









As adoption of container infrastructure grows in popularity, we’re continuing to focus on the most effective ways users can quickly and easily deploy container monitoring to instantly get access to deep, real-time insights. Agent release 1.23 introduces service discovery for Kubernetes clusters, monitoring for individual nodes, and eBPF monitoring per application on an event frequency for quickly identifying the root cause. Quickly shed light on your infrastructure performance with these new features!
Service discovery and visualizations for Kubernetes clusters
Deploying and monitoring performance for an entire Kubernetes cluster can be complex. To simplify the process, we’ve added service discovery functionality to eliminate complex configuration, in addition to more advanced monitoring for viewing activity inside containers.Service discovery identifies k8s pods running on a cluster and immediately starts monitoring system performance. All containers are identified, regardless of complexity. Each metric is monitored with low-latency, per-second granularity and displayed in a comprehensive dashboard enabling users to anticipate problems and discover bottlenecks.
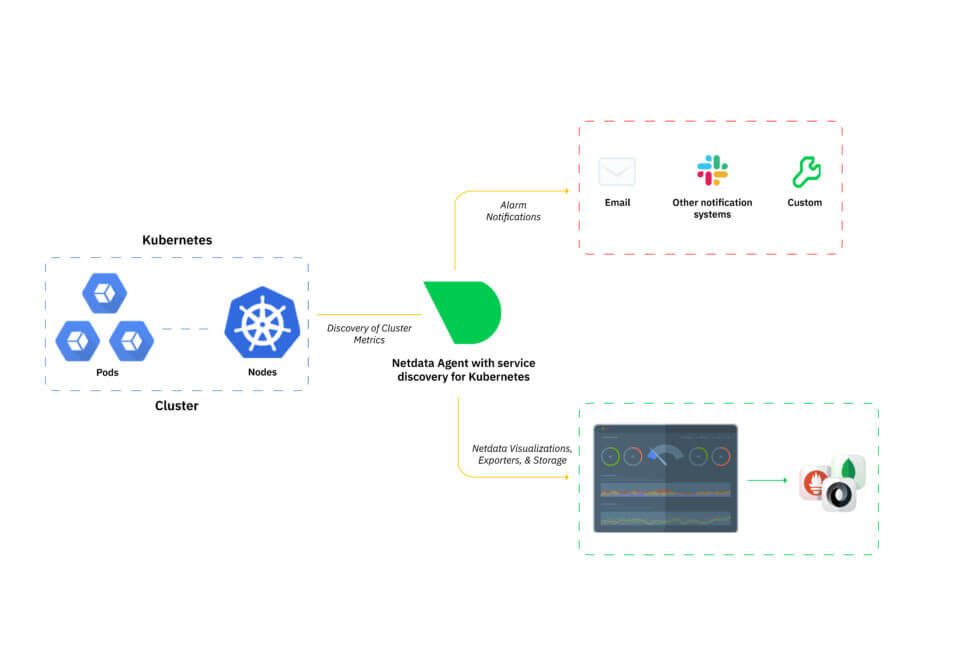
Kubernetes monitoring overview
Because container activity impacts infrastructure performance, we’ve added the ability for users to monitor individual, ephemeral k8s nodes as soon as they’re created by the k8s backend. This lets users verify what’s going on inside any given container. Currently, you can monitor 22 out-of- the-box services running on your k8s infrastructure to quickly identify patterns and drill down to uncover issues at the node, pod, and container level. For more information, take a look at our Agent Service Discovery repository in GitHub.Visualize eBPF metrics per user and application
eBPF is a core part of the Linux kernel and is a very efficient, low-overhead way of monitoring performance and observing how custom applications interact with the kernel. As eBPF continues to evolve and gain wider adoption, we’re continuing to release new features and make significant improvements to Linux kernel monitoring. Our latest release enables better troubleshooting and root cause analysis for faster response time to outages and slowdowns.Users can now detect new metrics and have access to charts for bandwidth, filesystem activity, processes, and more, per application at an event frequency. View exactly how resources and services are functioning, giving you another layer of diagnostic powers.
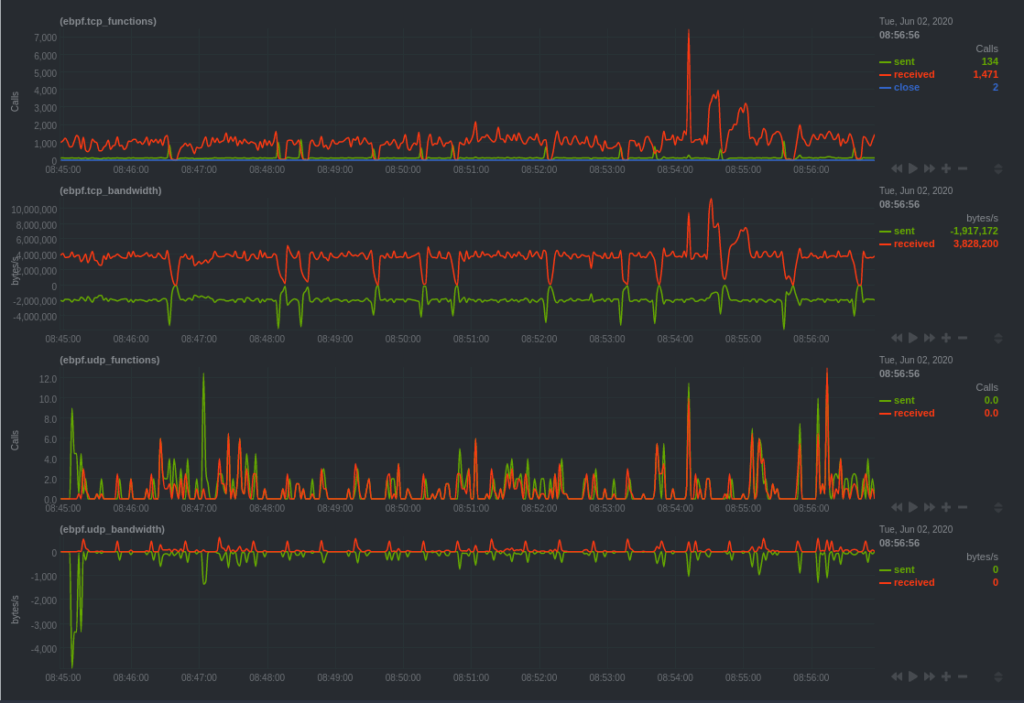
An example of eBPF dashboard overview
Monitoring per event rather than per second is a game-changer, providing granular insights into how specific applications are interacting with the Linux kernel—great for application debugging, quicker anomaly detection, and faster incident response.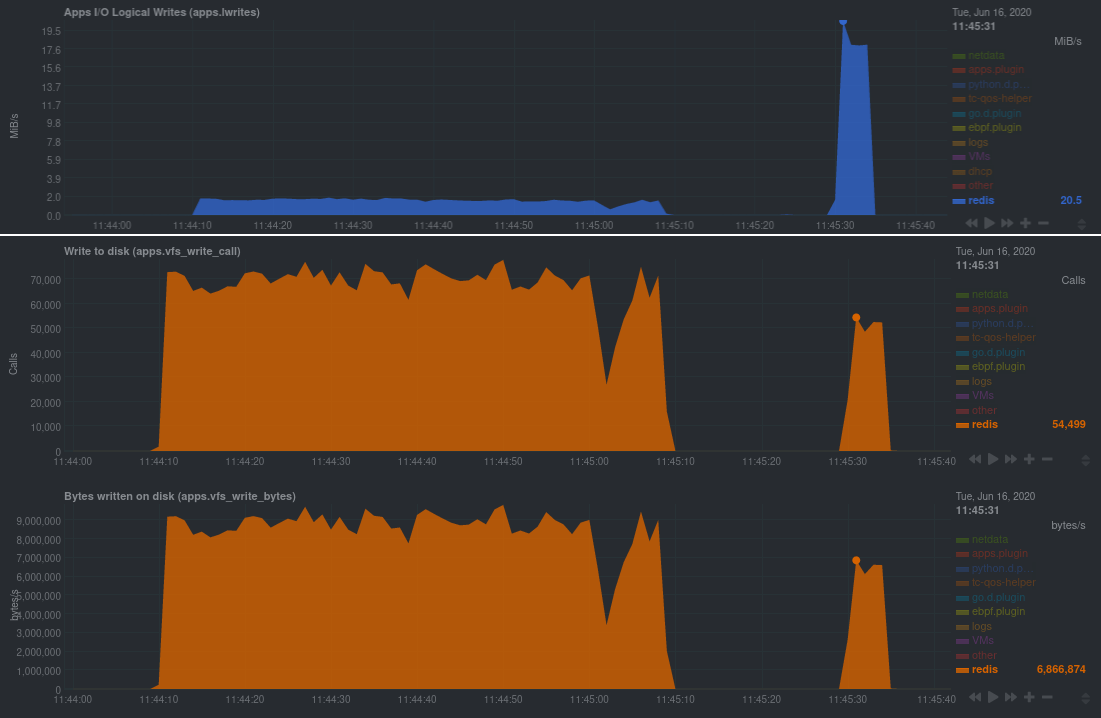
An example of metrics from a Redis database during two benchmark tests. The first chart displays the throughput of logical writes from the database in MiB/s, measuring per second. The second and third chart displays eBPF gathering metrics at an event frequency, showing availability beginning with v1.23.0 of the Netdata Agent, providing more nuanced visibility into the database’s performance.
Charts for Linux kernel data are out-of-the-box, with zero installation. You can tap into deeper visibility using event frequency for viewing system, user, and application metrics. eBPF is quickly becoming the de facto standard for Linux monitoring; we’ll continue to enhance features that provide better visibility for driving seamless performance monitoring. Check out our documentation to learn more about eBPF monitoring with Netdata or jump right in with our new guide, Monitor, troubleshoot, and debug applications with eBPF metrics.Exporting Netdata metrics to other visualization solutions and data lakes
We’re continuing to expand Netdata’s interoperability to be complementary to other platforms. Our approach is to be highly extensible and flexible, enabling end-users to select solutions that best fit their needs.This release includes additional compatibility with other tools, including the ability to export data to other databases (like MongoDB), JSON, Prometheus remote writer connectors, and more. Although you can store long-term metrics with our database engine, you may find it useful to transfer data to another source if it provides a more integrated view. Users can now also reduce the amount of wait time by exporting metrics in parallel to multiple endpoints for high availability. As soon as metrics are collected by the Agent, export to create or enrich for a single pane view, filled with information consolidated from various sources into a single display. Users can export to a data lake for long-term historical storage to enable deeper analytics with machine learning, or use this functionality to correlate Netdata metrics with other data sources, such as application tracing. Learn more with our exporting metrics quickstart.
And even more
There’s even more functionality in Release v1.23; to get the full scoop, be sure to check out the release notes on GitHub. And before we go, a special thanks to those in our community who helped make this release possible:- okias for adding support for Matrix notifications.
- elelayan for adding an OSD size collection chart to the Ceph collector.
- vsc55 for fixing the required packages for Gentoo builds.
- rushikeshjadhav for fixing the Xenstat collector to correctly track the last number of vCPUs.
- Saruspete for removing conflicting EPEL packages.
- MrFreezeex for fixing suid bits in Debian packaging.
- Neamar for fixing a typo in the dashboard’s description of the
mem.kernelchart. - jeffgdotorg for fixing incorrectly formatted TYPE lines in the Prometheus backend/exporter.
- tnyeanderson for continuing to improve his
dash.htmlcustom dashboard. - dpsy4 for fixing our Swagger API file.
- araemo for fixing alarms around RAM usage in ZFS systems.
- slavaGanzin for implementing a fix to the PostgreSQL collector.
- pkrasam, thoggs, oneoneonepig,Steve8291, stephenrauch, waybeforenow, zvarnes, electropup42, cherouvim, thenktor, webash and gruentee for contributing documentation changes.