Netdata Featured with Multiple “Best Of” Category Badges in 2024
As we are close to the end of this year, we are thrilled to announce that Netdata has been recognized with multiple “Best of” badges from Gartner Digital Markets brands: Capterra, Software Advice, and GetApp, leading software recommendation search engines.
This “Best of” badges program is an independent assessment that evaluates user reviews to help buyers identify the highest-rated software companies in specific categories that offer the most popular solutions.
“Receiving these badges is truly honorable and reinforces the value we deliver to our users every day. At Netdata, we are proud to offer the simplest, fastest, and significantly easier real-time and low-latency monitoring system that sets the standard for infrastructure monitoring and observability. This recognition reflects the incredible feedback and support of our global community.”
— Costa Tsaousis, CEO
Check out what our customers have to say about their experience with us
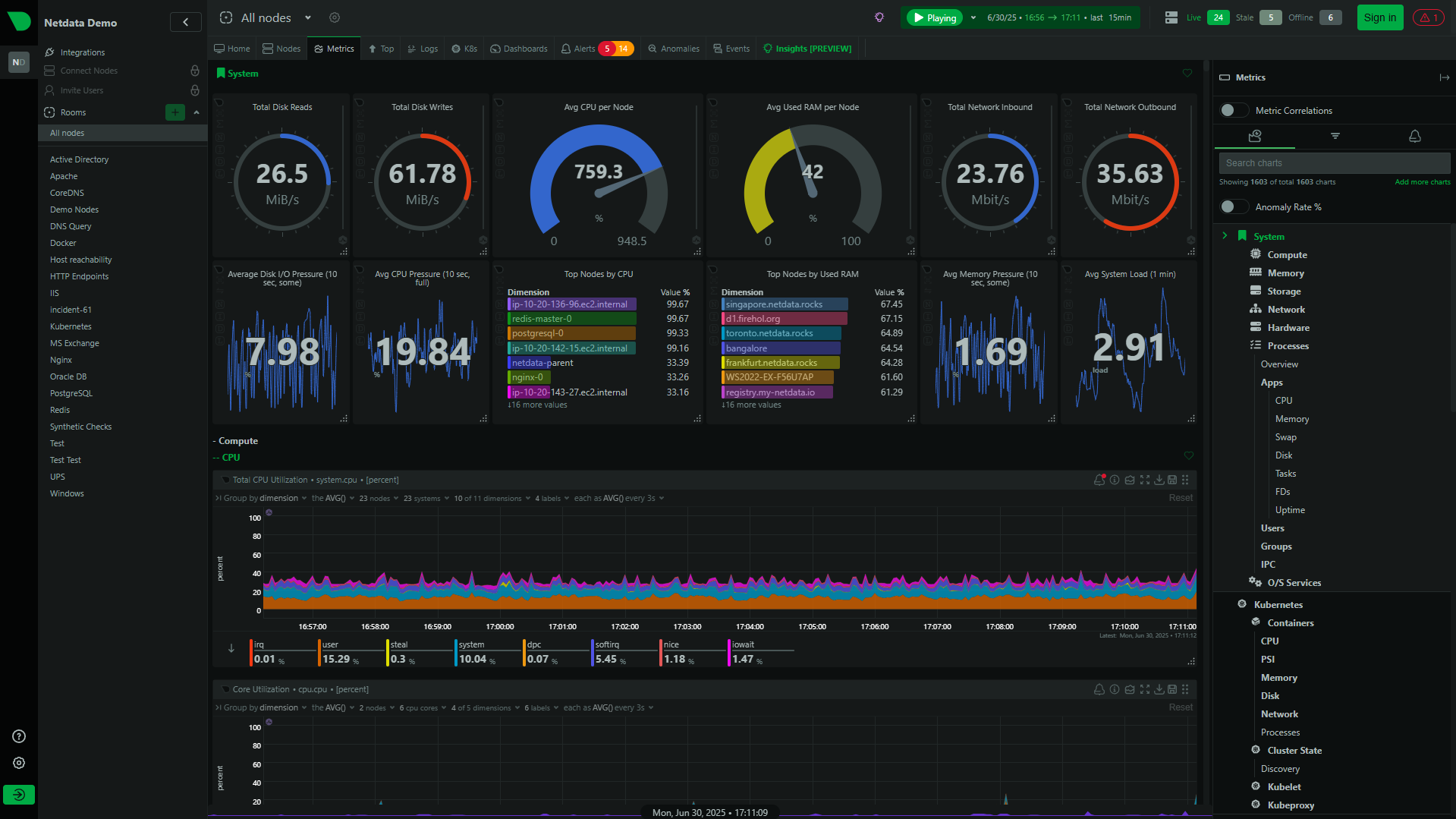
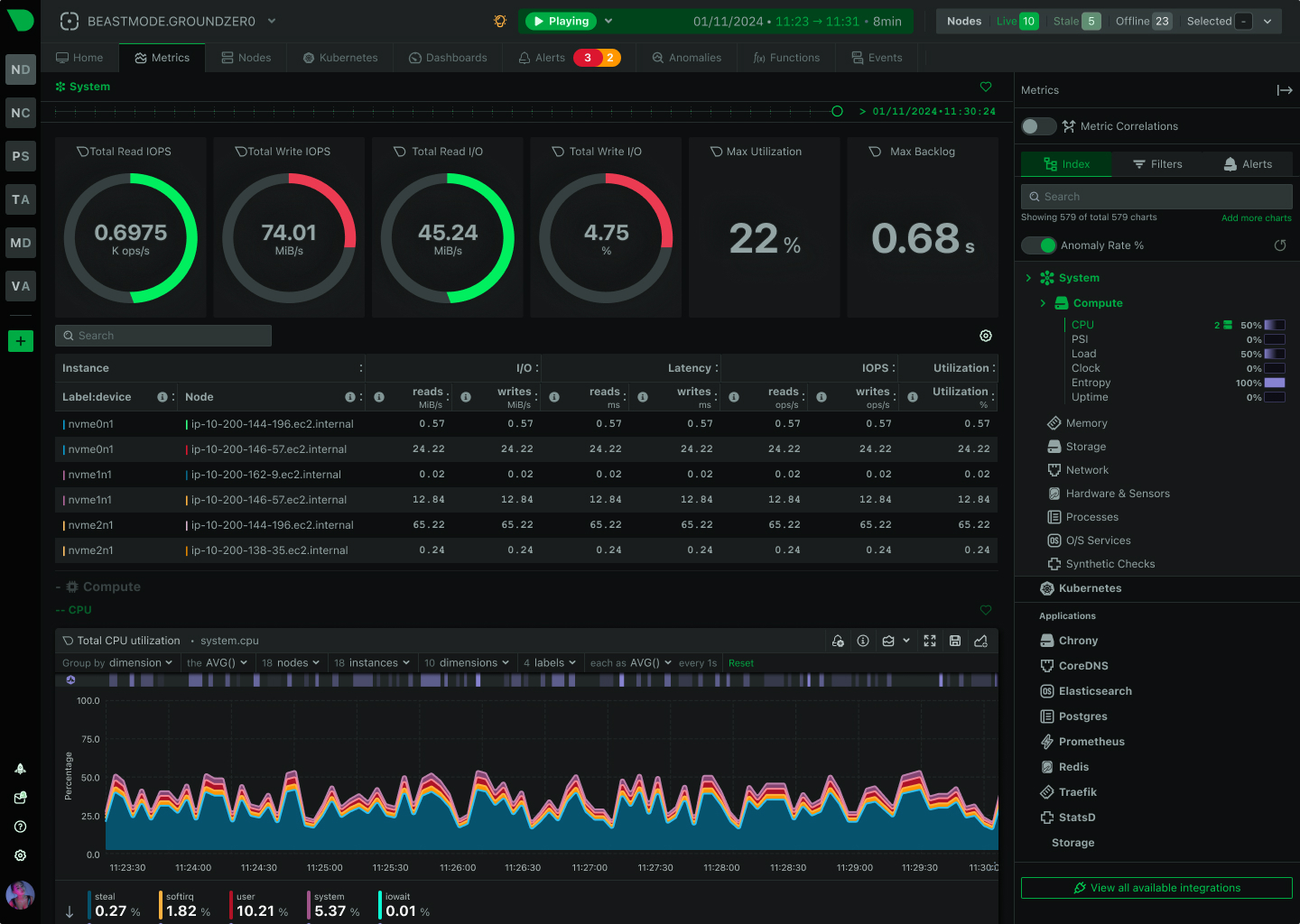
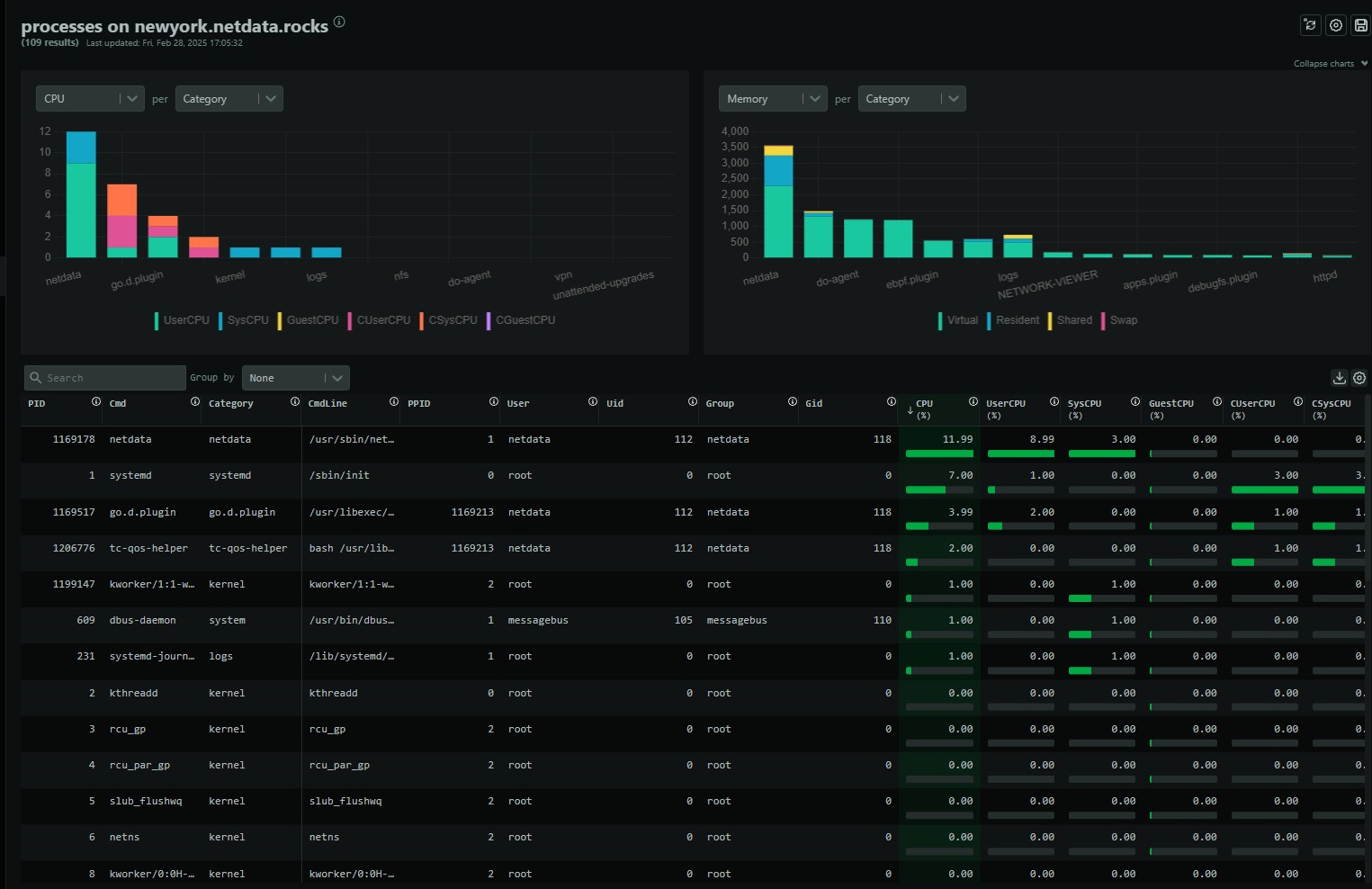
With per-second metric granularity, edge-based machine learning for anomaly detection, and a powerful Agentic AI for automated root cause analysis, Netdata streamlines troubleshooting and transforms reactive firefighting into proactive engineering. It offers a single, integrated solution for data collection, storage, visualization, and alerting, eliminating the complexity of stitching together multiple tools.
What is Last9?
Last9 is a Site Reliability Engineering (SRE) platform focused on improving software reliability. It is not a primary monitoring tool but rather an analysis layer that sits on top of your existing observability data, typically from sources like Prometheus. Last9’s core strengths lie in its ability to help teams define, manage, and track Service Level Objectives (SLOs) and error budgets.
Its “Change Intelligence” feature connects software deployments and configuration changes to shifts in system behavior, helping engineers understand the impact of their work. Last9 is built for SRE teams who have an established monitoring pipeline and need a specialized tool to formalize their reliability practices and reduce alert fatigue by focusing on user-impactful issues.
Key Features of Last9
Last9 provides several capabilities designed specifically for SRE teams:
- SLO Management: Define and track service level objectives across your infrastructure
- Error Budgets: Monitor error budgets to balance feature velocity with reliability
- Change Intelligence: Connect deployments to performance impacts
- Alert Correlation: Reduce noise by correlating related alerts
Why Choose Real-Time Monitoring?
Real-time monitoring is essential for modern infrastructure management. Traditional monitoring tools that sample metrics every 60 seconds miss critical events and anomalies that occur between sampling intervals.
Netdata’s per-second granularity ensures you never miss important events, providing the visibility needed to:
- Detect issues immediately before they cascade
- Understand system behavior during critical incidents
- Optimize performance with accurate, high-resolution data
- Reduce MTTR through faster problem identification