
Another release of the Netdata Monitoring solution is here!
- Release Highlights
-
DBENGINE v2 The new open-source database engine for Netdata Agents, offering huge performance, scalability and stability improvements, with a fraction of memory footprint!
-
FUNCTION: Processes Netdata beyond metrics! We added the ability for runtime functions, that can be implemented by any data collection plugin, to offer unlimited visibility to anything, even not-metrics, that can be valuable while troubleshooting.
-
Events Feed Centralized view of Space and Infrastructure level events about topology changes and alerts.
-
NOTIFICATIONS: Slack, PagerDuty, Discord, Webhooks Netdata Cloud now supports Slack, PagerDuty, Discord, Webhooks.
-
Role-based access model Netdata Cloud supports more roles, offering finer control over access to infrastructure.
-
Release v1.38
- Integrations New and improved plugins for data collection, alert notifications, and data exporters.
- Health Monitoring and Alerts Notification Engine Changes to the Netdata Health Monitoring and Notifications engine.
- Visualizations / Charts and Dashboards
- Database
- Streaming and Replication
- API
- Machine Learning
- Installation and Packaging
- Documentation and Demos
- Administration
- Other Notable Changes
- Deprecation notice
- Netdata Agent release meetup
- Support options
- Acknowledgements
❗We are keeping our codebase healthy by removing features that are end-of-life. Read the deprecation notice to check if you are affected.
Netdata open-source growth
- Almost 62,000 GitHub Stars
- Over four million monitored servers
- Almost 88 million sessions served
- Over 600 thousand total nodes in Netdata Cloud
Release highlights
Dramatic performance and stability improvements, with a smaller agent footprint
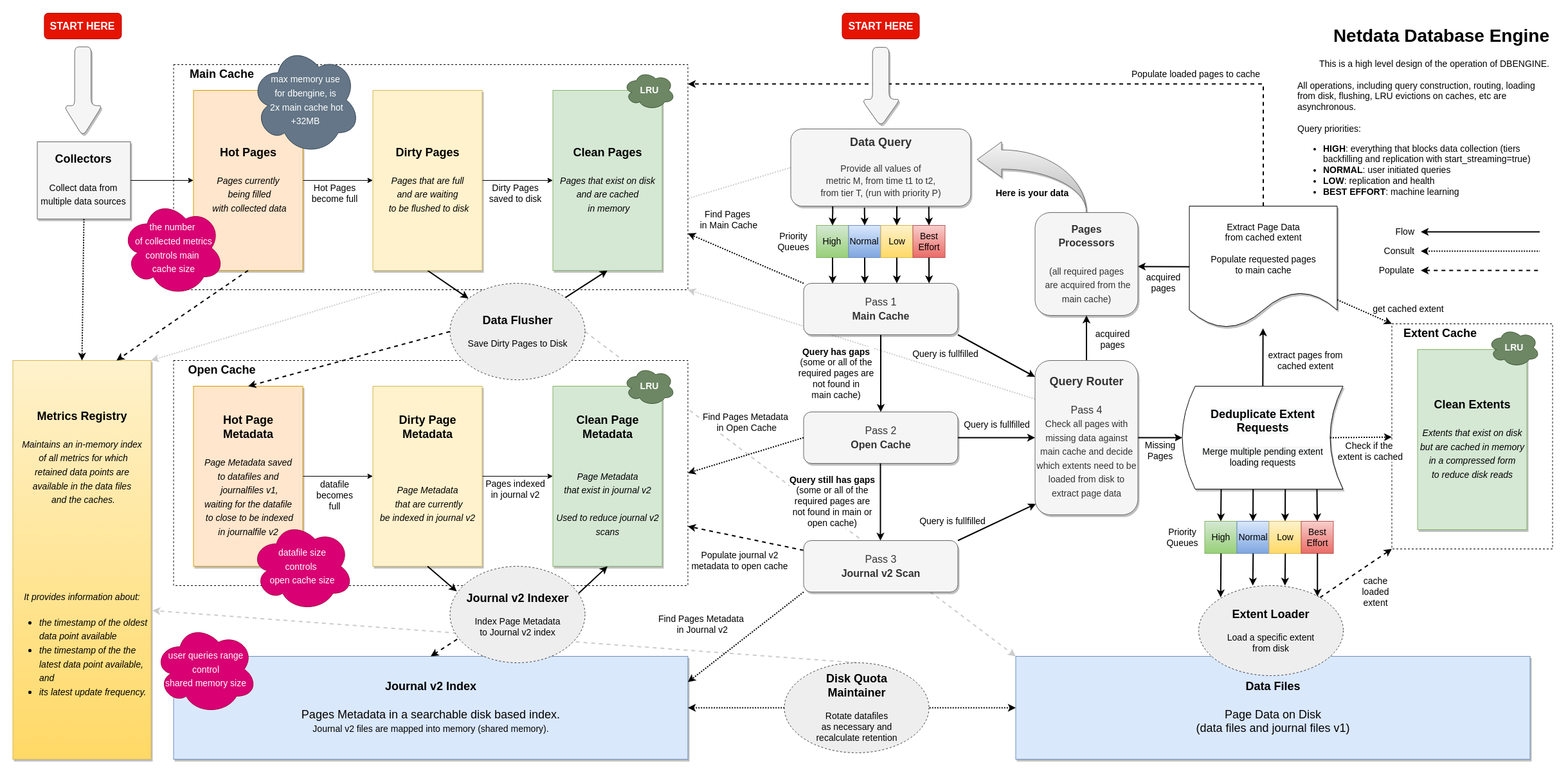
We completely reworked our custom-made, time series database (dbengine), resulting in stunning improvements to performance, scalability, and stability, while at the same time significantly reducing the agent memory requirements.
On production-grade hardware (e.g. 48 threads, 32GB ram) Netdata Agent Parents can easily collect 2 million points/second while servicing data queries for 10 million points / second, and running ML training and Health querying 1 million points / second each!
For standalone installations, the 64bit version of Netdata runs stable at about 150MB RAM (Reside Set Size + SHARED), with everything enabled (the 32bit version at about 80MB RAM, again with everything enabled).

Read more about the changes over dbengine v1
Key highlights of the new dbengine
Disk based indexing
We introduced a new journal file format (*.jnfv2) that is way faster to initialize during loading. This file is used as a disk-based index for all metric data available on disk (metrics retention), reducing the memory requirements of dbengine by about 80%.
New caching
3 new caches (main cache, open journal cache, extent cache) have been added to speed up queries and control the memory footprint of dbengine.
These caches combined, offer excellent caching even for the most demanding queries. Cache hit ratio now rarely falls bellow 50%, while for the most common use cases, it is constantly above 90%.
The 3 caches support memory ballooning and autoconfigure themselves, so they don’t require any user configuration in netdata.conf.
At the same time, their memory footprint is predictable: twice the memory of the currently collected metrics, across all tiers. The exact equation is:
METRICS x 4KB x (TIERS - 1) x 2 + 32MB
Where:
METRICS x 4KB x TIERSis the size of the concurrently collected metrics.4KBis the page size for each metric.TIERSis whatever configured for[db].storage tiersinnetdata.conf; use(TIERS - 1)when using 3 tiers or more (3 is the default).x 2 + 32MBis the commitment of the new dbengine.
The new combination of caches makes Netdata memory footprint independent of retention! The amount of metric data on disk, does not any longer affect the memory footprint of Netdata, it can be just a few MB, or even hundreds of GB!
The caches try to keep the memory footprint at 97% of the predefined size (i.e. twice the concurrently collected metrics size). They automatically enter a survival mode when memory goes above this, by paralleling LRU evictions and metric data flushing (saving to disk). This system has 3 distinct levels of operation:
- aggressive evictions, when caches are above 99% full; in this mode cache query threads are turned into page evictors, trying to remove the least used data from the caches.
- critical evictions, when caches are above 101% full; in this mode every thread that accesses the cache is turned into a batch evictor, not leaving the cache until the cache size is again within acceptable limits.
- flushing critical, when too many unsaved data reside in memory; in this mode, flushing is parallelized, trying to push data to disk as soon as possible.
The caches are now shared across all dbengine instances (all tiers).
LRU evictions are now smarter: the caches know when metrics are referenced by queries or by collectors and favor the ones that have been used recently by data queries.
New dbengine query engine
The new dbengine query engine is totally asynchronous, working in parallel while other threads are processing metrics points. Chart and Context queries, but also Replication queries, now take advantage of this feature and ask dbengine to preload metric data in advance, before they are actually needed. This makes Netdata amazingly fast to respond in data queries, even on busy parent that at the same time collect millions of points.
At the same time we support prioritization of queries based on their nature:
- High priority queries, are all those that can potentially block data collection. Such queries are tiers backfilling and the last replication query for each metric (immediately after which, streaming is enabled).
- Normal priority queries, are the ones that are initiated by users.
- Low priority queries, are the ones that can be delayed without affecting quality of the results, like Health and Replication queries.
- Best effort queries, are the lowest priority ones and are currently used by ML training queries.
Starvation is prevented by allowing 2% of lower priority queries for each higher priority queue. So, even when backfilling is performed full speed at 15 million points per second, user queries are satisfied up to 300k points per second.
Internally all caches are partitioned to allow parallelism up to the number of cores the system has available. On busy parents with a lot of data and capable hardware it is now easy for Netdata to respond to queries using 10 million points per second.
At the same time, extent deduplication has been added, to prevent the unnecessary loading and uncompression of an extent multiple times in a short time. This works like this: while a request to load an extent is in flight, and up to the time the actual extent has been loaded and uncompressed in memory, more requests to extract data from it can be added to the same in flight request! Since dbengine trying to keep metrics of the same charts to the same extent, combined with the feature we added to prepare ahead multiple queries, this extent deduplication now provides hit of above 50% for normal chart and context queries!
Metrics registry
A new metrics registry has been added that maintains an index of all metrics in the database, for all tiers combined.
Initialization is the metrics registry is fully multithreaded utilizing all the resources available on busy parents, improving start-up times significantly.
This metrics registry is now the only memory requirement related to retention. It keeps in memory the first and the last timestamps, along with a few more metadata, of all the metrics for which retention is available on disk. The metrics registry needs about 150 bytes per metric.
Streaming
The biggest change in streaming is that the parent agents now inherit the clock of their children, for their data. So, all timestamps about collected metrics reflect the timestamps on the children that collected them. If a child clock is ahead of the parent clock, the parent will still accept collected points for the child, and it will process them and save them, but on parent node restart the parent will refuse to load future data about a child database. This has been done in such a way that if the clock of the child is fixed (by adjusting it backwards), after a parent restart the child will be able to push fresh metrics to the parent again.
Related to the memory footprint of the agent, streaming buffers were ballooning up to the configured size and remained like that for the lifetime of the agent. Now the streaming buffers are increased to satisfy the demand, but then they are again decreased to a minimum size. On busy parents this has a significant impact on the overall memory footprint of the agent (10MB buffer per node x 200 child nodes on this parent, is 2GB - now they return to a few KB per node).
Active-Active parent clusters are now more reliable by detecting stale child connections and disconnecting them.
Several child to parent connection issues have been solved.
Replication
Replication now uses the new features of dbengine and pipelines queries preparation and metric data loading, improving drastically its performance. At the same time, the replication step is now automatically adjusted to the page size of dbengine, allowing replication to use the data are already loaded by dbengine and saving resources at the next iteration.
A single replication thread can now push metrics at a rate of above 1 million points / second on capable hardware.
Solved an issue with replication, where if the replicated time-frame had a gap at the beginning of the replicated period, then no replication was performed for that chart. Now replication skips the gap and continues replicating all the points available.
Replication does not replicate now empty points. The new dbengine has controls in place to insert gaps into the database which metrics are missing. Utilizing this feature, we have now stopped replicating empty points, saving bandwidth and processing time.
Replication was increasing the streaming buffers above the configured ones, when big replication messages had to fit in it. Now, instead of increasing the streaming buffers, we interrupt the replication query at a point that the buffer will be sufficient to accept the message. When queries are interrupted like this, the remaining query is then repeated until all of it executed.
Replication and data collection are now synchronized atomically at the sending side, to ensure that the parent will not have gaps at the point the replication ends and streaming starts.
Replication had discrepancies when the db mode was not dbengine. To solve these discrepancies, combined with the storage layer API changes introduced by the new dbengine, we had to rewrite them to be compliant. Replication can now function properly, without gaps at the parents, even when the child has db mode alloc, ram, save or map.
Netdata startup and shutdown
Several improvements have been performed to speed up agent startup and shutdown. Combined with the new dbengine, now Netdata starts instantly on single node installations and uses just a fraction of the time that was needed by the previous stable version, even on very busy parents with huge databases (hundreds of GB).
Special care has been taken to ensure that during shutdown the agent prioritizes dbengine flushing to disk of any unsaved data. So, now during shutdown, data collection is first stopped and then the hot and dirty pages of the main cache are flushed to disk before proceeding with other cleanup activities.
Functions
After the groundwork done on the Netdata Agent in v1.37.0, Netdata Agent collectors are able to expose functions that can be executed on-demand, at run-time, by the data collecting agent, even when queries are executed via a Netdata Agent Parent. We are now utilizing this capability to provide the first of many powerful features via the Netdata Cloud UI.
Netdata Functions on Netdata Cloud allow you to trigger specific routines to be executed by a given Agent on request. These routines can range from a simple reader that fetches real time information to help you troubleshoot (like the list of currently running processing, currently running db queries, currently open connections, etc.), to routines that trigger an action on your behalf (restart a service, rotate logs, etc.), directly on the node. The key point is to remove the need to open an ssh connection to your node to execute a command like top while you are troubleshooting.
The routines are triggered directly from the Netdata Cloud UI, with the request going through the secure, already established by the agent Agent-Cloud Link (ACLK). Moreover, unlike many of the commands you’d issue from the shell, Netdata Functions come with powerful capabilities like auto-refresh, sorting, filtering, search and more! And, as everything about Netdata, they are fast!
What functions are currently available?
At the moment, just one, to display detailed information on the currently running processes on the node, replacing top and iotop. The function is provided by the apps.plugin collector.

Read more about the Netdata Functions
How do functions work?
The nitty-gritty details are in PR “Allow netdata plugins to expose functions for querying more information about specific charts” (#13720). In short:
- Each plugin can register to the main Netdata agent process a set of functions that it supports for the host it runs (global functions), or a given chart (chart local functions), along with the acceptable parameters and parameter values for each one. The plugin also defines the format of the response it will provide, if a certain function is called.
- The agent makes the information available via its API, but also returns the available functions for a chart in the response of every
dataquery call, that returns the metric values. - To execute a registered function, one needs to call the
/api/v1/functionsendpoint (see it in swagger). However, for security reasons, the specific call is protected, meaning it is disabled from the HTTP API and will return a 403. Only the cloud can call the particular endpoint and only via the secure and protected Agent-Cloud Link (ACLK). - When the endpoint is called, the agent daemon invokes the requested function on the collector via a new plugins.d API endpoint. Note that the
plugins.dAPI has for the first time become bidirectional, precisely to support the daemon querying this type of information.
How do functions work with streaming?
The definitions of functions are transmitted to parent nodes via streaming, so that the parents know all the functions available on all child database they maintain. This works even across multiple levels of parents.
When a parent node is connected to Netdata Cloud, it is capable of triggering the call to the respective child node, to run any of its functions. When multiple parents are involved, all of them will propagate the request to the right child to execute the function.
Why are they available only on Netdata Cloud?
Since these functions are able to execute routines on the node and expose information beyond metric data (even action buttons could be implemented using functions), our concern is to ensure no sensitive information or disruptive actions are exposed through the unprotected Agent’s API.
Since Netdata Cloud provides all the infrastructure to authenticate users, assign roles to them and establishes a secure communication channel to Netdata Agents ACLK, this concern is addressed. Netdata Cloud is free forever for everyone, providing a lot more than just the agent dashboard and is our main focus of development for new visualization features.
Next steps
For even more details please check our docs.
If you have ideas or requests for other functions:
- Participate in the relevant GitHub Discussion
- Open a feature request on the Netdata Cloud repo
- Engage with our community on the Netdata discord server.
Events feed
Coming by Feb 15th
The Events feed is a powerful new feature that tracks events that happen on your infrastructure, or in your Space. The feed lets you investigate events that occurred in the past, which is obviously invaluable for troubleshooting. Common use cases are ones like when a node goes offline, and you want to understand what events happened before that. A detailed event history can also assist in attributing sudden pattern changes in a time series to specific changes in your environment.
We start from humble beginnings, capturing topology events (node state transitions) and alert state transitions. We intend to expand the events we capture to include infrastructure changes like deployments or services starting/stopping and we plan to provide a way to display the events in the standard Netdata charts.
What are the available events?
⚠️ Based on your space’s plan different allowances are defined to query past data. The length of the history is provided in this table:
| Domains of events | Community | Pro | Business |
|---|---|---|---|
| Topology events Node state transition events, e.g. live or offline. |
4 hours | 7 days | 14 days |
| Alert events Alert state transition events, can be seen as an alert history log. |
4 hours | 7 days | 90 days |
More details on the captured events
Topology events
| Event name | Description |
|---|---|
| Node Became Live | The node is collecting and streaming metrics to Cloud. |
| Node Became Stale | The node is offline and not streaming metrics to Cloud. It can show historical data from a parent node. |
| Node Became Offline | The node is offline, not streaming metrics to Cloud and not available in any parent node. |
| Node Created | The node is created, but it is still Unseen on Cloud, didn’t establish a successful connection yet. |
| Node Removed | The node was removed from the Space through the Delete action, if it becomes Live again it will be automatically added. |
| Node Restored | The node is restored, if node becomes Live after a remove action it is re-added to the Space. |
| Node Deleted | The node is deleted from the Space, see this as an hard delete and won’t be re-added to the Space if it becomes live. |
| Agent Claimed | The agent was successfully registered to Netdata Cloud and is able to connect. |
| Agent Connected | The agent connected to the Netdata Cloud MQTT server (Agent-Cloud Link established). |
| Agent Disconnected | The agent disconnected from the Netdata Cloud MQTT server (Agent-Cloud Link severed). |
| Agent Authenticated | The agent successfully authenticated itself to Netdata Cloud. |
| Agent Authentication Failed | The agent failed to authenticate itself to Netdata Cloud. |
Alert events
| Event name | Description |
|---|---|
| Node Alert State Changed | These are node alert state transition events and can be seen as an alert history log. You can see transitions to or from any of these states: Cleared, Warning, Critical, Removed, Error or Unknown |
Additional alert notification methods on Netdata Cloud
Coming by Feb 15th
Every Netdata Agent comes with hundreds of pre-installed health alerts designed to notify you when an anomaly or performance issue affects your node or the applications it runs. All these events, from all your nodes, are centralized at Netdata Cloud.
Before this release, Netdata Cloud was only dispatching centralized email alert notifications to your team whenever an alert enters a warning, critical, or unreachable state. However, the agent supported tens of notification delivery methods, which we hadn’t provided via the cloud.
We are now adding to Netdata Cloud more alert notification integration methods. We categorize them similarly to our subscription plans, as Community, Pro and Business. On this release, we added Discord (Community Plan), web hook (Pro Plan), PagerDuty and Slack (Business Plan).

More details on notifications
Notification method availability
⚠️ Netdata Cloud notification methods availability depends on your subscription plan.
| Notification methods | Community | Pro | Business |
|---|---|---|---|
| :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | |
| Discord | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
| Web hook | - | :heavy_check_mark: | :heavy_check_mark: |
| PagerDuty | - | - | :heavy_check_mark: |
| Slack | - | - | :heavy_check_mark: |
Notification method types
Notification integrations are classified based on whether they need to be configured per user (Personal notifications), or at the system level (System notifications).
Email notifications are Personal, meaning that administrators can enable or disable them globally, and each user can enable or disable them for them, per room. Email notifications are sent to the destination of the channel which is a user-specific attribute, e.g. user’s e-mail. The users are the ones who can manage what specific configurations they want for the Space / Room(s) and the desired Notification level, via their User Profile page under Notifications.
All other introduced methods are classified as System, as the destination is a target that usually isn’t specific to a single user, e.g. slack channel. These notification methods allow for fine-grain rule settings to be done by administrators. Administrators are able to specify different targets depending on Rooms or Notification level settings.
For more details please check the documentation here.
Improved role-based access model
Coming by Feb 15th
Netdata Cloud already provides a role-based-access mechanism, that allows you to control what functionalities in the app users can access. Each user can be assigned only one role, which fully specifies all the capabilities they are afforded.
With the advent of the paid plans we revamped the roles to cover needs expressed by our users, like providing more limited access to your customers, or being able to join any room. We also aligned the offered roles to the target audience of each plan. The end result is the following:
| Role | Community | Pro | Business |
|---|---|---|---|
| Administrators This role allows users to manage Spaces, War Rooms, Nodes, Users, and Plan & Billing settings. Provides access to all War Rooms in the space |
:heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
| Managers This role allows users to manage War Rooms and Users. Provides access to all War Rooms and Nodes in the space. |
- | - | :heavy_check_mark: |
| Troubleshooters This role is for users focused on using Netdata to troubleshoot, not manage entities. Provides access to all War Rooms and Nodes in the space. |
- | :heavy_check_mark: | :heavy_check_mark: |
| Observers This role is for read-only access, with restricted access to explicitly defined War Rooms and only the Nodes that appear in those War Rooms. 💡 Ideal for restricting your customer’s access to their own dedicated rooms. |
- | - | :heavy_check_mark: |
| Billing This role is for users that only need to manage billing options and see invoices, with no further access to the system. |
- | - | :heavy_check_mark: |

Integrations
Collectors
Proc
The proc plugin gathers metrics from the /proc and /sys folders in Linux
systems, along with a few other endpoints, and is responsible for the bulk of the system metrics collected and
visualized by Netdata. It collects CPU, memory, disks, load, networking, mount points, and more.
We added a “cpu” label to the per core utilization % charts. Previously, the only way to filter or group by core was to use the “instance”, i.e. the chart name. The new label makes the displayed dimensions much more user-friendly.
We fixed the issues we had with collection of CPU/memory metrics when running inside an LXC container as a systemd service.
We also fixed the missing network stack metrics, when IPv6 is disabled.
Finally, we improved how the loadavg alerts behave when the number of processors is 0, or unknown.
Apps
The apps plugin breaks down system resource usage to processes, users and user groups, by reading whole process tree, collecting resource usage information for every process found running.
We fixed the nodejs application group node, which incorrectly included node_exporter. The rule now is that the process must be called node to be included in that group.
We also added a telegraf application group.
Containers and VMs (CGROUPS)
The cgroups plugin reads information on Linux Control Groups to monitor containers, virtual machines and systemd services.
The “net” section in a cgroups container would occasionally pick the wrong / random interface name to display in the navigation menu. We removed the interface name from the cgroup “net” family. The information is available in the cloud as labels and on the agent as chart names and ids.
eBPF
The eBPF plugin helps you troubleshoot and debug how applications interact with the Linux kernel.
We improved the speed and resource impact of the collector shutdown, by reducing the number of threads running in parallel.
We fixed a bug with eBPF routines that would sometimes cause kernel panic and system reboot on RedHat 8.* family OSs. #14090, #14131
We fixed an ebpf.d crash: sysmalloc Assertion failed, then killed with SIGTERM.
We fixed a crash when building eBPF while using a memory address sanitizer.
The eBPF collector also creates charts for each running application through an integration with the apps.plugin.
This integration helps you understand how specific applications interact with the Linux kernel. In systems with many VMs (like Proxmox), this integration
can cause a large load. We used to have the integration turned on by default, with the ability to disable it from ebpf.d.conf. We have now done the opposite, having the integration disabled by default, with the ability to enable it. #14147
Windows Monitoring
We have been making tremendous improvements on how we monitor Windows Hosts. The work will be completed in the next release. For now, we can say that we have done some preparatory work by adding more info to existing charts, adding metrics for MS SQL Server, IIS in 1.37, Active Directory, ADFS and ADCS.
We also reorganized the navigation menu, so that Windows application metrics don’t appear under the generic “WMI” category, but on their own category, just like Linux applications.
We invite you to try out with these collectors either from a remote Linux machine, or using our new MSI installer, which however is not suitable for production. Your feedback will be really appreciated, as we invest on making Windows Monitoring a first class citizen of Netdata.
Generic Prometheus Endpoint Monitoring
Our Generic Prometheus Collector gathers metrics from any Prometheus endpoint that uses the OpenMetrics exposition format.
To allow better grouping and filtering of the collected metrics we now create a chart with labels per label set.
We also fixed the handling of Summary/Histogram NaN values.
TCP endpoint monitoring
The TCP endpoint (portcheck) collector monitors TCP service availability and response time.
We enriched the portcheck alarms with labels that show the problematic host and port.
HTTP endpoint monitoring
The HTTP endpoint monitoring collector (httpcheck) monitors their availability and response time.
We enriched the alerts with labels that show the slow or unavailable URL relevant to the alert.
Host reachability (ping)
The new host reachability collector replaced fping in v1.37.0.
We removed the deprecated fping.plugin, in accordance with the v1.37.0 deprecation notice.
RabbitMQ
The RabbitMQ collector monitors the open source message broker, by
querying its overview, node and vhosts HTTP endpoints.
We added monitoring of the RabitMQ queues that was available in the older Python module and fixed an issue with the new metrics.
MongoDB
We monitor the MongoDB NoSQL database serverStatus and dbStats.
To allow better grouping and filtering of the collected metrics we now create a chart per database, repl set member, shard and additional metrics. We also improved the cursors_by_lifespan_count chart dimension names, to make them clearer.
PostgreSQL
Our powerful PostgreSQL database collector has been enhanced with an improved WAL replication lag calculation and better support of versions before 10.
Redis
The Redis collector monitors the in-memory data structure store via its INFO ALL command.
We now support password protected Redis instances, by allowing users to set the username/password in the collector configuration.
Consul
The Consul collector is production ready! Consul by HashiCorp is a powerful and complex identity-based networking solution, which is not trivial to monitor. We were lucky to have the assistance of HashiCorp itself in this endeavor, which resulted in a monitoring solution of exceptional quality. Look for common blog posts and announcements in the coming weeks!
NGINX Plus
The NGINX Plus collector monitors the load balancer, API gateway, and reverse proxy built on top of NGINX, by utilizing its Live Activity Monitoring capabilities.
We improved the collector that was launched last November with additional information explaining the charts and the addition of SSL error metrics.
Elastic Search
The Elastic Search collector monitors the search engine’s instances via several of the provided local interfaces.
To allow better grouping and filtering of the collected metrics we now create a chart per node index, a dimension per health status. We also added several OOB alerts.
NVIDIA GPU
Our NVIDIA GPU Collector monitors memory usage, fan speed, PCIE bandwidth utilization, temperature, and other GPU performance metrics using the nvidia-smi cli tool.
Multi-Instance GPU (MIG) is a feature from NVIDIA that lets users partition a single GPU to smaller GPU instances. We added MIG metrics for uncorrectable errors and memory usage.
We also added metrics for voltage and PCIe bandwidth utilization percentage.
Last but not least, we significantly improved the collector’s performance, by switching to collecting data using the CSV format.
Pi-hole
We monitor Pi-hole, the Linux network-level advertisement and Internet tracker blocking application via its PHP API.
We fixed an issue with the requests failing against an authenticated API.
Network Time Protocol (NTP) daemon
The ntpd program is an operating system daemon which sets and maintains the system time of day in synchronism with Internet standard time-servers (man page).
We rewrote our previous python.d collector in go, improving its performance and maintainability.
The new collector still monitors the system variables of a local ntpd daemon and optionally the variables of its polled peers.
Similarly to ntpq, the standard NTP query program, we used the NTP Control Message Protocol over a UDP socket.
The python collector will be deprecated in the next release, with no effect on current users.
Notifications
See Additional alert notification methods on Netdata Cloud
The agents can now send notifications to Mattermost, using the Slack integration! Mattermost has a Slack-compatible API that only required a couple of additional parameters. Kudos to @je2555!
Exporters
Netdata can export and visualize Netdata metrics in Graphite.
Our exporter was broken in v1.37.0 due to our host labels for ephemeral nodes. we fixed the issue with #14105.
Alerts and Notification Engine
Health Engine
To improve performance and stability, we made health run in a single thread.
Notifications Engine
The agent alert notifications are controlled by the configuration file health_alarm_notify.conf. Previously, if one used the |critical modifier, the recipients would always get at least 2 notifications: critical and clear. There was no way how to stop sending clear/warning notifications afterwards. We added the |nowarn and |noclear notification modifiers, to allow users to really receive just the transitions to the critical state.
We also fixed the broken redirects from alert notifications to cleared alerts.
Alerts
Chart labels in alerts
We constantly strive to improve the clarity of the information provided by the hundreds of out of the box alerts we provide.
We can now provide more fine-tuned information on each alert, as we started using specific chart labels instead of family.
To provide the capability we also had to change the format of alert info variables to support the more complex syntax.
Globally enable/disable specific alerts
Administrators can now globally, permanently disable specific OOB alerts via netdata.conf. Previously the options where to edit individual alert configuration files, or to use the health management API.
The [health] section of netdata.conf now support the setting enabled_alarms. It’s value defines which alarms to load from both user and stock directories. The value is a simple pattern list of alarm or template names, with the default value of *, meaning that all alerts are loaded. For example, to disable specific alarms, you can provide enabled alarms = !oom_kill *, which will load all alarms except oom_kill.
Visualizations / Charts and Dashboards
Our main focus for visualization is on the Netdata Cloud Overview dashboard. This dashboard is our flagship, on which everything we do, all slicing and dicing capabilities of Netdata, are added and integrated. We are working hard to make this dashboard powerful enough, so that the need to learn a query language for configuring and customizing monitoring dashboards, will be eliminated.
On this release, we virtualized all items on the dashboard, allowing us to achieve exceptional performance on page rendering. In previous releases there were issues on dashboards with thousands of charts. Now the number of items in the page is irrelevant!
To make slicing and dicing of data easier, we ordered the on-chart selectors in a way that is more natural for most users:

This bar above the chart now describes the data presented, in plain English: On 6 out of 20 Nodes, group by dimension, the SUM() of 23 Instances, using All dimensions, each as AVG() every 3s
A tool-tip provides more information about the missing nodes:

And the drop-down menu now shows the exact nodes that contributed data to the query, together with a short explanation on why nodes did not provide any data:

Additionally, the pop-out icon next to each node can be used to jump to the single node dashboard of this node.
All the slicing and dicing controls (Nodes, Dimensions, Instances), now support filtering. As shown above, there is a search box in the drop-down and a tick-mark to the left of each item in the list, which can be used to instantly filter the data presented.
At the same time, we re-worked most of the Netdata collectors to add labels to the charts, allowing the chart to be pivoted directly from the group by drop-down menu. On the following image, we see the same chart as above, but now the data have been grouped by the label device, the values of which became dimensions of the chart.

The data can be instantly be filtered by original dimension (reads and writes in this example), like this:

or even by a specific instance (disk in this example), like this:

On the Instances drop down list (shown above), the pop-out icon to the right of each instance can be used to quickly jump to the single node dashboard, and we also made this function automatically scroll the dashboard to relative chart’s position and filter on that chart the specific instance from which the jump was made.
Our goal is to polish and fine tune this interface, to the degree that it will be possible to slice and dice any data, without learning a query language, directly from the dashboard. We believe that this will simplify monitoring significantly, make it more accessible to people, and it will eventually allow all of us to troubleshoot issues without any prior knowledge of the underlying data structures.
At the same time, we worked to improve switching between rooms and tabs within a room, by saving the last visible chart and the selected page filters, we are restored automatically when the user switches back to the same room and tab.
For the ordering of the sections and subsections on the dashboard menu, we made a change to allow currently collected charts to overwrite the position of the section and subsection (we call it priority). Before this change, archived metrics (old metrics that are retained due to retention), were participating in the election of the priority for a section or subsection and because the retention Netdata maintains by default is more than a year, changes to the priority were never propagated to the UI.
Bug fixes
We fixed:
- The alignment of the anomaly rate pop-down chart
- The width of the right-hand menu bar
- A crash when filtering dimensions
- The warning when a user tries to leave the last space
- The filters of the Metric Correlation screen incorrectly persisting
- The wrong value being shown for whether a node has ML enabled
- The node filter on the anomalies tab
- The visibility of the chart actions menu that appears inside a chart
- Logstash metrics not being displayed in Netdata Cloud
- The home tab not being updated with the correct number of nodes, after deleting a node
Real Time Functions
See Functions
Events Feed
See Events Feed.
Database
New database engine
See Dramatic performance and stability improvements, with a smaller agent footprint
Metadata sync
Saving metadata to SQLite is now faster. Metadata saving starts asynchronously when the agent starts and continues as long as there are metadata to be saved. We implemented optimizations by grouping queries into transactions. At runtime this grouping happens per chart, which on shutdown it happens per host. These changes made metadata syncing up to 4x faster.
Streaming and Replication
We introduced very significant reliability and performance improvements to the streaming protocol and the database replication. See Streaming, Replication.
At the same time, we fixed SSL handshake issues on established SSL connections, provide stable streaming SSL connectivity between Netdata agents.
API
Data queries for charts and contexts now have the following additional features:
- The query planner that decided which tier to use for each query, now prefers higher tiers, to speed up queries
- Joining of multiple tiers to the same query now prefers higher resolution tiers and joining is accurate. To achieve that, behind the scenes the query planner expands the query of each tier to overlap with its previous and next and at the time they intersect, it reads points from all the overlapping tiers to decide how exactly the join should happen.
- Data queries now utilize the parallelism of the new dbengine, to pipeline query preparation of the dimensions of the chart or context being queried, and then preloading metric data for dimensions that are in the pipeline.
Machine Learning
We have been busy at work under the hood of the Netdata agent to introduce new capabilities that let you extend the “training window” used by Netdata’s native anomaly detection capabilities.

We have introduced a new ML parameter called number of models per dimension which will control the number of most recently trained models used during scoring.
Below is some pseudo-code of how the trained models are actually used in producing anomaly bits (which give you an “anomaly rate” over any window of time) each second.
# preprocess recent observations into a "feature vector"
latest_feature_vector = preprocess_data([recent_data])
# loop over each trained model
for model in models:
# if recent feature vector is considered normal by any model, stop scoring
if model.score(latest_feature_vector) < dimension_anomaly_score_threshold:
anomaly_bit = 0
break
else:
# only if all models agree the feature vector is anomalous is it considered anomalous by netdata
anomaly_bit = 1
The aim here is to only use those additional stored models when we need to. So essentially once one model suggests a feature vector looks anomalous we check all saved models and only when they all agree that something is anomalous does the anomaly bit get to be finally set to 1 to signal that Netdata considered the most recent feature vector unlike anything seen in all the models (spanning a wider training window) checked.
Read more in this blog post!
We now create ML charts on child hosts, when a parent runs a ML for a child. These charts use the parent’s hostname to differentiate multiple parents that might run ML for a child.
Finally, we refactored the ML code and added support for multiple KMeans models.
Installation and Packaging
New hosting of build artifacts
We are always looking to improve the ways we make the agent available to users. Where we host our build artifacts is an important piece of the puzzle, and we’ve taken some significant steps in the past couple of months.
New hosting of nightly build artifacts
As of 2023-01-16, our nightly build artifacts are being hosted as GitHub releases on the new https://github.com/netdata/netdata-nightlies/ repository instead of being hosted on Google Cloud Storage. In most cases, this should have no functional impact for users, and no changes should be required on user systems.
New hosting of native package repositories
As part of improving support for our native packages, we are migrating off of Package Cloud to our own self-hosted package repositories located at https://repo.netdata.cloud/repos/. This new infrastructure provides a number of benefits, including signed packages, easier on-site caching, more rapid support for newly released distributions, and the ability to support native packages for a wider variety of distributions.
Our RPM repositories have already been fully migrated and the DEB repositories are currently in the process of being migrated.
Official Docker images now available on GHCR and Quay
In addition to Docker Hub, our official Docker images are now available on GHCR and Quay. The images are identical across all three registries, including using the same tagging.
You can use our Docker images from GHCR or Quay by either configuring them as registries with your local container tooling, or by using ghcr.io/netdata/netdata or quay.io/netdata/netdata instead of netdata/netdata.
kickstart
The directives --local-build-options and --static-install-options used to only accept a single option each. We now allow multiple options to be entered.
We renamed the --install option to --install-prefix, to clarify that it affects the directory under which the Netdata agent will be installed.
To help prevent user errors, passing an unrecognized option to the kickstart script now results in a fatal error instead of just a warning.
We previously used grep to get some info on login or group, which could not handle cases with centralized authentication like Active Directory or FreeIPA or pure LDAP. We now use “getent group” to get the group information.
RPMs
We fixed the required permissions of the cgroup-network and ebpf.plugin in RPM packages.
OpenSUSE
We fixed the binary package updates that were failing with an error on “Zypper upgrade”.
FreeBSD
We fixed the missing required package installation of “tar”.
MacOS
We fixed some crashes on MacOS.
Proxmox
Netdata on Proxmox virtualization management servers must be allowed to resolve VM/container names and read their CPU and memory limits.
We now explicitly add the netdata user to the www-data group on Proxmox, so that users don’t have to do it manually.
Other
We fixed the path to “netdata.pid” in the logrotate postrotate script, which causes some errors during log rotation.
We also added pre gcc v5 support and allowed building without dbengine.
Documentation and Demos
Learn
We have been working hard to revamp Netdata Learn. We are revising not just its structure and content, but also the
Continuous Integration processes around it. We’re getting close to the finish line, but you may notice that we currently publish two versions; 1.37.x
is frozen with the state of the docs as of the 1.37.1 release, and the nightly version has the target experience.
While not yet ready for production, the nightly version is the only place where information on the latest features and changes is available.
The following screenshot shows how you can switch between versions.

Be aware that you may encounter some broken links or missing pages while we are sorting out the several hundred markdown documents and several thousand links they include. We ask for your patience and expect that by the next release we’ll have properly launched the new, more easy to navigate and use version.
Demo space
The Netdata Demo space on Netdata Cloud is constantly being updated with new rooms, for various use cases. You don’t even need a cloud account to see our powerful infrastructure monitoring in action, so what are you waiting for?

Administration
Logging
We have improved the readability of our main error log file error.log, by moving data collection specific log messages to collector.log. For the same reason we reduced the log verbosity of streaming connections.
New configuration editing script
We reimplemented the edit-config script we install in the user config directory, adding a few new features, and fixing a number of outstanding issues with the previous script.
Overall changes from the existing script:
- Error messages are now clearly prefixed with
ERROR:instead of looking no different from other output from the script. - We now have proper support for command-line arguments. In particular,
edit-config --helpnow properly returns usage information instead of throwing an error. Other supported options are--filefor explicitly specifying the file to edit (using this is not required, but we should ideally encourage it), and--editorto specify an editor of choice on the command-line. - We now can handle editing configuration for a Docker container on the host side, instead of requiring it to be done in the container. This is done by copying the file out of the container itself. The script includes primitive auto-detection that should work in most common cases, but the user can also use the new
--containeroption to bypass the auto-detection and explicitly specify a container ID or name to use. Supports both Docker and Podman. - Instead of templating in the user config directory at build time, the script now uses the directory it was run from as the target for copying stock config files to. This is required for the above-mentioned Docker support, and also makes it a bit easier to test the script without having to do a full build of Netdata. Users can still override this by setting
NETDATA_USER_CONFIG_DIRin the environment, just like with the old script. - Similarly, instead of templating the stock config directory at build time, we now determine it at runtime by inspecting the
.environmentfile created by the install, falling back first to inferring the location from the script’s path and if that fails using the ‘default’ of/usr/lib/netdata/conf.d. From a user perspective, this changes nothing for any type of install we officially support and for any third-party packages I know of. This results in a slight simplification of the build code, as well as making testing of the script much easier (you can now literally just copy it to the right place, and it should work). Users can still override this by settingNETDATA_STOCK_CONFIG_DIR. - Instead of listing all known files in the help text, we now require the user to run the script with the
--listoption. This has two specific benefits:- It ensures that the actual usage information won’t end up scrolled off the top of the screen by the list of known files.
- It avoids the expensive container checks and stock config directory computation when the user just needs the help output.
- We now do a quick check of the validity of the editor (either auto-detected or user-supplied) instead of just blindly trusting that it’s usable. This should not result in any user-visible changes, but will provide a more useful error message if the user mistypes the name of their editor of choice.
- Instead of blindly excluding paths starting with
/or., we now do a proper prefix check for the supplied file path to make sure it’s under the user config directory. This provides tow specific benefits:- We no longer blindly copy files into directories that are not ours. For example, with the existing script, you can do
/etc/netdata/edit-config apps_groups.conf, and it will blindly copy the stockapps_groups.conffile to the current directory. With the new script, this will throw an error instead. - Invoking the script using absolute paths that point under the user config directory will work properly. In particular, this means that you do not need to be in the user config directory when invoking the script, provided you use a proper path. Running
netdata/edit-config netdata/apps_groups.confwhen in/etcwill now work, and/etc/netdata/edit-config /etc/netdata/apps_groups.confwill work from anywhere on the system.
- We no longer blindly copy files into directories that are not ours. For example, with the existing script, you can do
- If the requested file does not exist, and we do not provide a stock version of it, the script will now create an empty file instead of throwing an error. This is intended to allow it to behave better when dealing with configuration for third-party plugins (we may also want to define a standard location for third party plugins to store their stock configuration to improve this further, but that’s out of scope for this PR).
Netdata Monitoring
The new Netdata Monitoring section on our dashboard has dozens of charts detailing the operation of Netdata. All new components have their charts, dbengine, metrics registry, the new caches, the dbengine query router, etc.
At the same time, we added a chart detailing the memory used by the agent and the function it is used for. This was the hardest to gather, since information was spread all over the place, but thankfully the internals of the agents have changed drastically in the last few months, allowing us to have a better visibility on memory consumption. At its heart, the agent is now mainly an array allocator (ARAL) and a dictionary (indexed and ordered lists of objects), carefully crafted to achieve their maximum performance when multithreaded. Everything we do, from data collection, to health, streaming, replication, etc., is actually business logic on top of these elements.
CLI
netdatacli version now returns the version of netdata.
Other Notable Changes
Netdata Paid Subscriptions
Coming by Feb 15th
At Netdata we take pride in our commitment to the principle of providing free and unrestricted access to high-quality monitoring solutions. We offer our free SaaS offering - what we call the Community plan - and the Open Source Agent, which feature unlimited nodes and users, unlimited metrics, and retention, providing real-time, high-fidelity, out-of-the-box infrastructure monitoring for packaged applications, containers, and operating systems.
We also start providing paid subscriptions, designed to provide additional features and capabilities for businesses that need tighter and customizable integration of the free monitoring solution to their processes. These are divided into three different plans: Pro, Business, and Enterprise. Each plan offers a different set of features and capabilities to meet the needs of businesses of different sizes and with different monitoring requirements.
You can change your plan at any time. Any remaining balance will be credited to your account, even for yearly plans. Netdata designed this in order to respect the unpredictability of world dynamics. Less anxiety about choosing the right commitments in order to save money in the long run.

The paid Netdata Cloud plans work as subscriptions and overall consist of:
- A flat fee component (price per space)
- An on-demand, metered component, that is related to the usage of Netdata Cloud. For us, usage is directly linked to the number of nodes you have running, regardless of how many metrics each node collects. (see details below).
Netdata provides two billing frequency options:
- Monthly - Pay as you go, where we charge both the flat fee and the on-demand component every month
- Yearly - Annual prepayment, where we charge upfront the flat fee and committed amount related to your estimated usage of Netdata (see details below)
The detailed feature list and pricing in available in netdata.cloud/pricing.
More details on usage pricing
Running nodes and billing
The only dynamic variable we consider for billing is the number of concurrently running nodes or agents. We only charge you for your active running nodes. We obviously don’t count offline nodes, which were connected in a previous month and are currently offline, with their metrics unavailable. But we go further and don’t count stale nodes either, which are available to query through a Netdata parent agent but are not actively collecting metrics at the moment.
To ensure we don’t overcharge any user due to sporadic spikes throughout a month or even at a certain point in a day we:
- Calculate a daily P90 count of your running nodes. We take a daily snapshot of your running nodes, and using the node state change events (live, offline) we guarantee that a daily P90 figure is calculated to remove any temporary spikes within the day.
- Do a running P90 calculation from the start to the end of the monthly billing cycle. This way, we guarantee that we remove spikes that happened in just a couple of days within a single month.
:note: Even if you have a yearly billing frequency, we track the p90 counts monthly, to charge any potential overage over your committed nodes.
Committed nodes
When you subscribe to a Yearly plan you need to specify the number of nodes that you commit to. in addition to the discounted flat fee, you then get a 25% discount on the per node fee, as you’re also committing to have those connected for a year. The charge for the committed nodes is part of your annual prepayment (node discounted price x committed nodes x 12 months).
If in a given month your usage is over these committed nodes, we charge the undiscounted cost per node for the overage.
Agent-Cloud link support for authenticated proxies
The Agent-Cloud link (ACLK) is the mechanism responsible for securely connecting a Netdata Agent to your web browser
through Netdata Cloud. The ACLK establishes an outgoing secure WebSocket (WSS) connection to Netdata Cloud on port
443. The ACLK is encrypted, safe, and is only established if you connect your node.
We have always supported unauthenticated HTTP proxies for the ACLK. We have now added support for HTTP Basic authentication.
We also fixed a race condition on the ACLK query thread startup.
Deprecation notice
The following items will be removed in our next minor release (v1.39.0):
Patch releases (if any) will not be affected.
| Component | Type | Will be replaced by |
|---|---|---|
| python.d/ntpd | collector | go.d/ntpd |
| python.d/proxysql | collector | go.d/proxysql |
| python.d/rabbitmq | collector | go.d/rabbitmq |
| python.d/nvidia_smi | collector | go.d/nvidia_smi |
Deprecated in this release
In accordance with our previous deprecation notice, the following items have been removed in this release:
| Component | Type | Replaced by |
|---|---|---|
| python.d/dockerd | collector | go.d/docker |
| python.d/logind | collector | go.d/logind |
| python.d/mongodb | collector | go.d/mongodb |
| fping | collector | go.d/ping |
We also removed support for Fedora 35, OpenSuse Leap 15.3 and Fedora 36 ARMv7 native packages.
Netdata Agent Release Meetup
Join the Netdata team on the 7th of February, at 17:00 UTC for the Netdata Agent Release Meetup.
Together we’ll cover:
- Release Highlights.
- Acknowledgements.
- Q&A with the community.
RSVP now - we look forward to meeting you.
Support options
As we grow, we stay committed to providing the best support ever seen from an open-source solution. Should you encounter an issue with any of the changes made in this release or any feature in the Netdata Agent, feel free to contact us through one of the following channels:
- Netdata Learn: Find documentation, guides, and reference material for monitoring and troubleshooting your systems with Netdata.
- GitHub Issues: Make use of the Netdata repository to report bugs or open a new feature request.
- GitHub Discussions: Join the conversation around the Netdata development process and be a part of it.
- Community Forums: Visit the Community Forums and contribute to the collaborative knowledge base.
- Discord Server: Jump into the Netdata Discord and hang out with like-minded sysadmins, DevOps, SREs, and other troubleshooters. More than 1400 engineers are already using it!
Acknowledgements
We would like to thank our dedicated, talented contributors that make up this amazing community. The time and expertise that you volunteer are essential to our success. We thank you and look forward to continuing to grow together to build a remarkable product.
- @je2555 for enabling alert notifications to Mattermost using Slack-compatible webhooks.
- @rex4539 for fixing various typos in documentation.
- @artemsafiyulin for fixing the replication lag calculation of the postgreSQL collector.
- @vobruba-martin for adding
|nowarnand|noclearnotification modifiers to agent notifications. - @ghanapunq for adding PCIe bandwidth utilization metrics to NVIDIA GPU monitoring.
- @Kerleyark and @mikerenfro for verifying that the CSV format significantly improves the performance of the NVIDIA GPU collector.
- @martindue for fixing the negative temperatures bug in 1-wire sensor monitoring.


