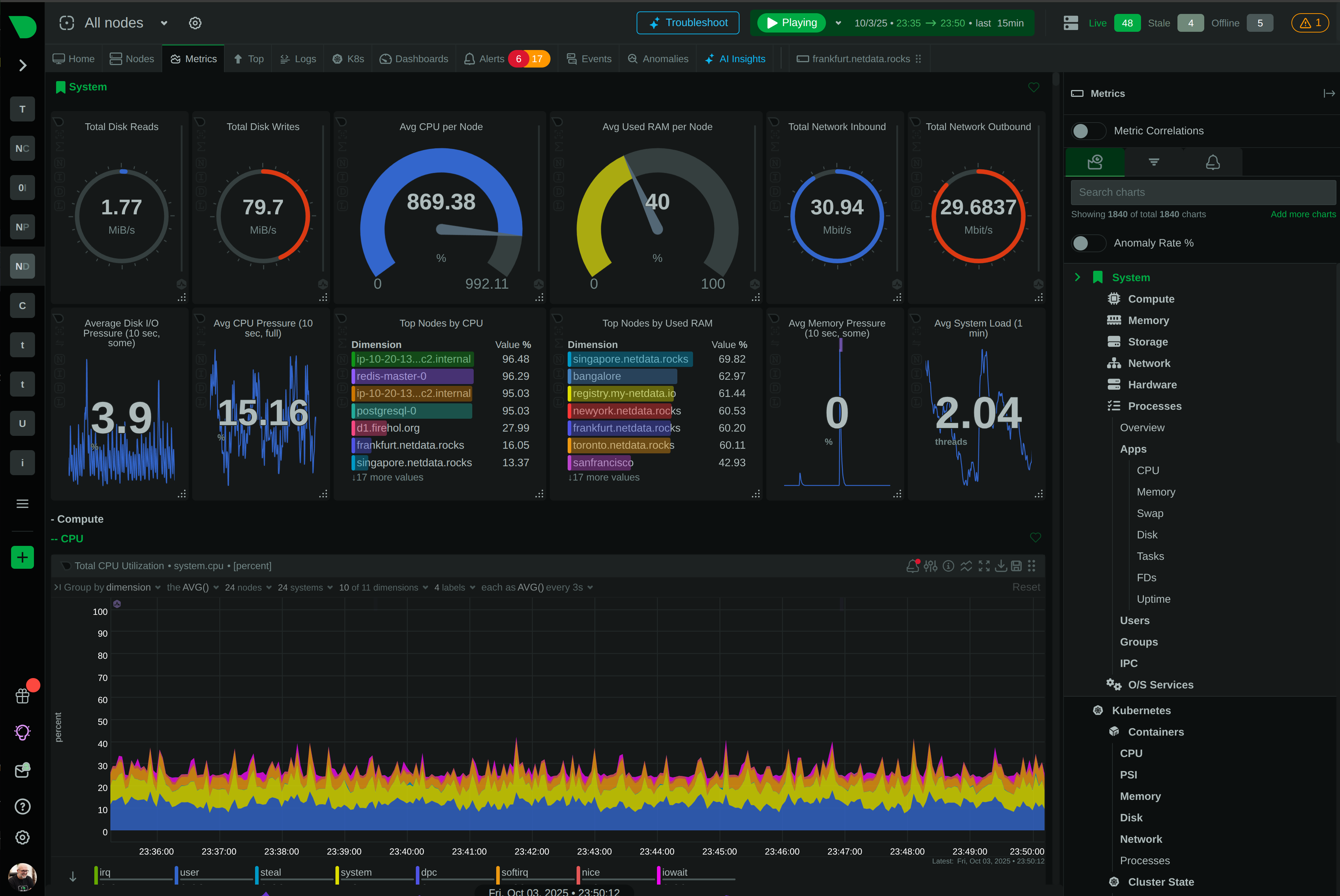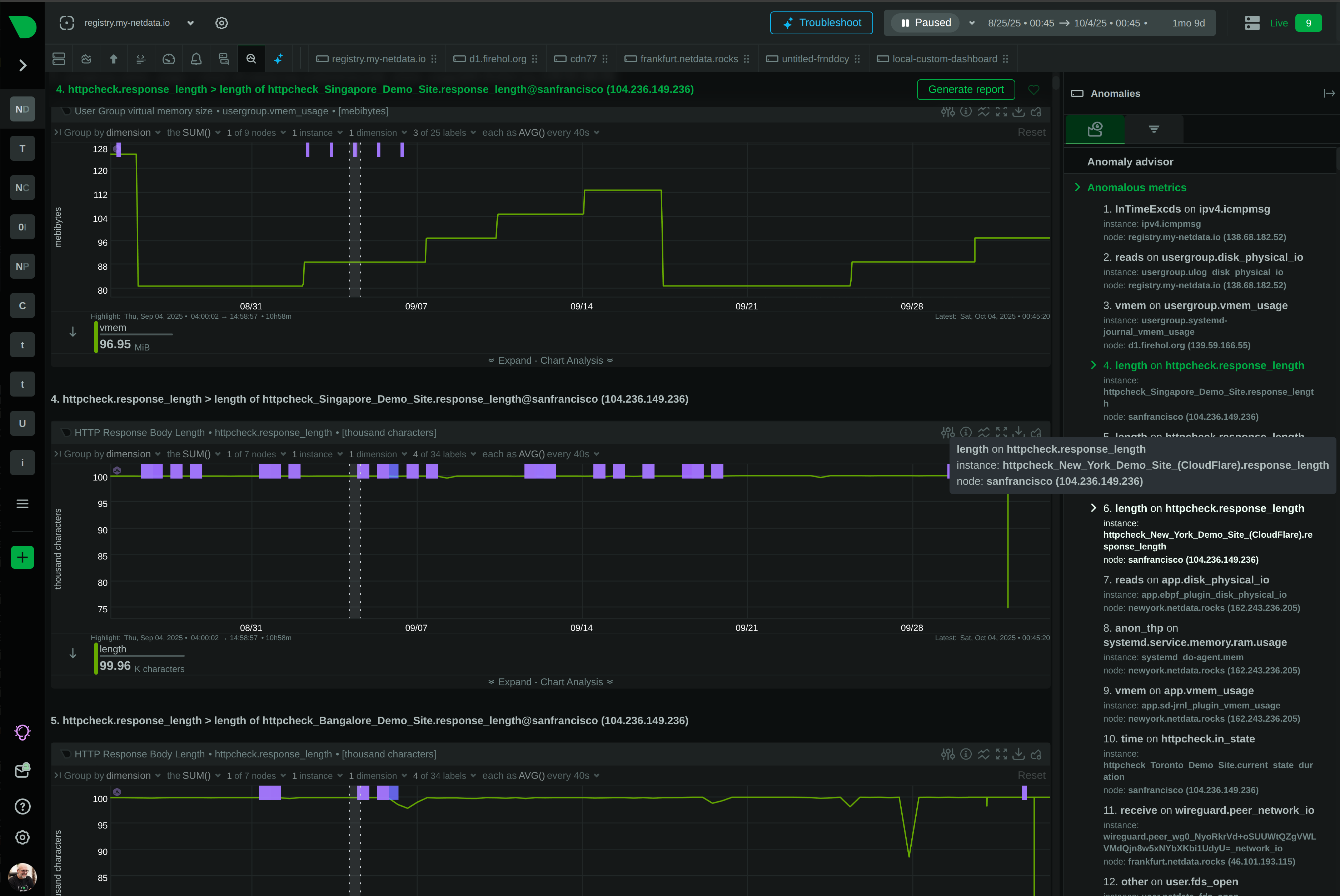

Product Roadmap
The Future of Infrastructure Observability
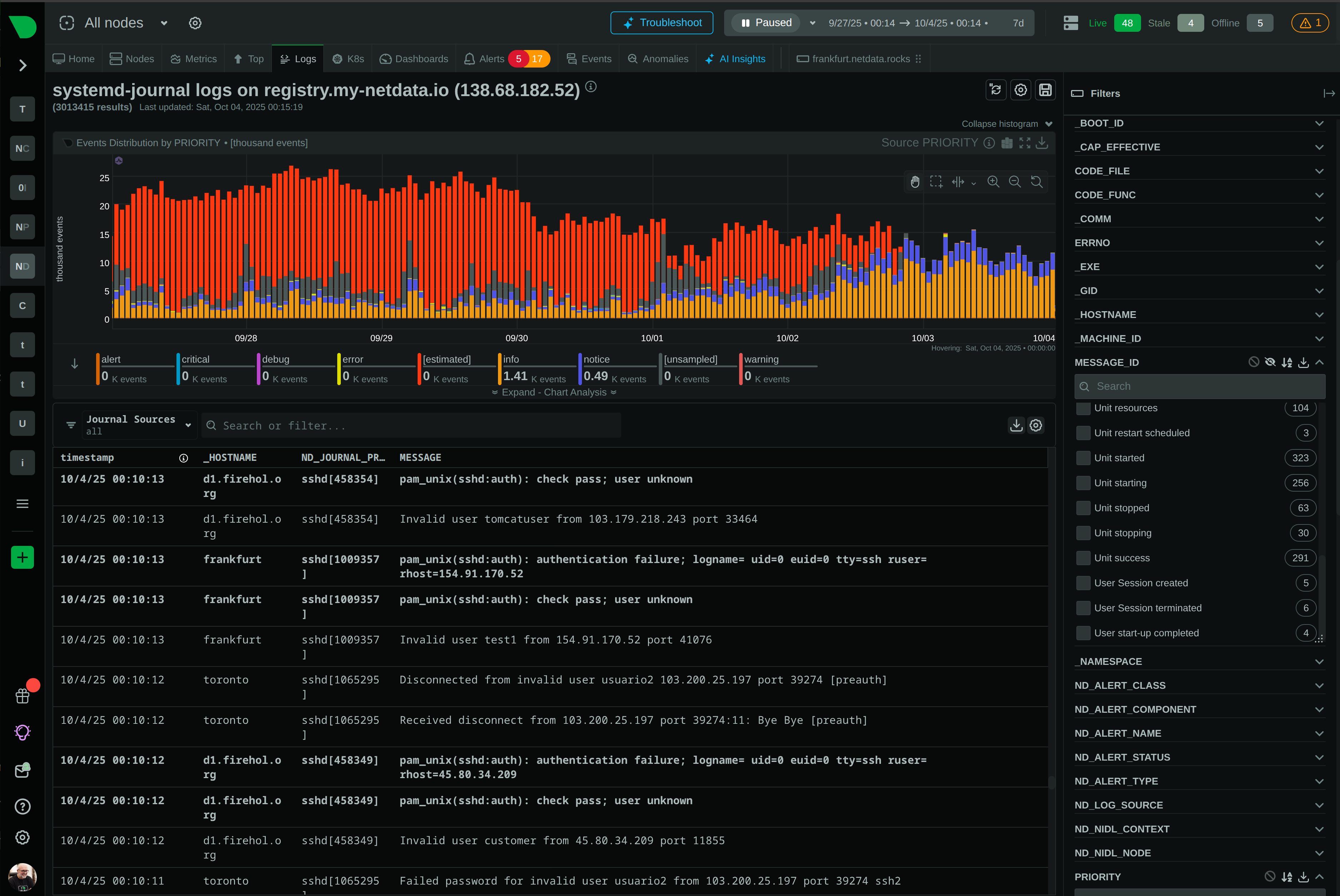
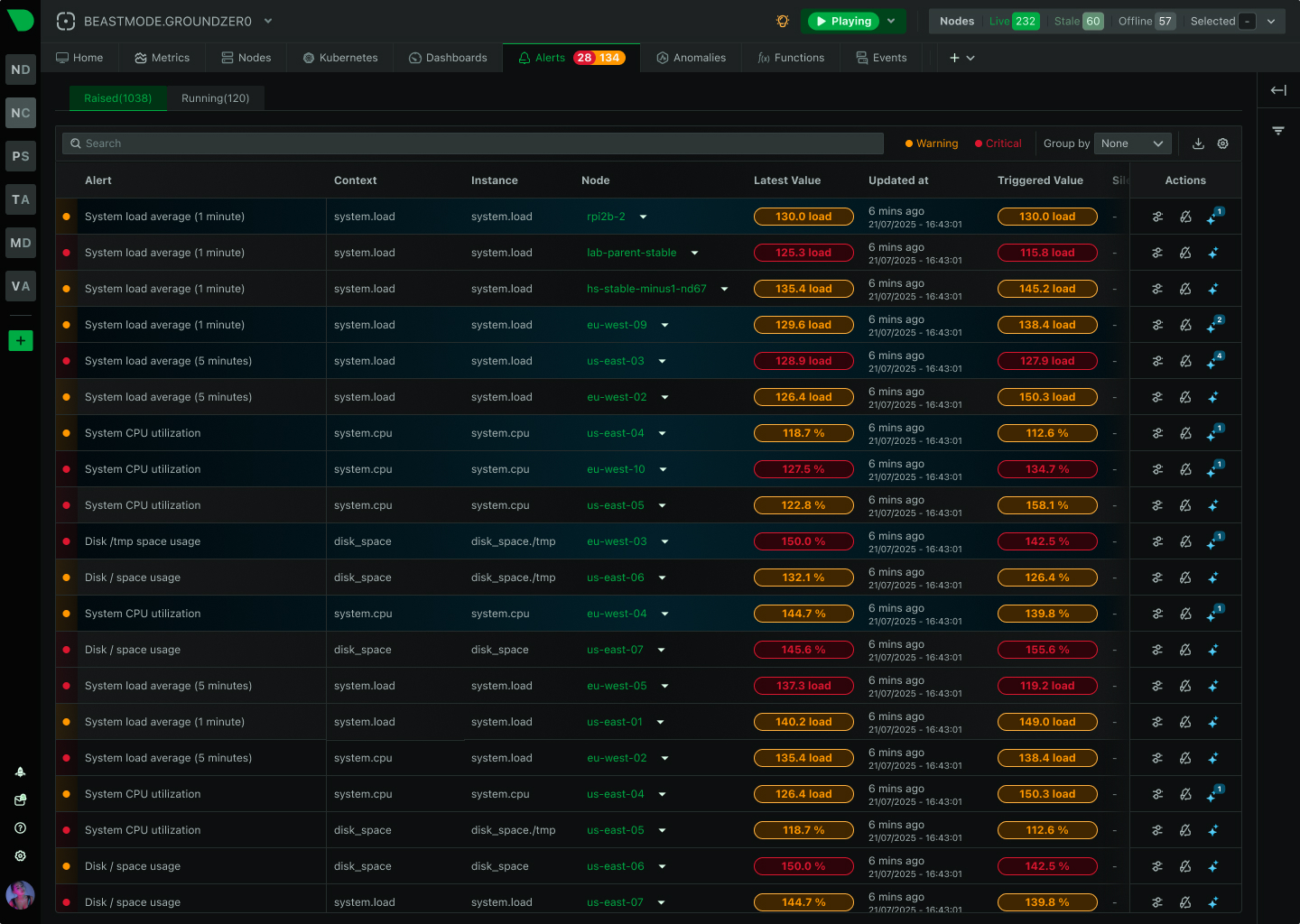
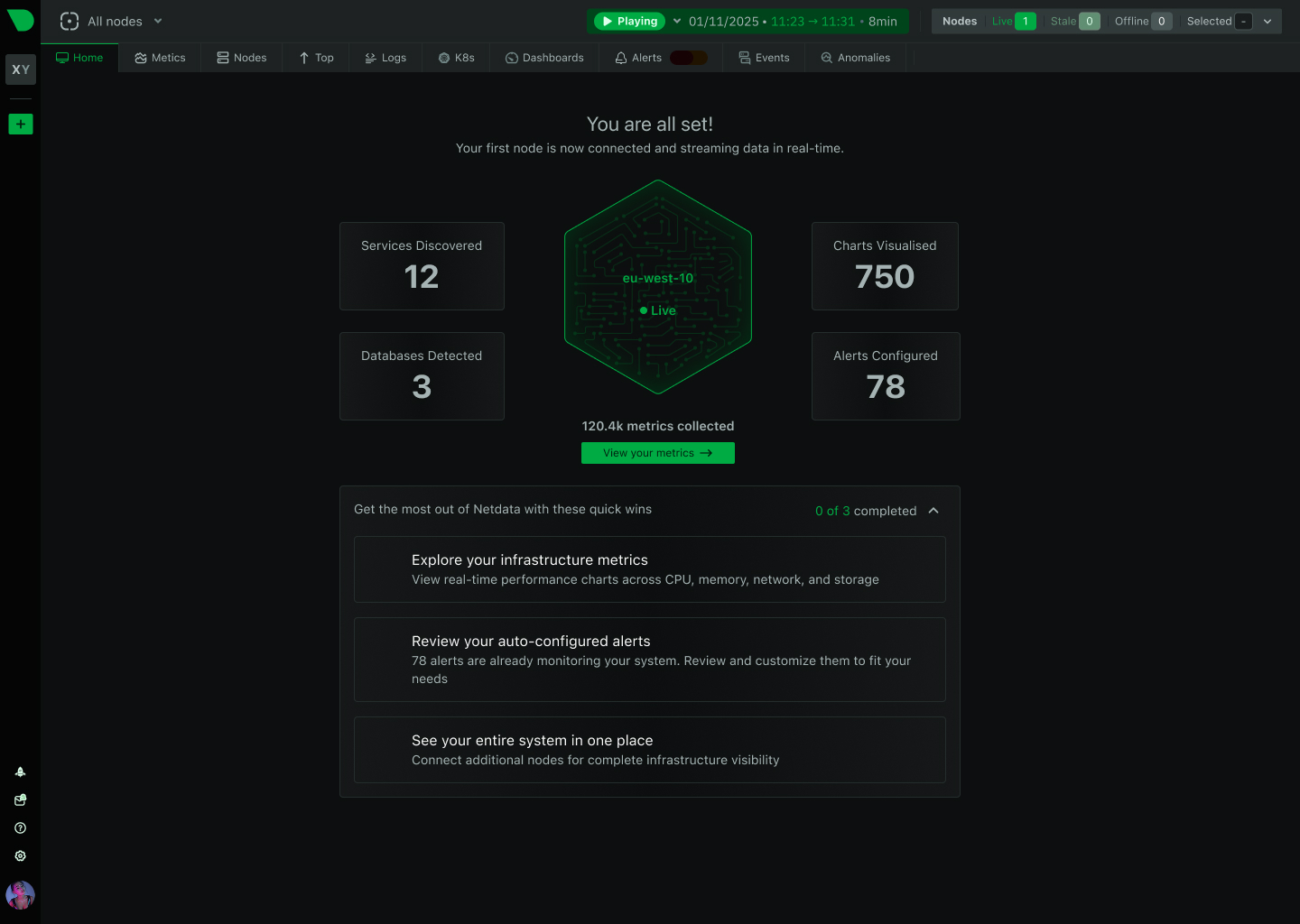
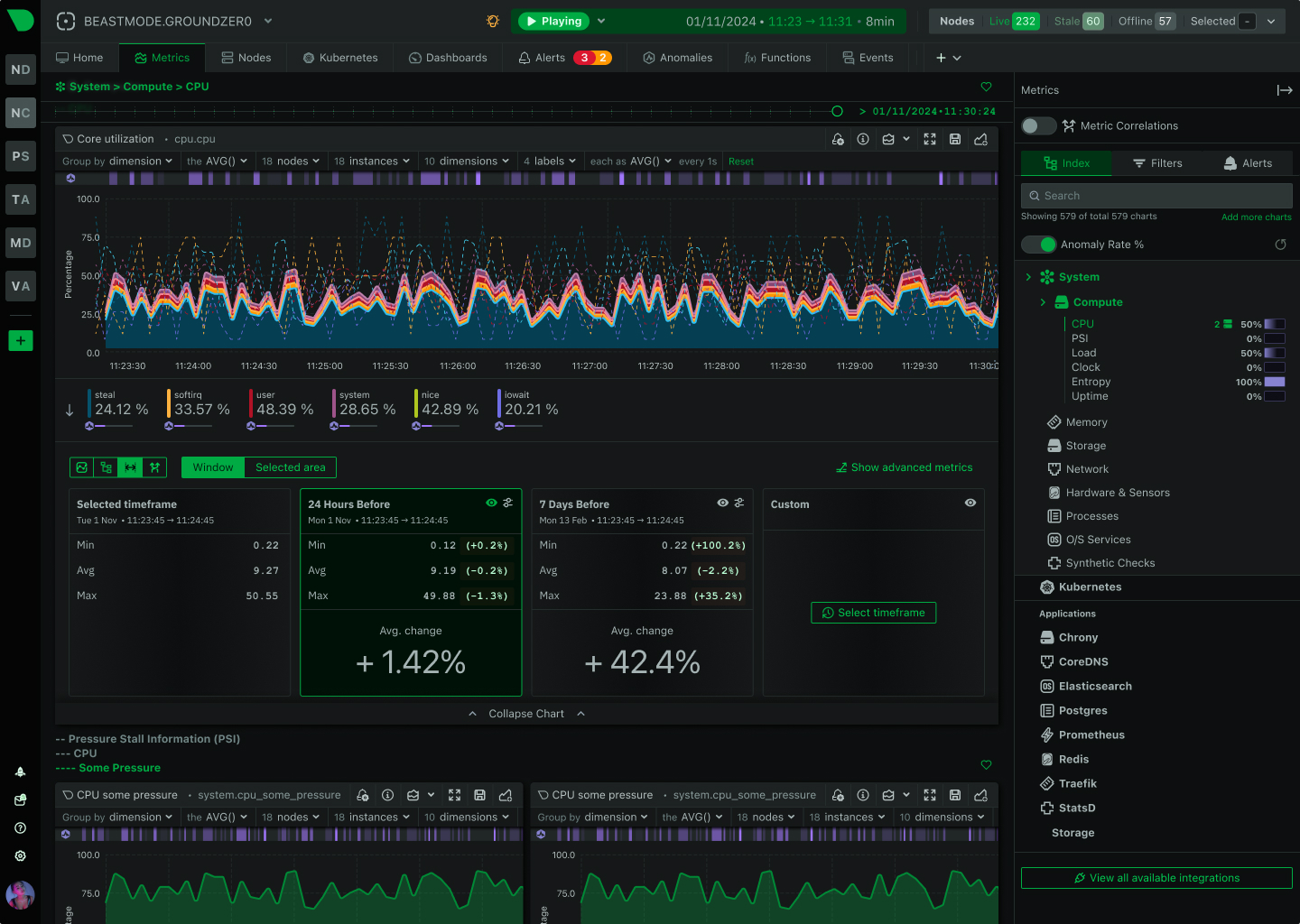
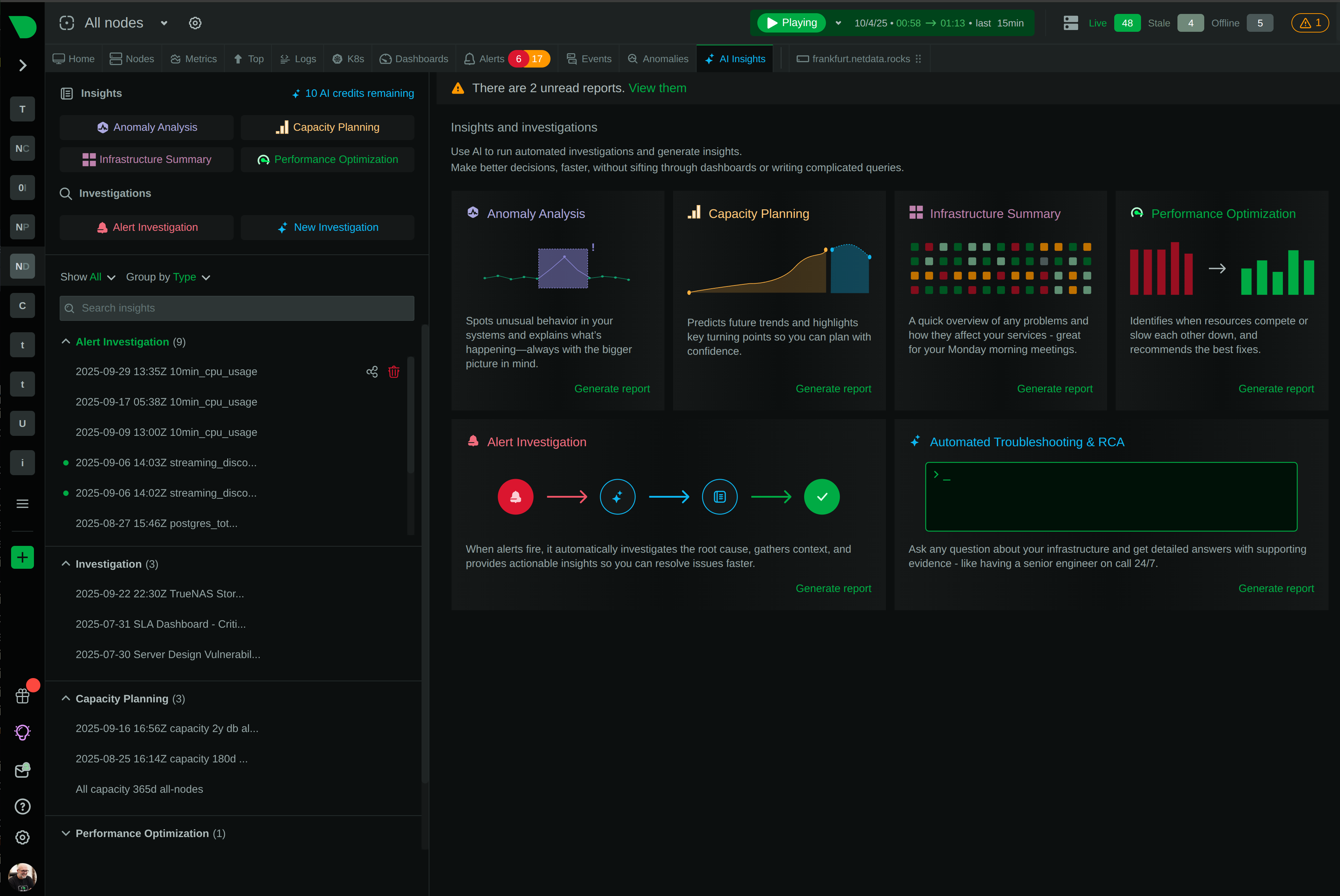
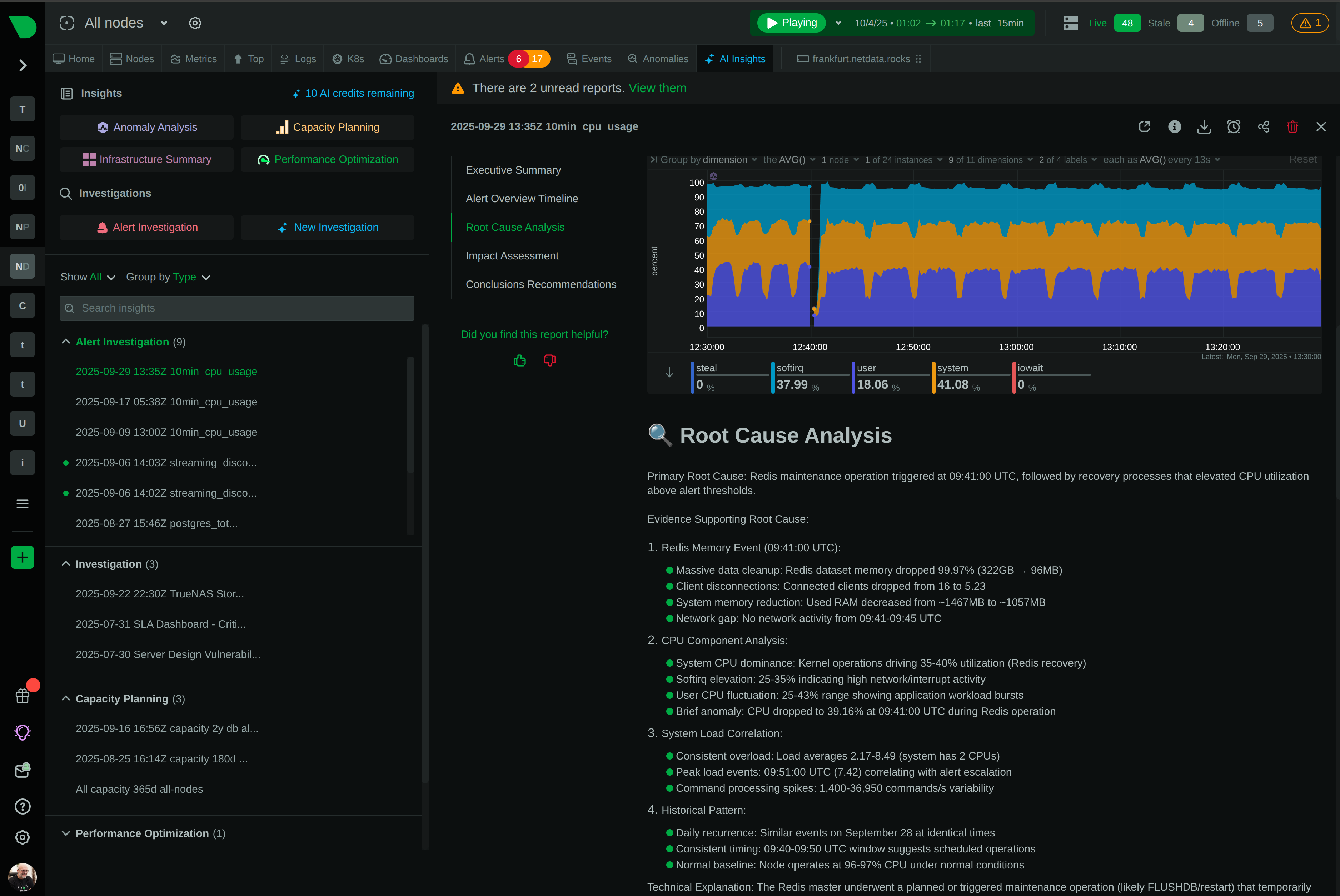
Netdata is evolving from infrastructure monitoring into a complete, AI-native observability platform. This page outlines our strategic direction and the investments we are making across the product.