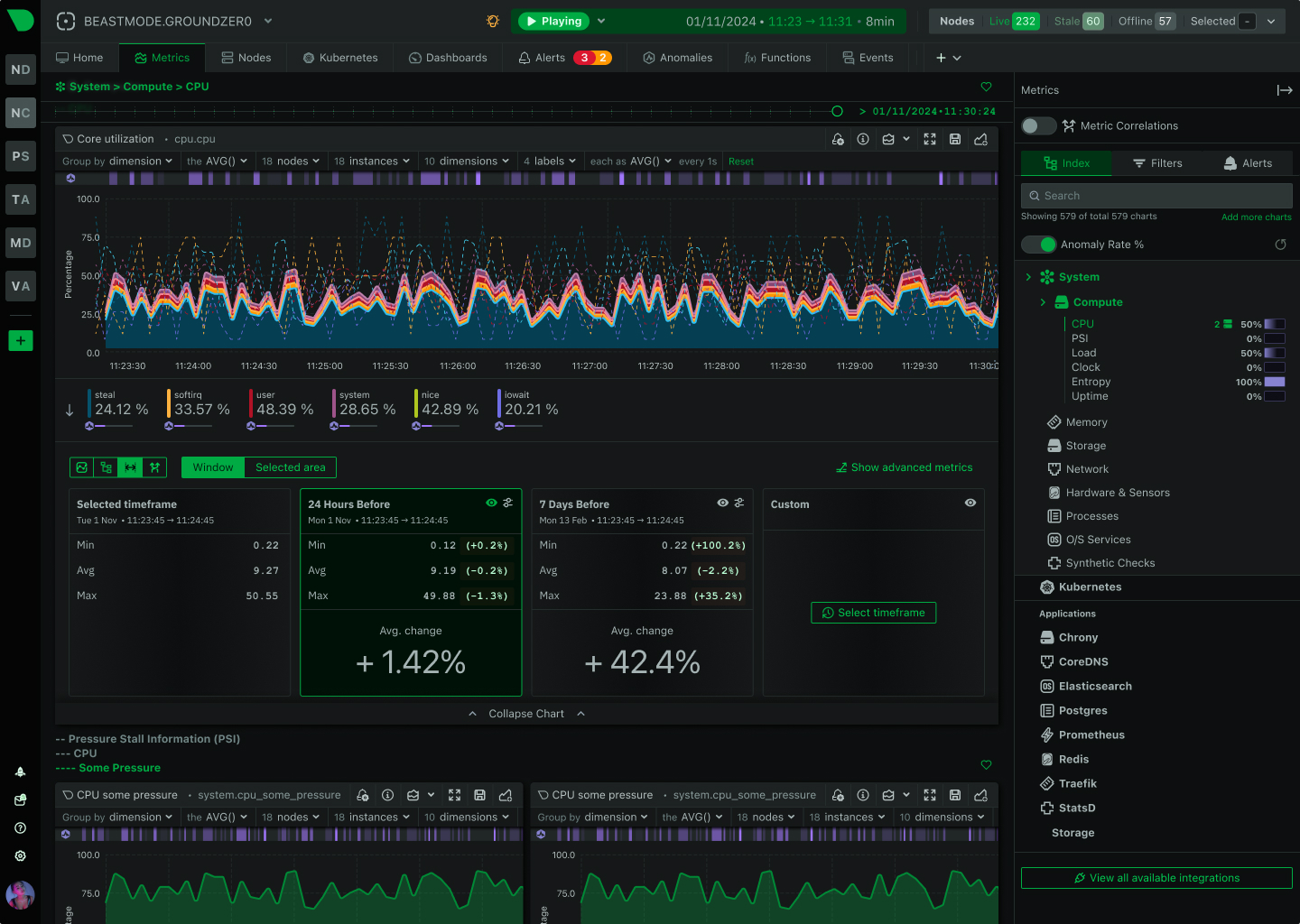
Traditional monitoring misses 90% of HPC incidents because they happen in seconds, not minutes. Netdata’s per-second granularity captures GPU throttling, memory bursts, and network microbursts as they occur - giving your team the visibility to prevent cascading failures before they impact research outcomes.