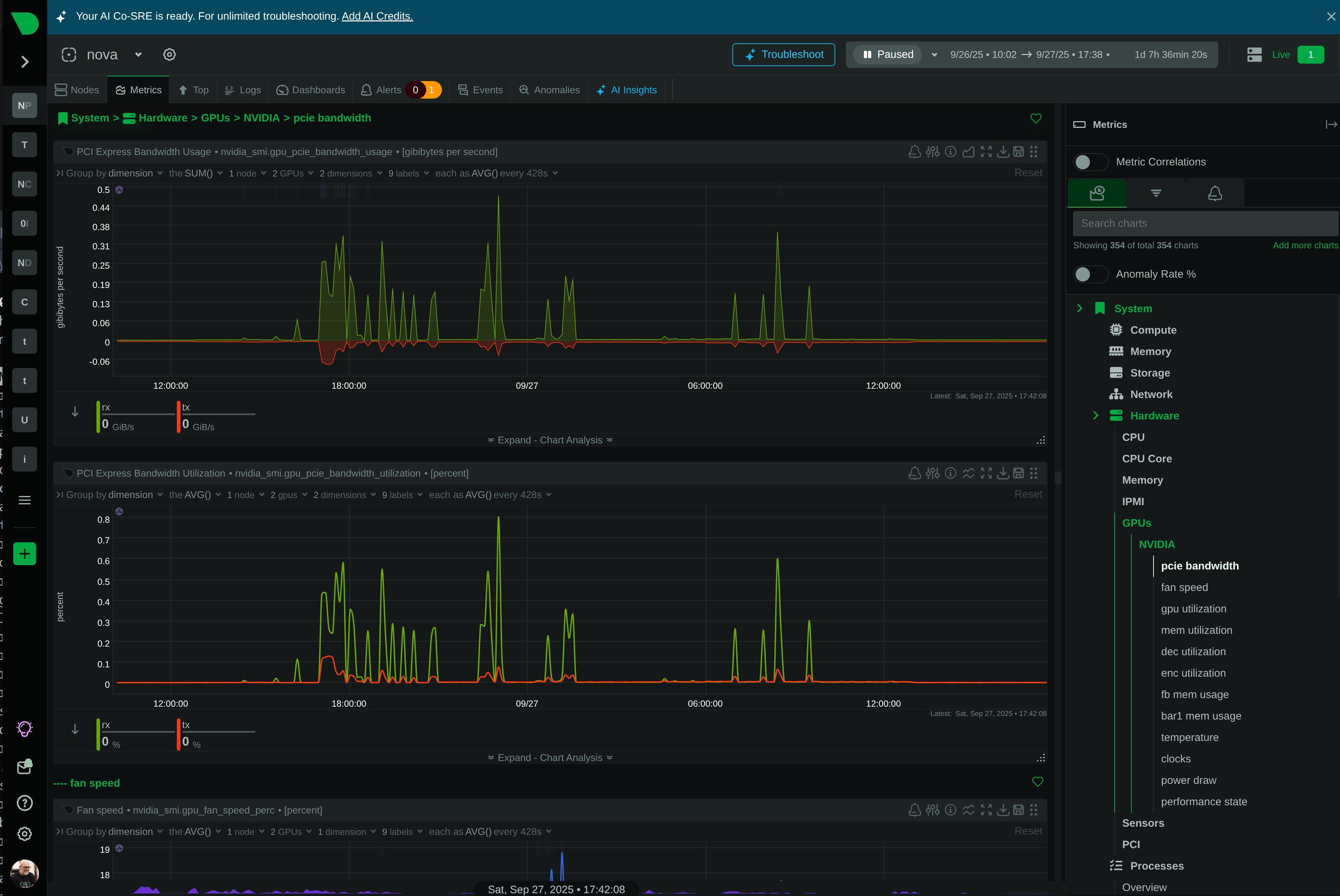
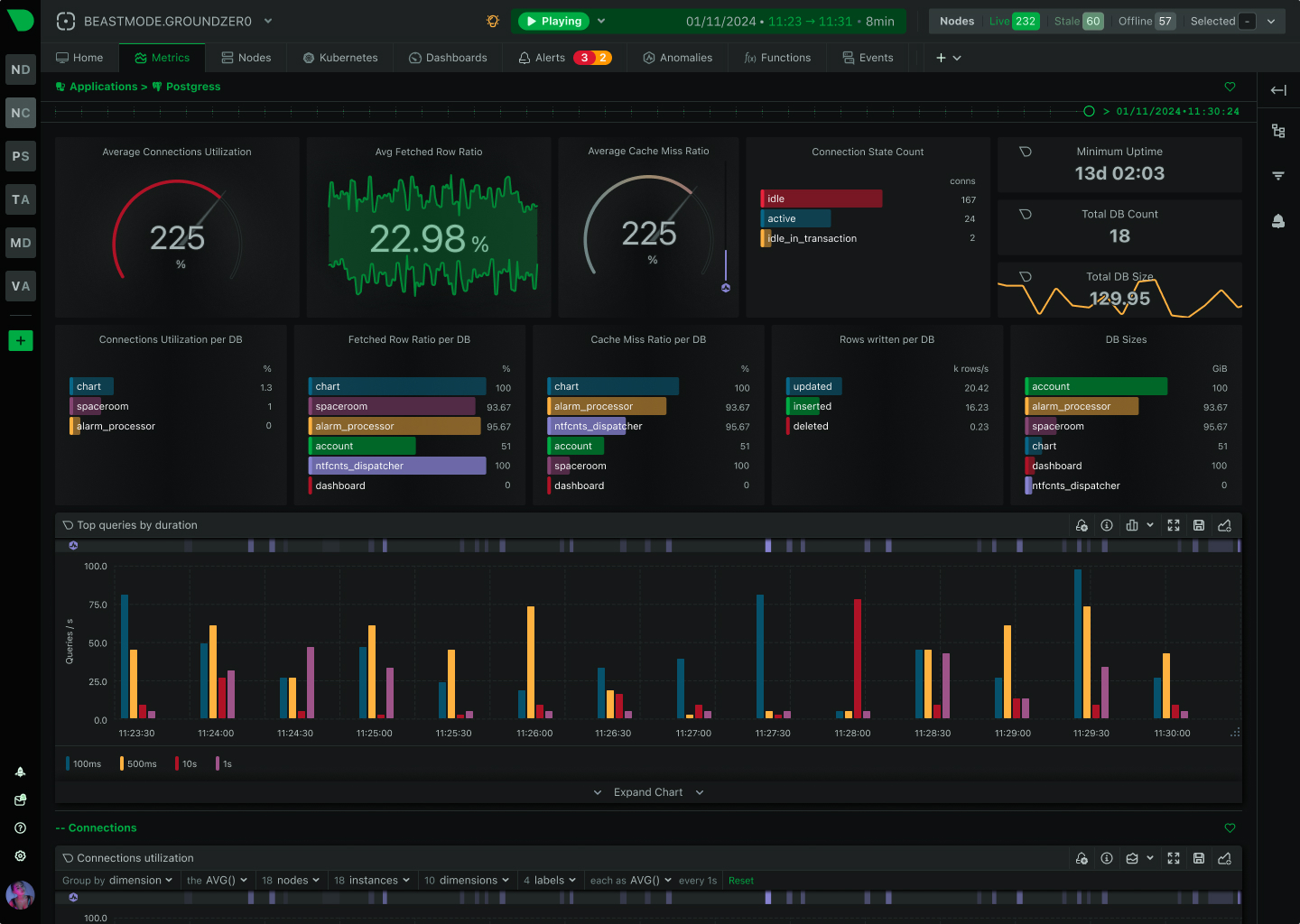
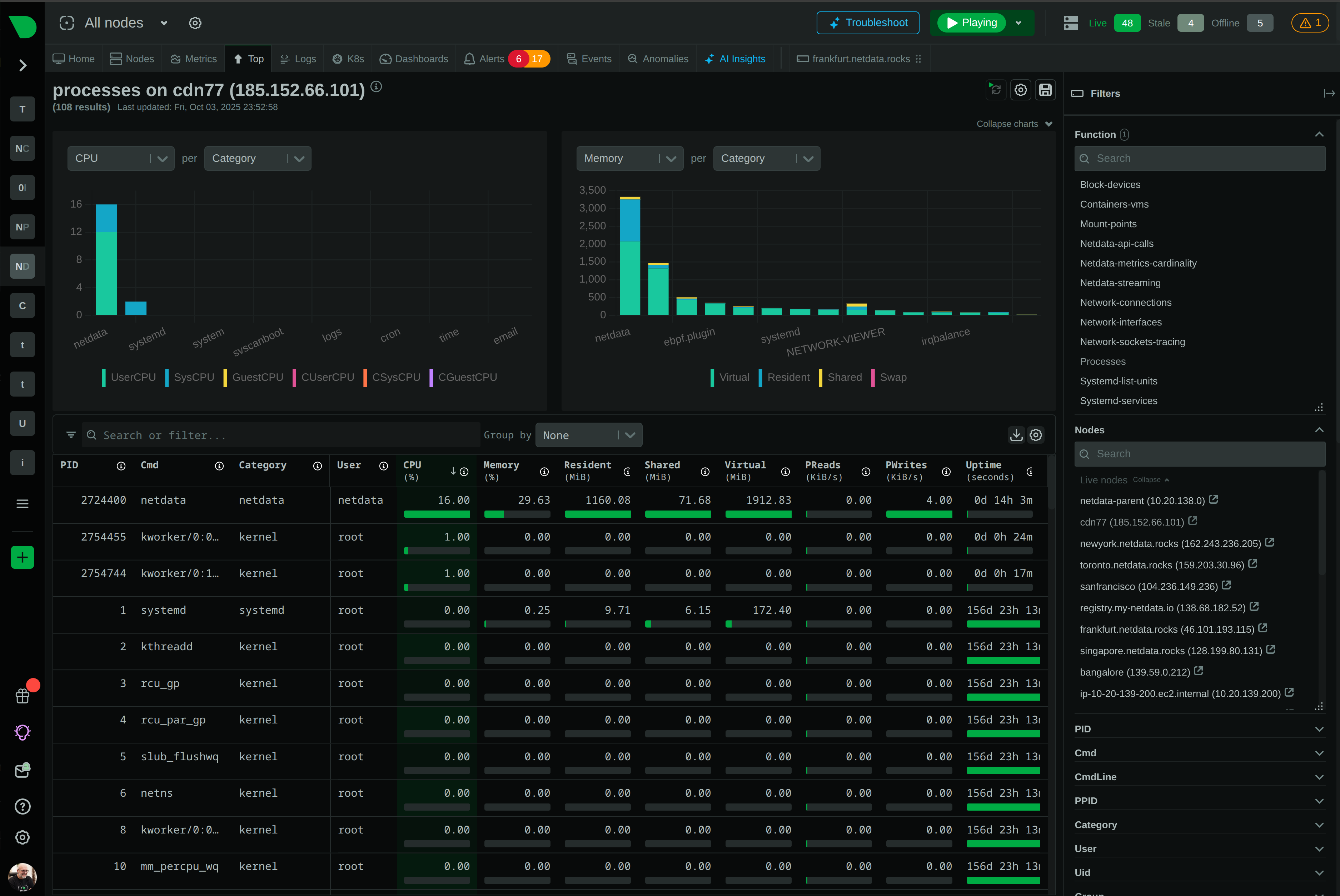
Keep Your LLM Infrastructure Running at Peak Performance
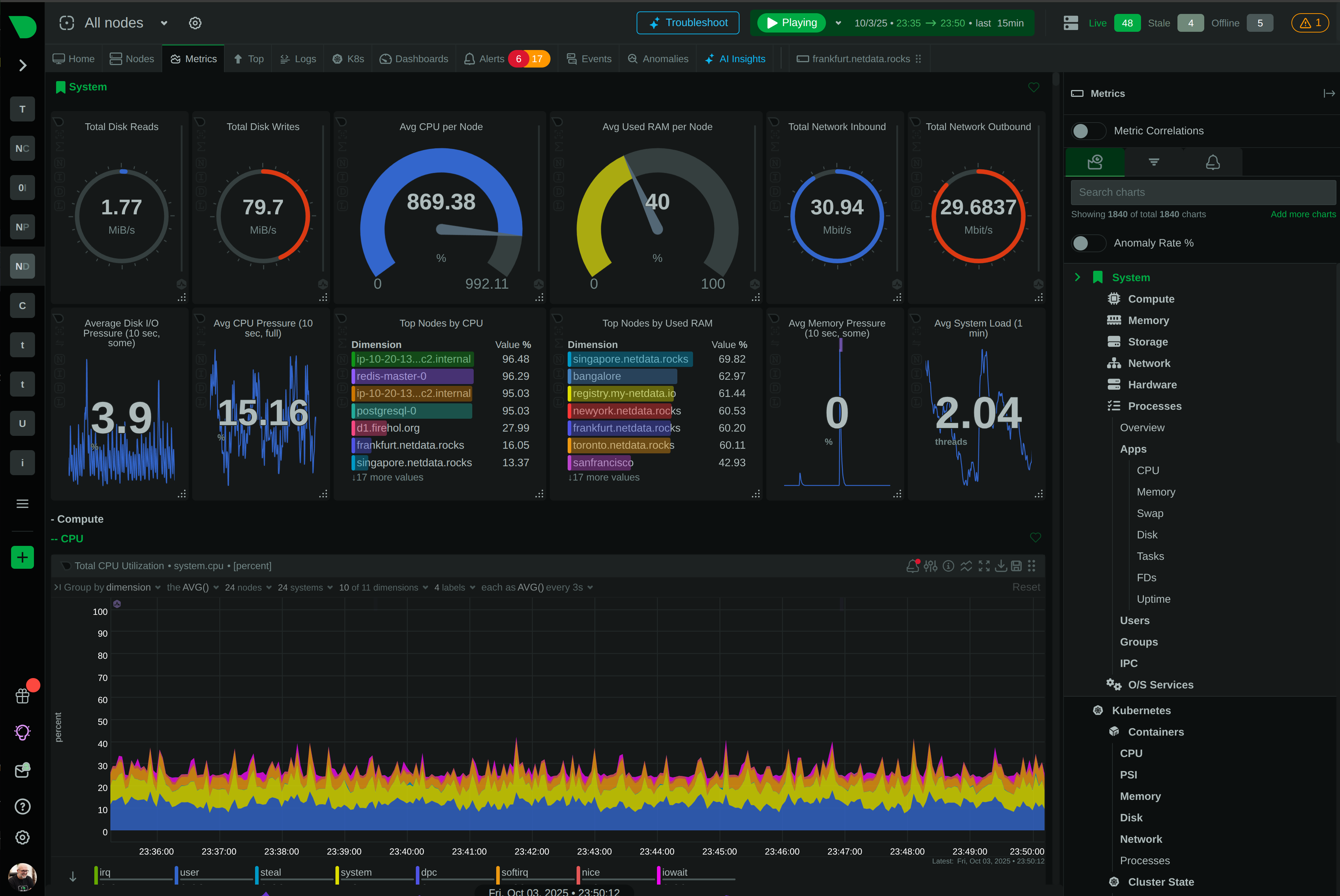
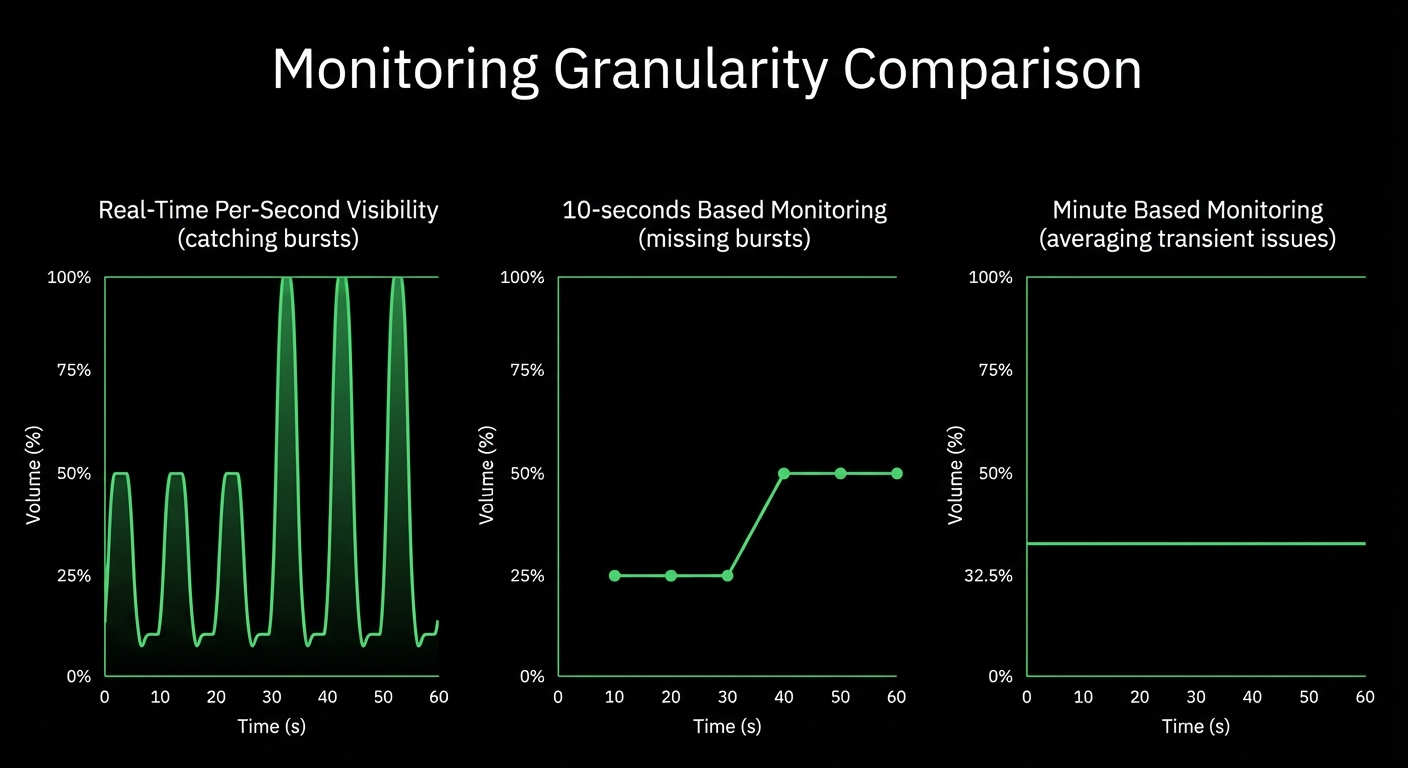
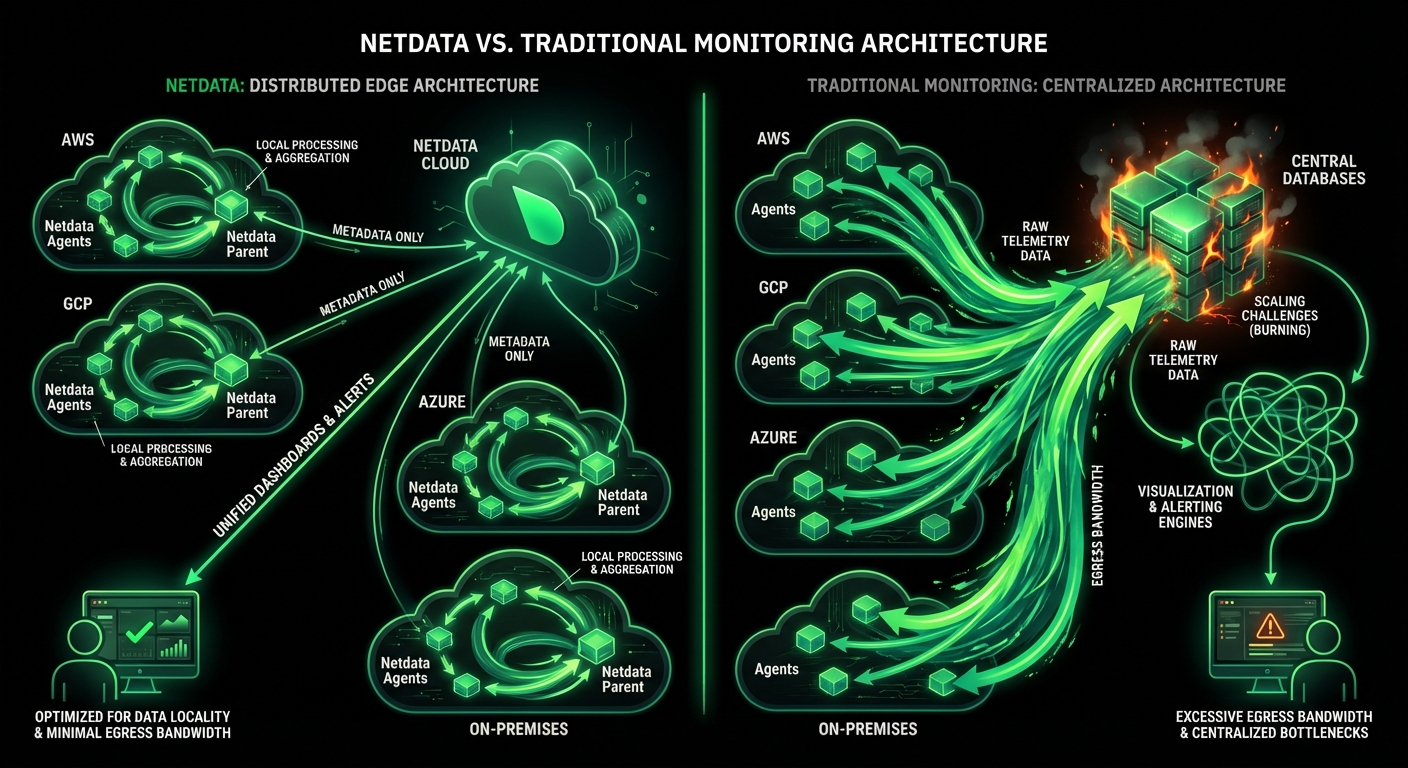
Monitor the infrastructure powering your LLM applications with per-second visibility into GPUs, containers, databases, and system resources. Detect bottlenecks before they impact inference latency, optimize resource utilization, and reduce cloud costs - all with zero configuration.