






Introduction to Distributed Observability
Users often find themselves puzzled by the concepts of decentralized or distributed monitoring. This confusion is likely due to many monitoring systems claiming distributed capabilities, making it challenging to discern how Netdata stands out.
To grasp the distinction, we must delve into the evolution of monitoring systems.
When the first monitoring systems were created, about 20-25 years ago, they were built as SNMP collectors. The monitoring application was installed on a server, configured to discover network devices via SNMP, pulling data once every minute, per device. Simultaneously, the monitoring system was exposing a daemon to collect SNMP traps (key events generated by the network devices, pushed to the monitoring system).
Thus, the first generation of monitoring systems was completely centralized.
Overcoming Centralized Monitoring Limitations with Distributed Solutions
A significant hurdle with centralized monitoring was its inability to consistently access all network devices, hindered by routing, IP addressing, or security policies. Often, the devices to be monitored were in locations beyond the monitoring system’s direct reach for SNMP querying.
Therefore, monitoring solutions had to introduce probes. A probe acted like a relay between the network devices monitored and the monitoring system, facilitating their communication. The network devices communicated with the probe next to them, and the probes relayed this information to the monitoring system.
To emphasize this new capability (having probes), monitoring systems declared themselves now “distributed”.
Today, all monitoring systems have distributed data collection. Even the first generation of check-based monitoring solutions, such as Nagios, Icinga, Zabbix, CheckMk, Sensu, PRTG, SolarWinds, have probes distributed across the infrastructure for collecting data and performing checks.
The Evolution Towards Integrated and Scalable Observability
As the Internet matured and the focus shifted towards more complex IT technologies, SNMP’s limitations became apparent, necessitating more structured data and many different kinds of data sources.
This led to the development of monitoring systems around time-series databases. Unlike the first generation, these systems now have a more powerful core, capable of ingesting significantly more data, collected via monitoring agents. These agents are installed on all IT systems to collect structured data through multiple methods and push it to the monitoring system for processing and storage.
Several metrics-focused agents were introduced during that time, such as collectd and telegraf, pushing metric data to time-series databases like Graphite and OpenTSDB. Later, Prometheus reused the pull model of the first-generation systems, transitioning from agents (push) to exporters (pull), a move that, despite its controversy, has seen partial abandonment in favor of the prevailing OpenTelemetry standard.
For logs, originally syslog primarily serviced the world, centralizing log entries to log storage servers. Logs were still stored in compressed text log files, but at least they were all together in one place. With the introduction of Elasticsearch and other document indexing technologies, log servers also became databases, and a plethora of agents and technologies appeared for ingesting, processing, and indexing logs.
Integrated Monitoring Systems
The next natural evolution was to address the need for integrated monitoring systems. The world had powerful time-series and logs databases, but more was needed to actually unify the observability experience and link everything together. This became even more prominent with the introduction of microservices and the need for tracing and tracking their relationships and dependencies.
Thus, the next generation of integrated monitoring systems emerged. These monitoring systems have the capability to unify the entire infrastructure and combine all available data, surfacing the complex interdependencies between systems, services, and applications.
Still, all these generations of monitoring systems have a central core. This core uses multiple kinds of databases (time-series, logs, traces) to store all the data, providing a central repository for processing and analyzing observability data, visualizing them in dashboards, and alerting.
With the introduction of cloud infrastructure, systems and applications became more ephemeral in nature, changing and adapting to workloads dynamically. Despite all these sophisticated and specialized databases, monitoring solutions found that observability data grows exponentially as the demand for higher fidelity insights increases and the complexity and the size of the infrastructure grows.
Thus, monitoring systems today face the next challenge: to keep up with the vast amount of data they are required to ingest and analyze. Monitoring systems need to scale once more!
Netdata’s Revolutionary Approach to Decentralized Monitoring
While most monitoring providers try to scale their core databases, at Netdata we decided to take a different approach:
- What if we eliminate the central core entirely?
- What if we can build a solution that spreads the data across the infrastructure, while still providing unified views of all the systems, services, and applications?
So, we built Netdata to achieve exactly that. Each of your Netdata installations is a complete monitoring solution. Each Netdata has its own high-performance time-series database (our own dbengine) and its own structured and indexed logs database (based on systemd-journald). Centralization points are required only to the degree users have operational reasons to do so (e.g., ephemeral nodes, high availability, sensitive or weak systems). Multiple independent centralization points may co-exist across the infrastructure.
Thus, by keeping data as close to the edge as possible, Netdata manages to build observability pipelines of extreme performance and capacity, while being more efficient and lightweight than traditional monitoring agents.
Today, Netdata is the only monitoring solution that endorses and delivers high fidelity insights as a standard. All data is collected per second. No cherry-picking of data sources. A.I. and machine-learning-based anomaly detection for everything.
Since granularity (resolution) and cardinality (number of metrics) are now decoupled from performance, scalability, and cost, we went a step further to simplify monitoring significantly. Instead of requiring users to configure the monitoring system metric by metric, chart by chart, and alert by alert, we armed Netdata with:
- auto-detection and auto-discovery of all data sources,
- fully automated infrastructure-level dashboards,
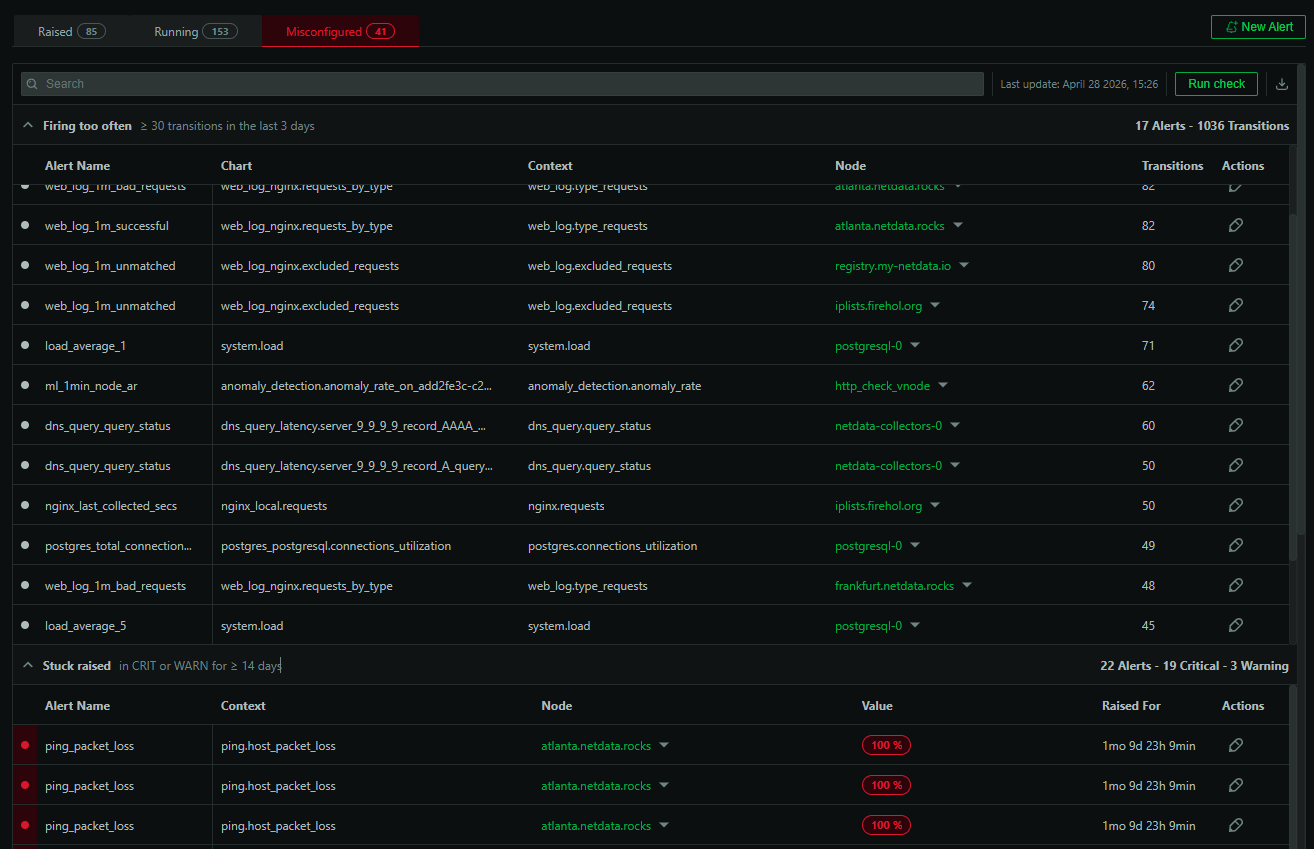
- hundreds of pre-configured alerts monitoring the whole infrastructure for common error conditions and misconfiguration,
- and at the same time, we added the ability to slice and dice any dataset without using a query language, by using simple controls available on all charts.
All these innovations completely flipped the user experience, the troubleshooting process, the skills required, and the overall cost of observability.
Netdata is the only truly decentralized and distributed monitoring solution that gives you the freedom to monitor everything in high resolution, in an integrated environment of extreme performance and capacity, without compromising scalability, or cost. Try it out today.