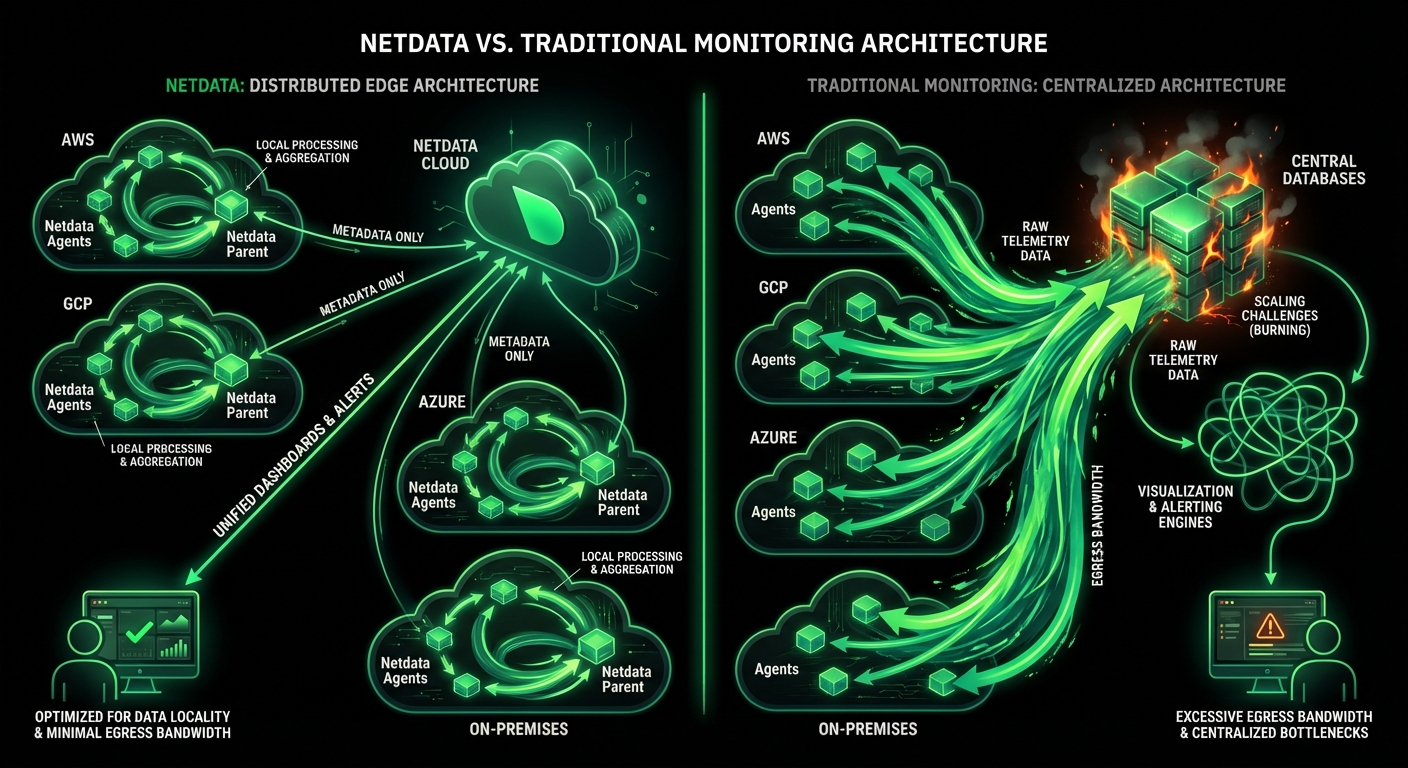
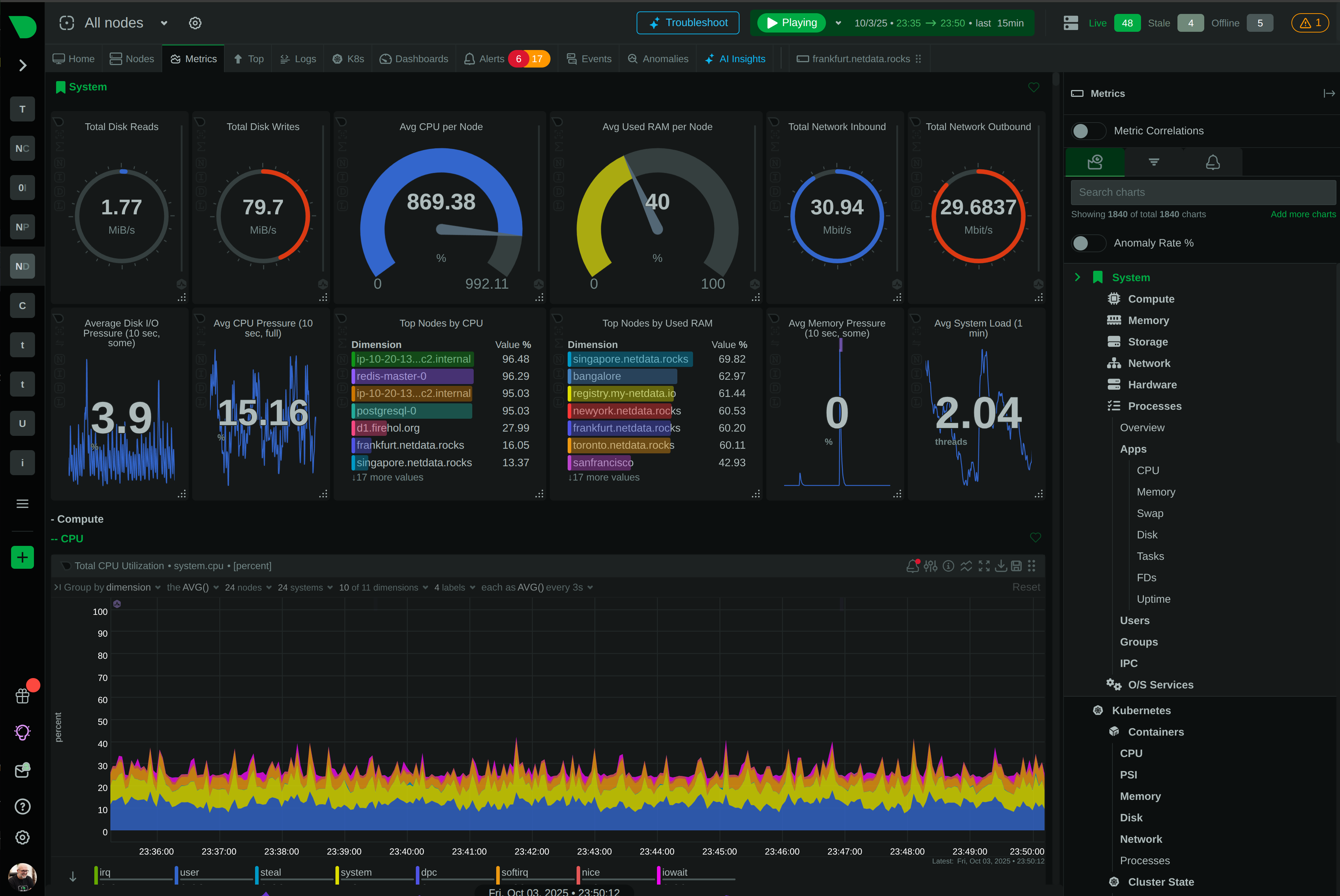
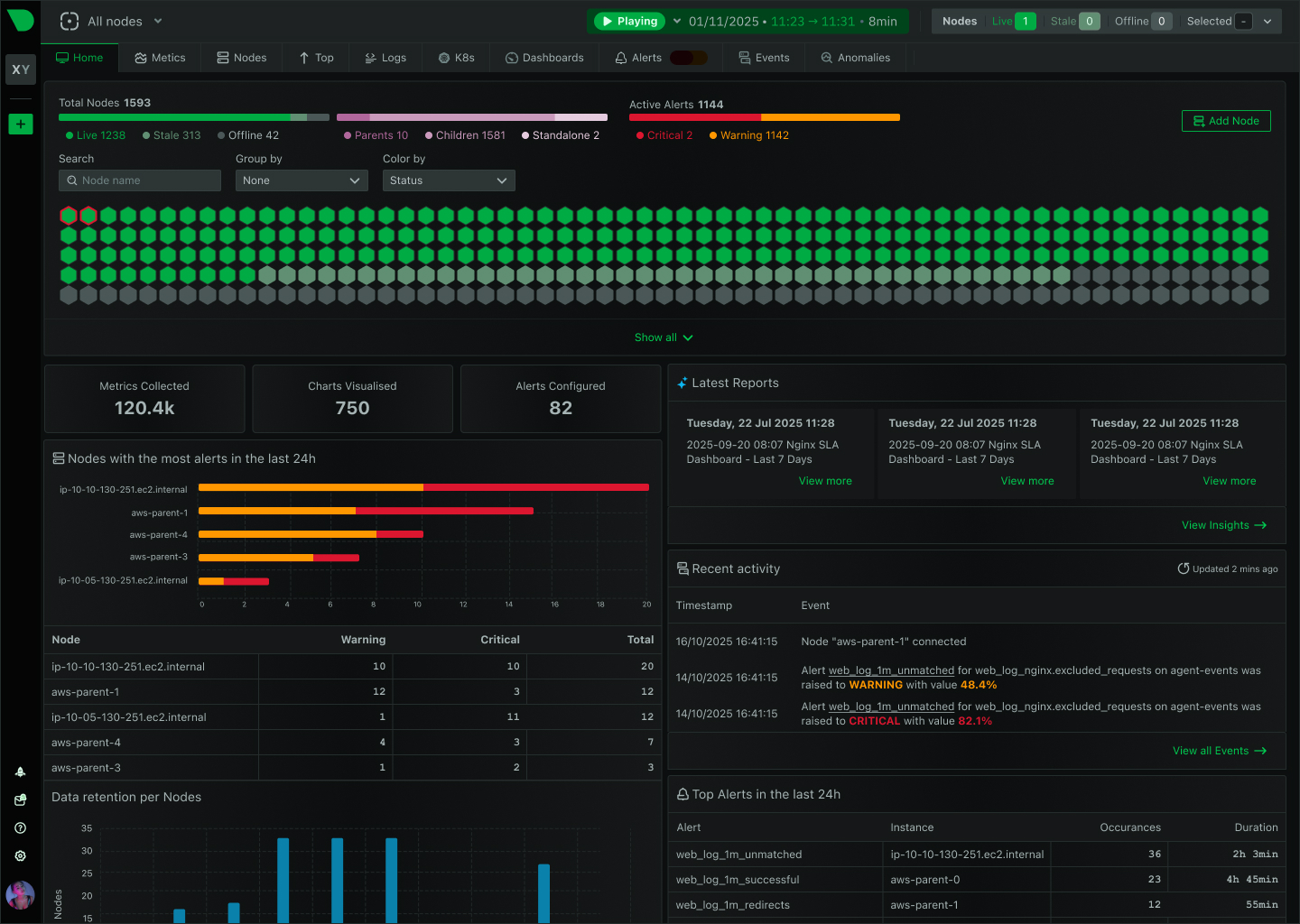
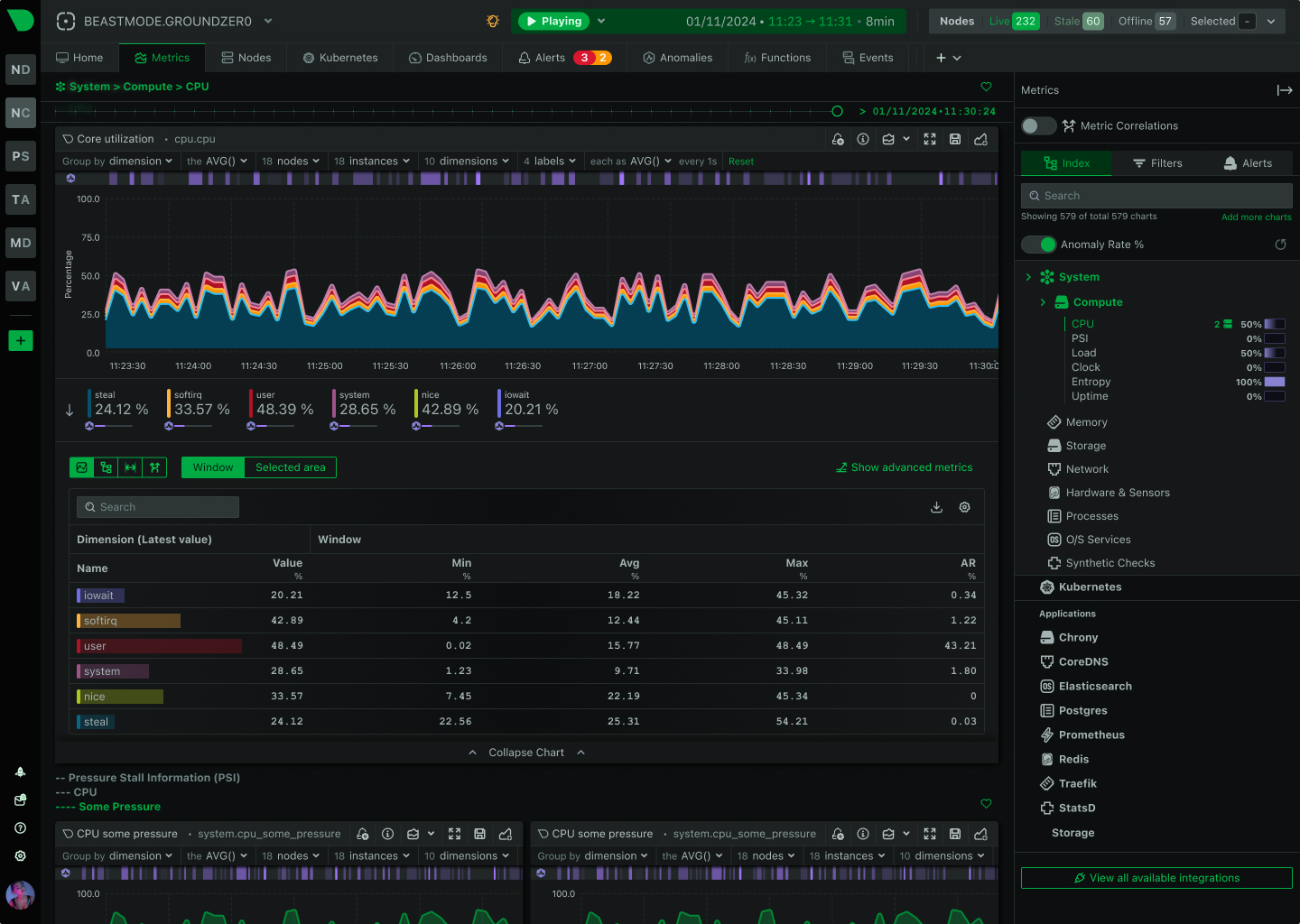
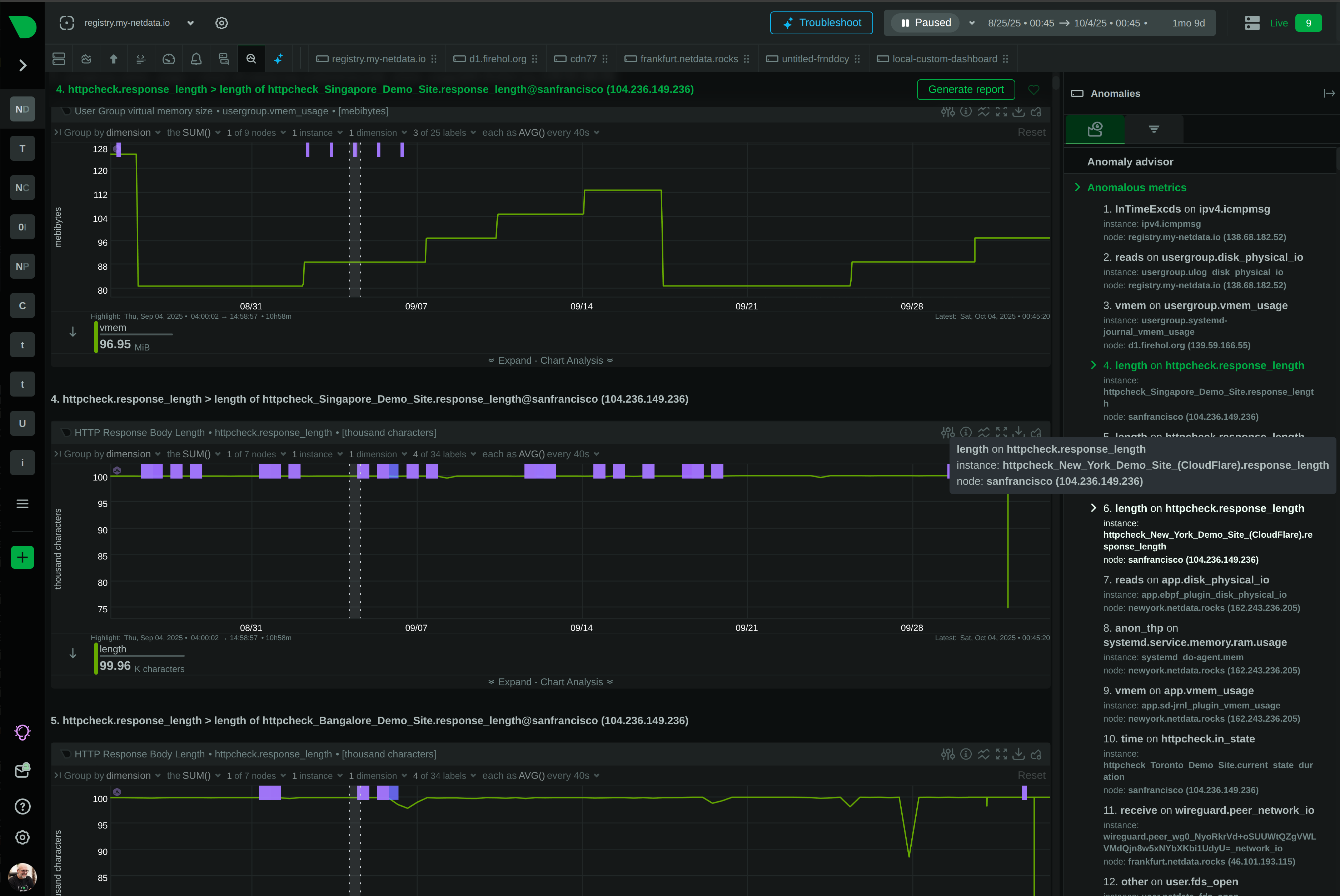
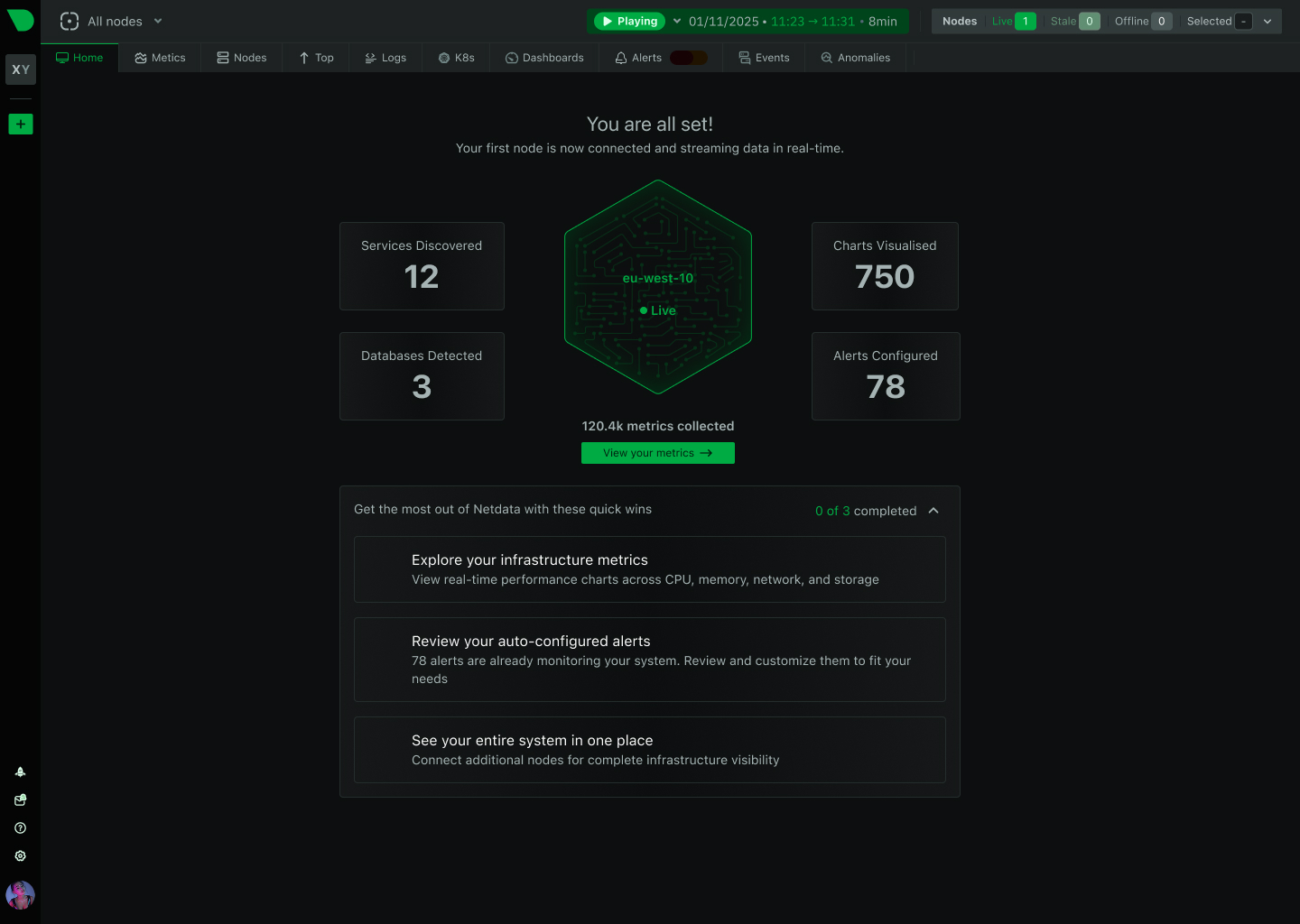
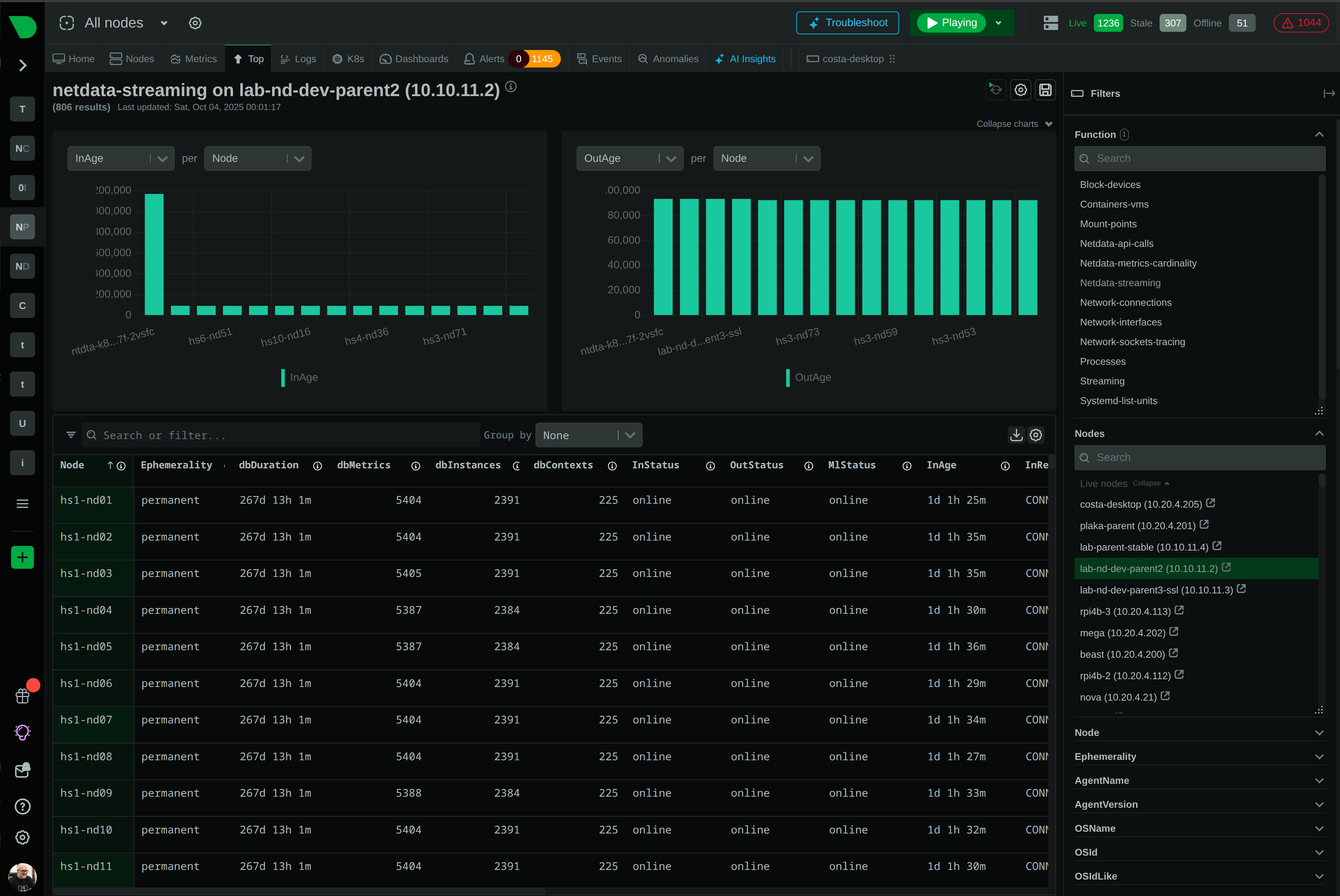
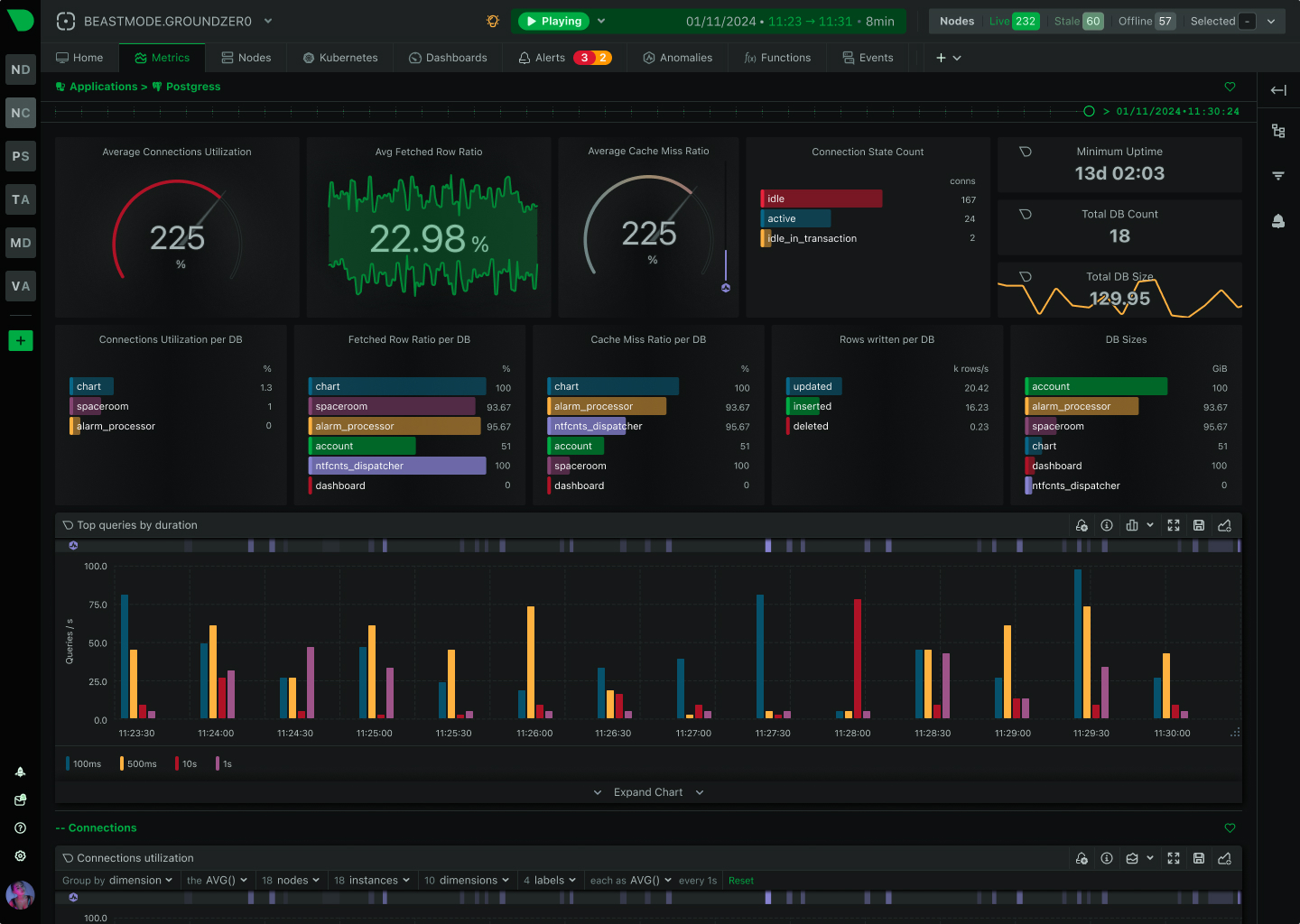
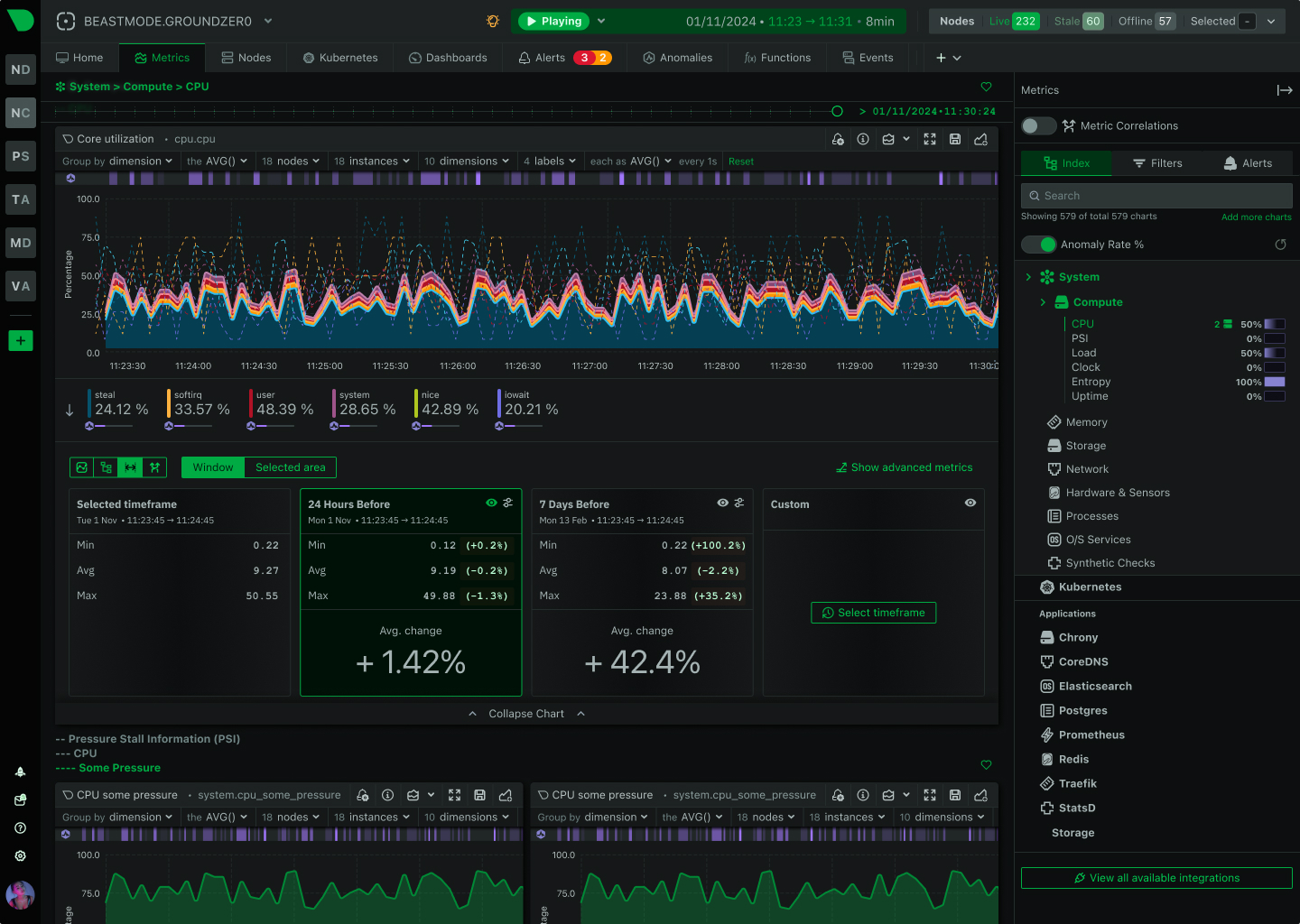
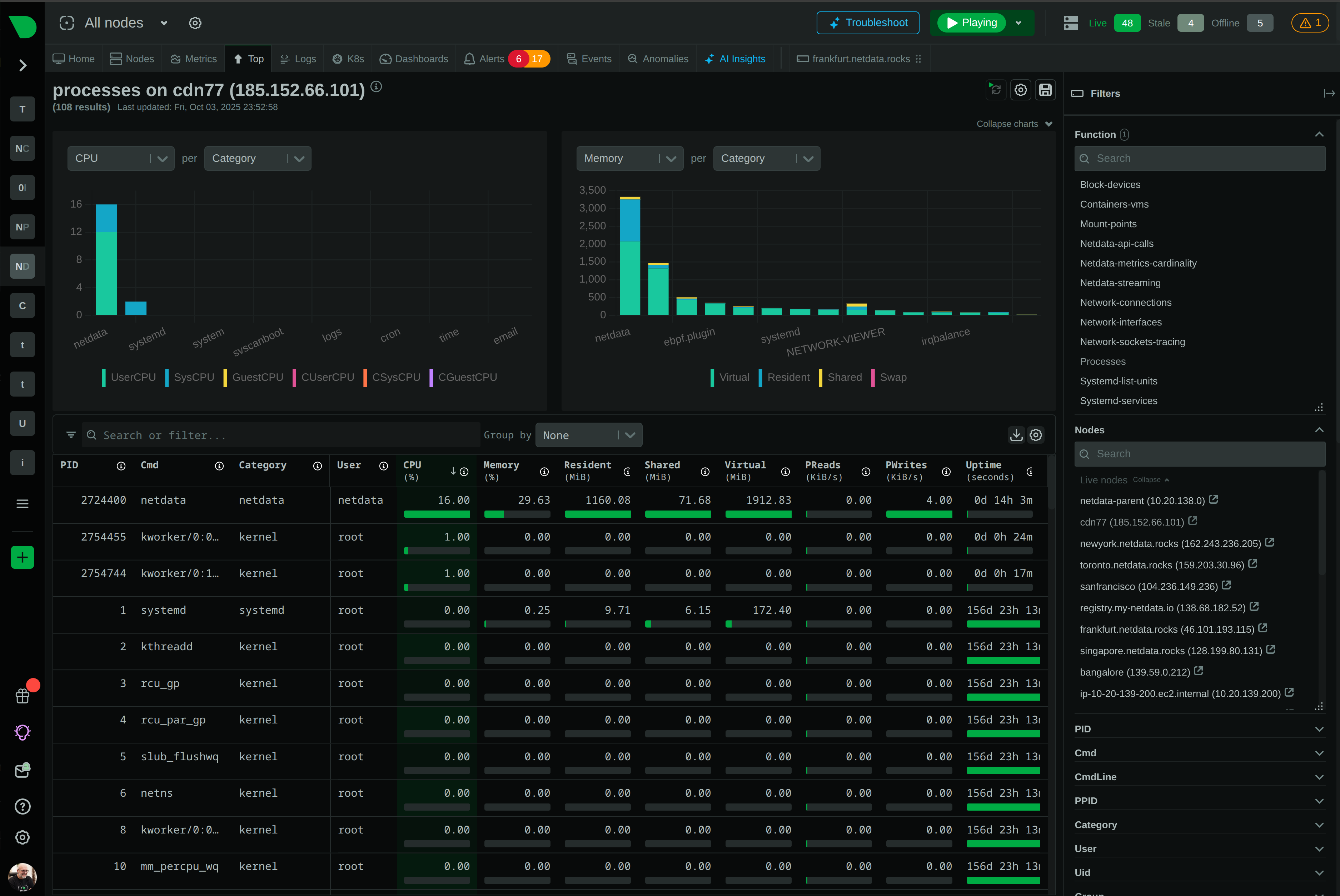
Open Standards, No Lock-In
Observability platforms should embrace open standards and enable interoperability, not create vendor lock-in through proprietary formats, custom query languages, or closed ecosystems.
Why This Matters: Freedom to choose - integrate with existing tools or switch solutions without data migration nightmares. Protect investments - existing instrumentation works without changes. Avoid dependency - no proprietary query languages or data formats that trap you. Community innovation - open-source foundation enables customization and contributions. Future-proof architecture - standards-based approach adapts to evolving technology landscape.
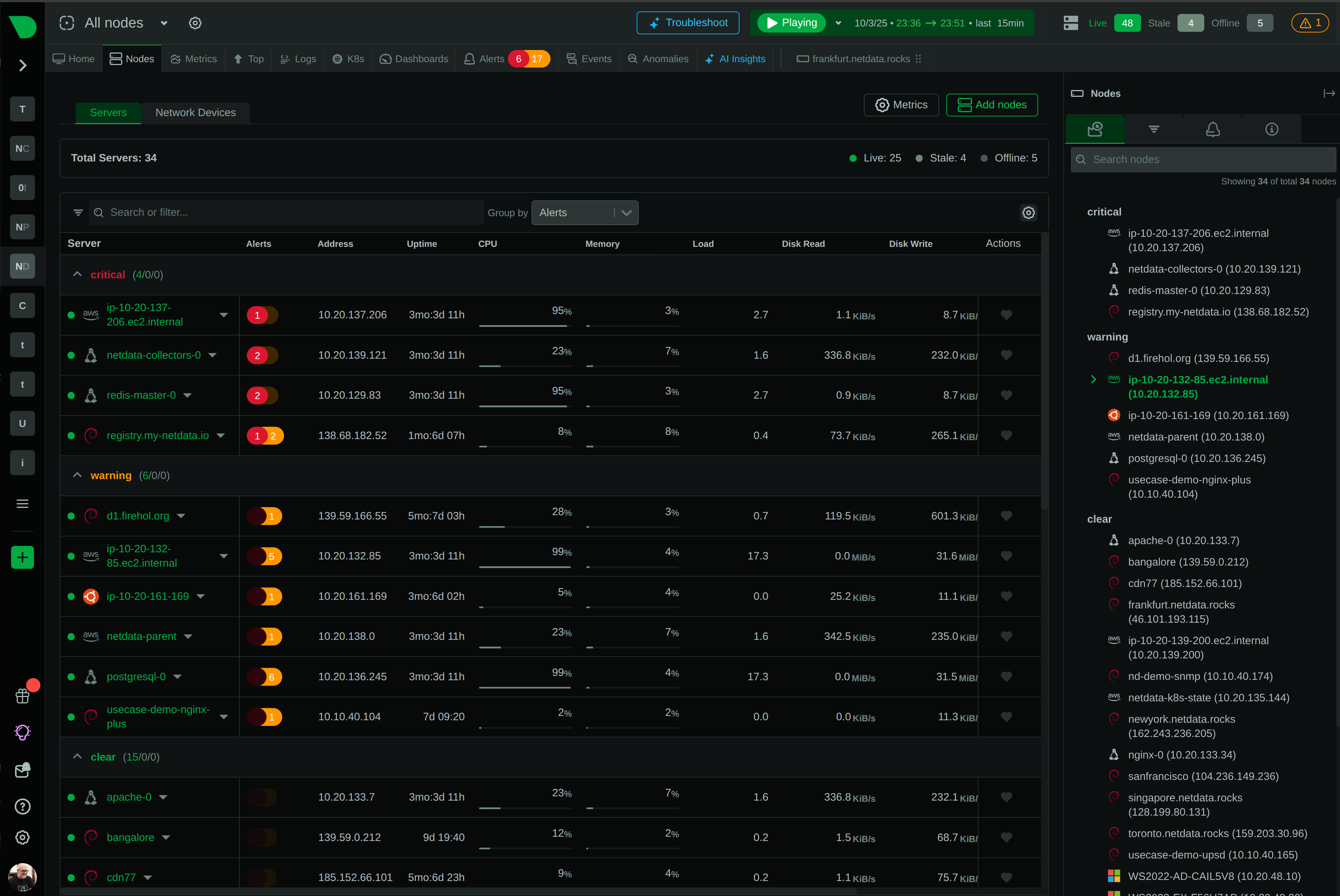
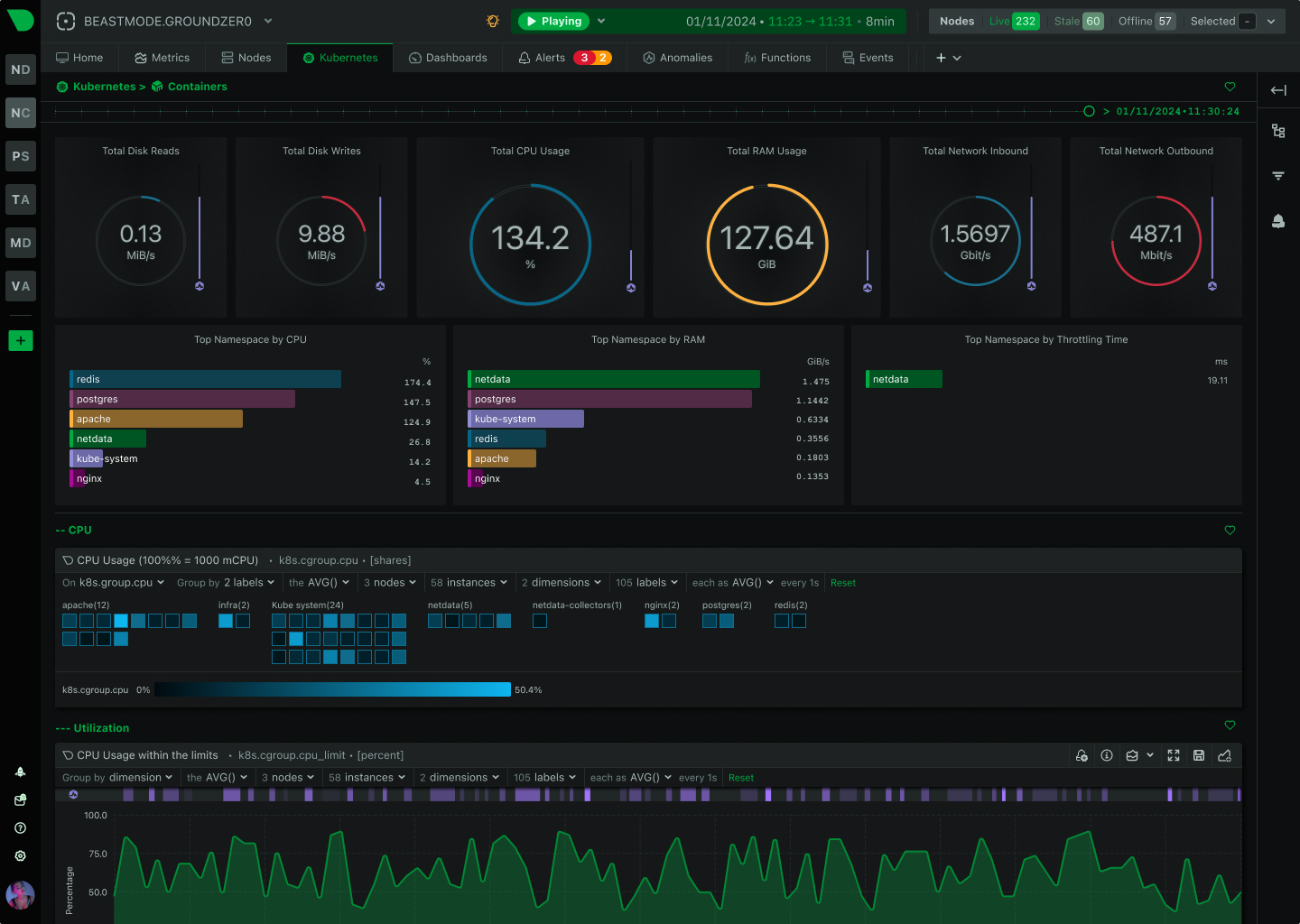
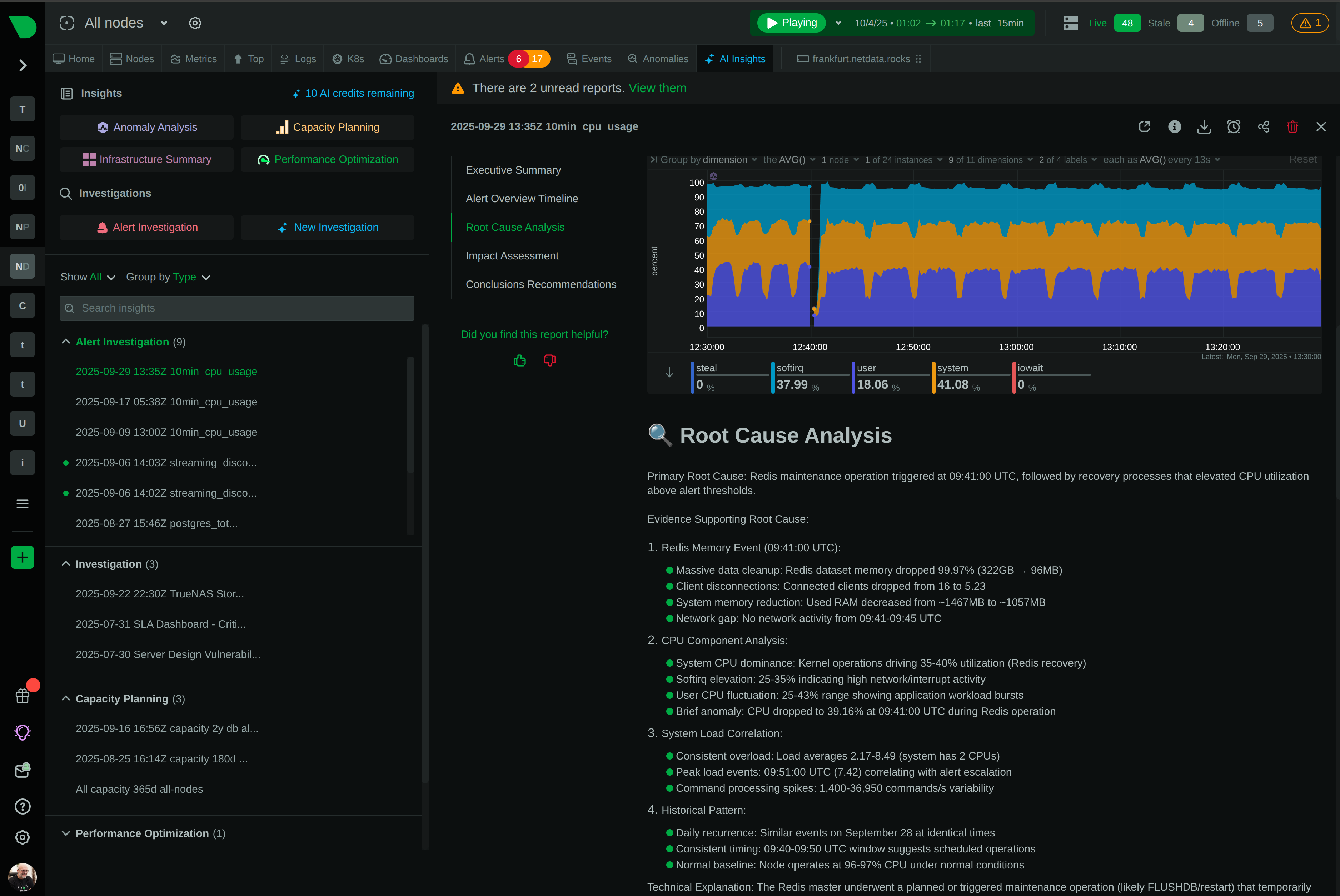
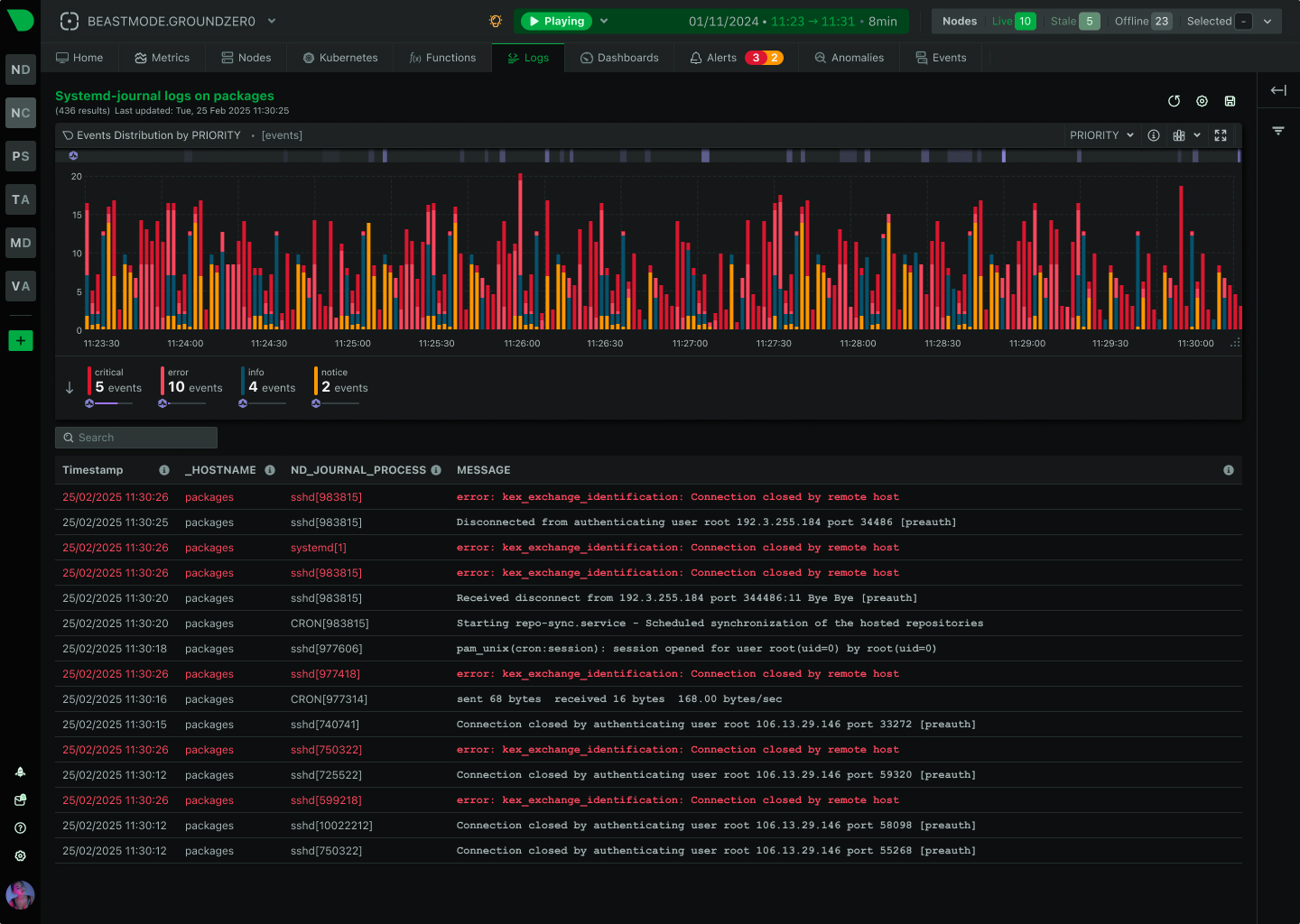
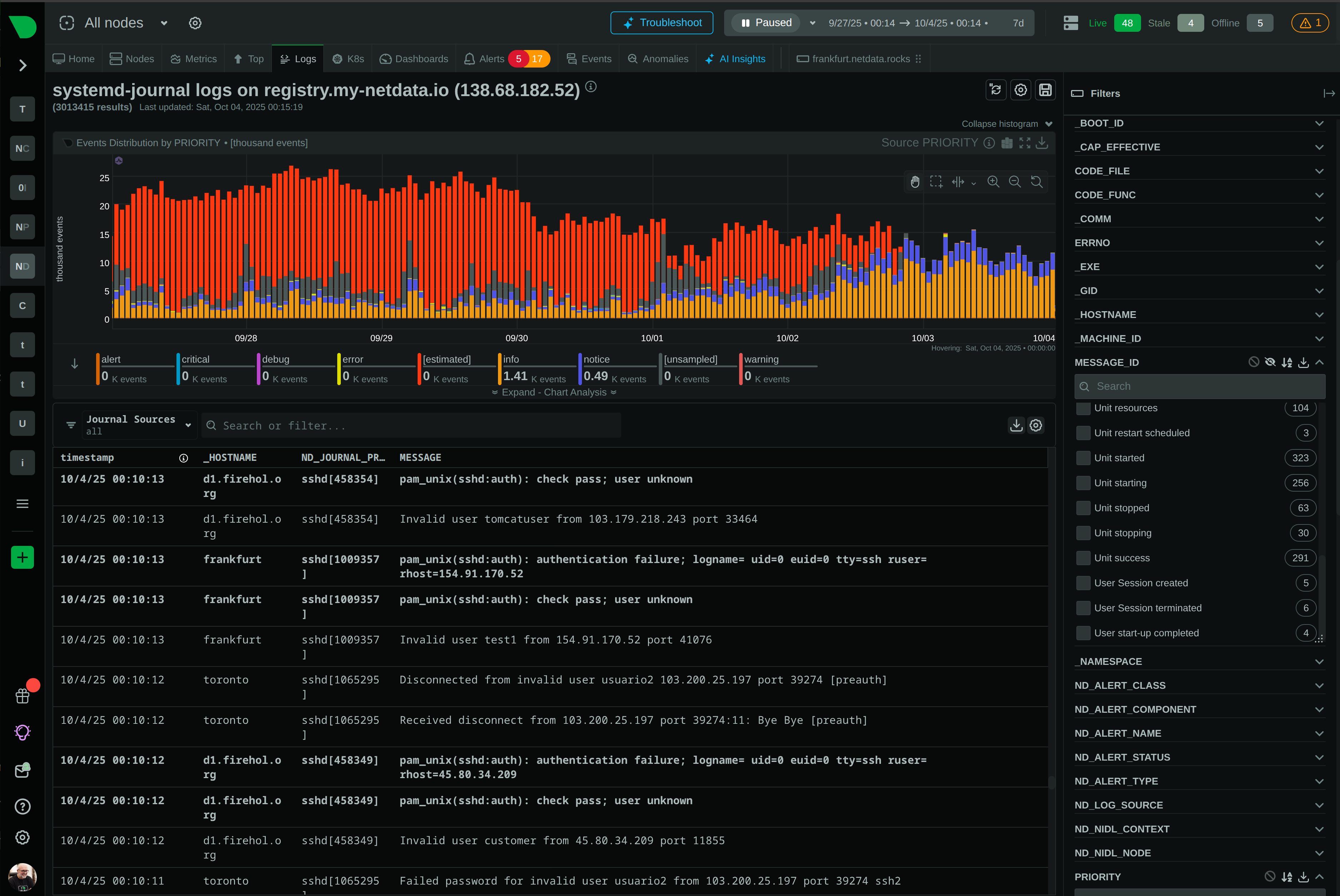
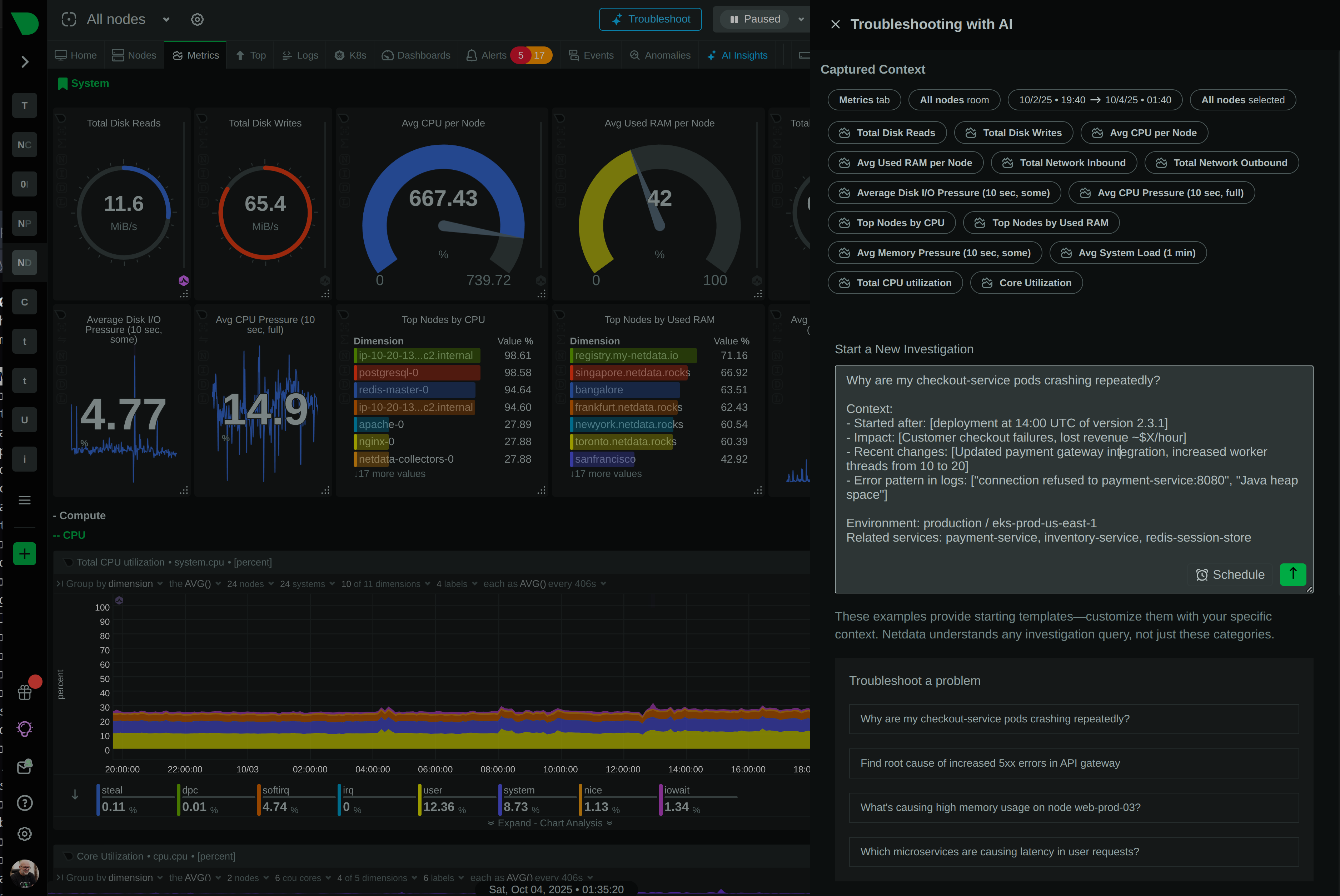
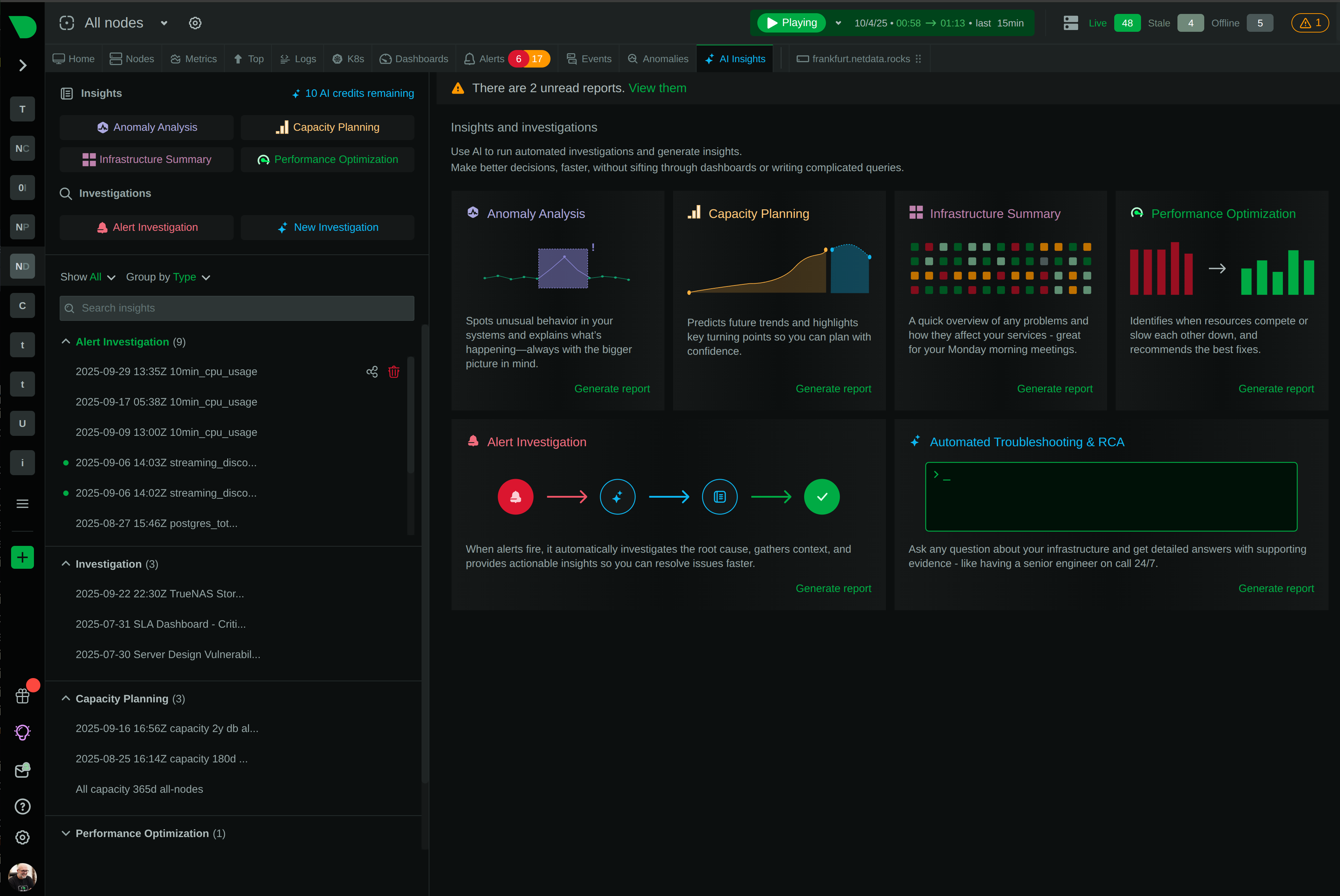
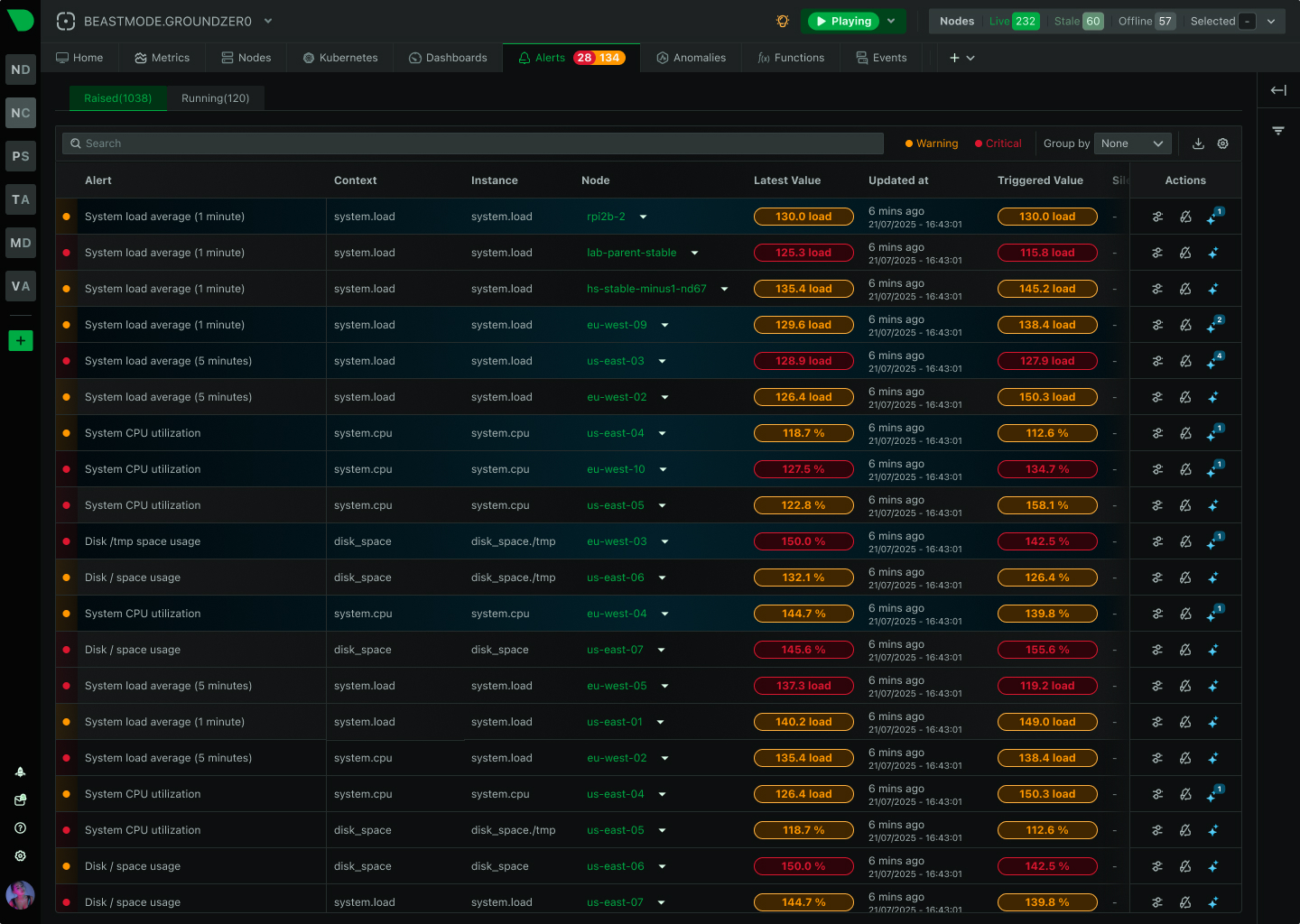
How We Deliver: Open-source core - 76,300+ GitHub stars, 1.5M daily downloads, community validation. Standards support - OpenTelemetry, Prometheus, OpenMetrics, StatsD. Open log formats - systemd-journal, Windows Event Log, industry standards. Grafana integration - native datasource plugin preserves existing investment. Export flexibility - Prometheus, InfluxDB, Graphite, OpenTSDB, TimescaleDB supported.
The Innovation: We built the most advanced monitoring platform on open standards and open-source foundations, proving you don’t need vendor lock-in to deliver exceptional value.
76K+ GitHub Stars
Explore Open Source