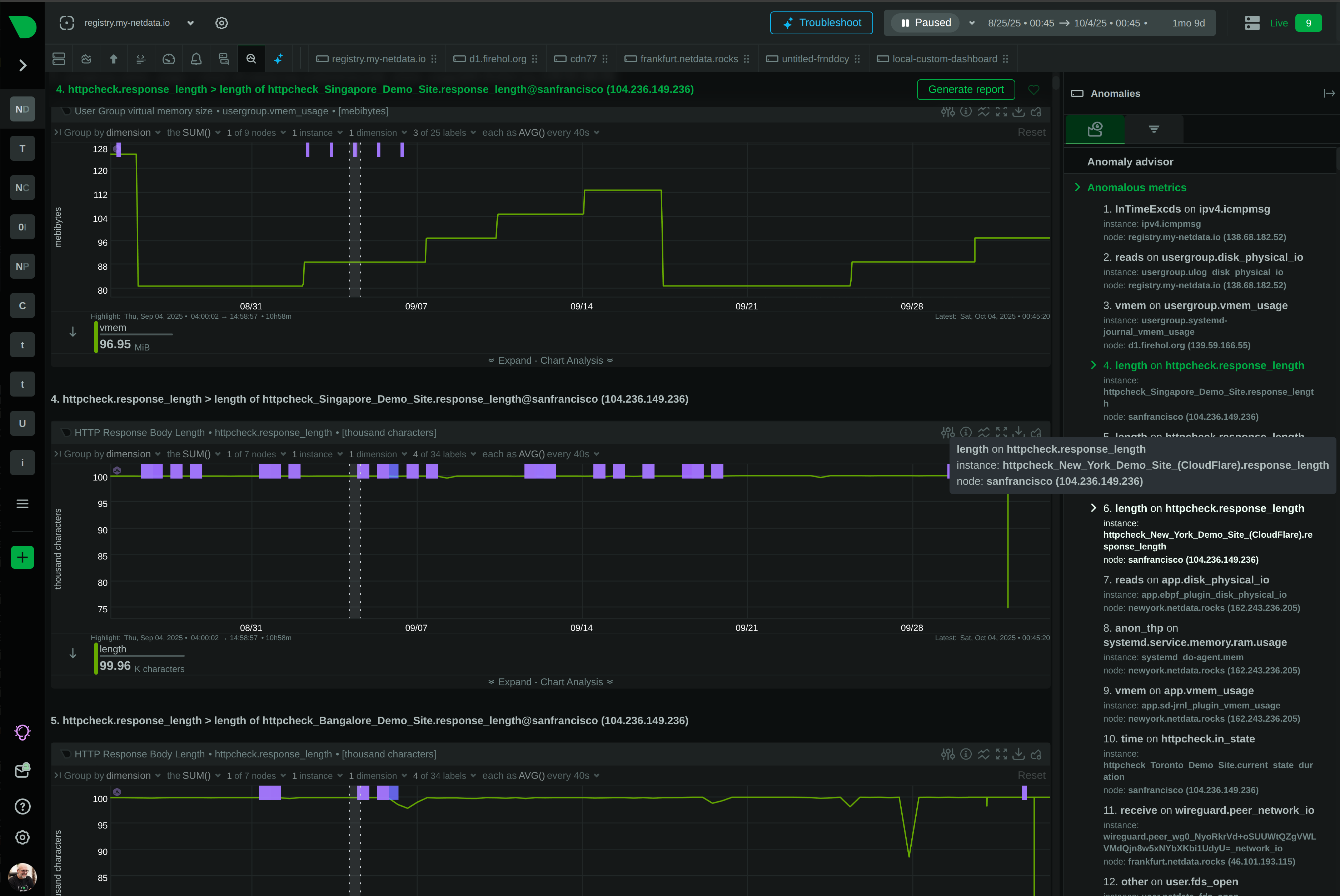
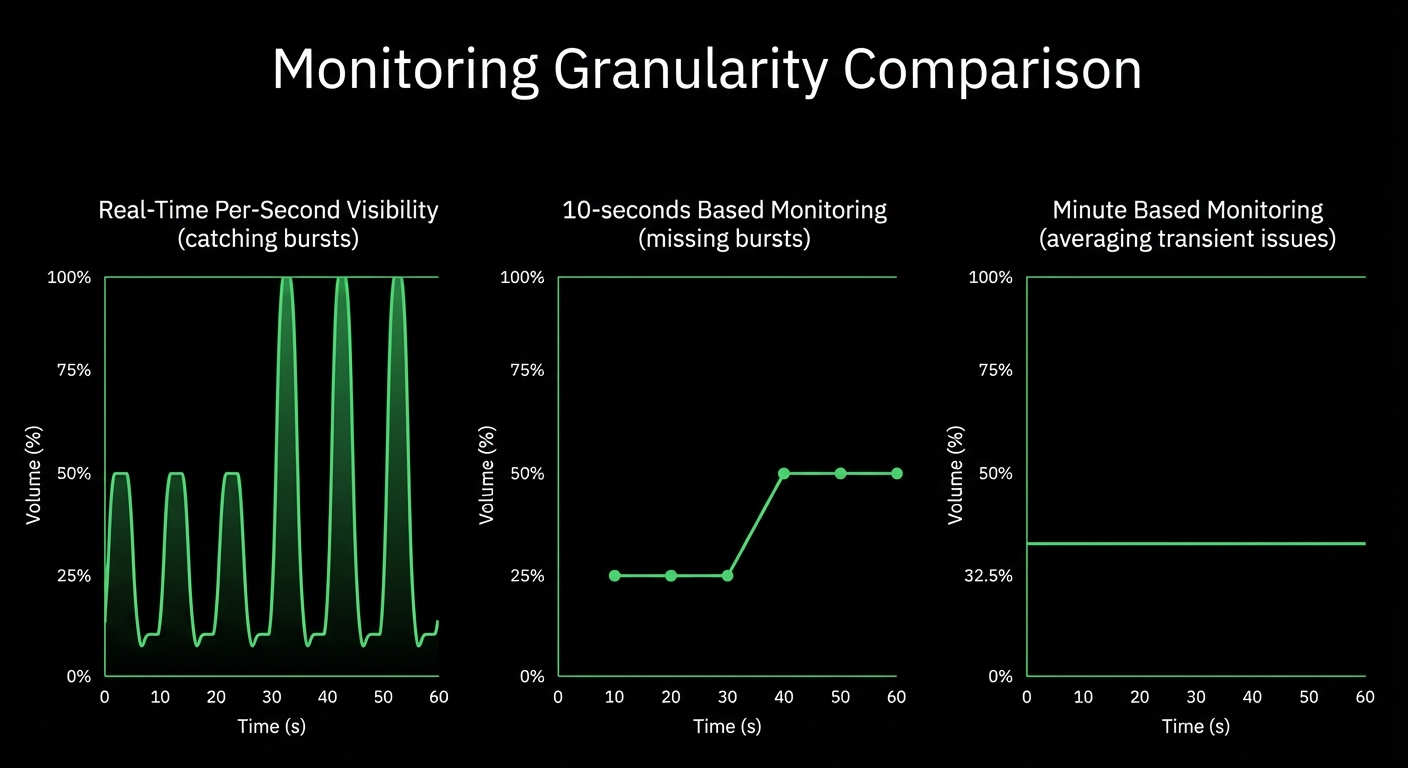
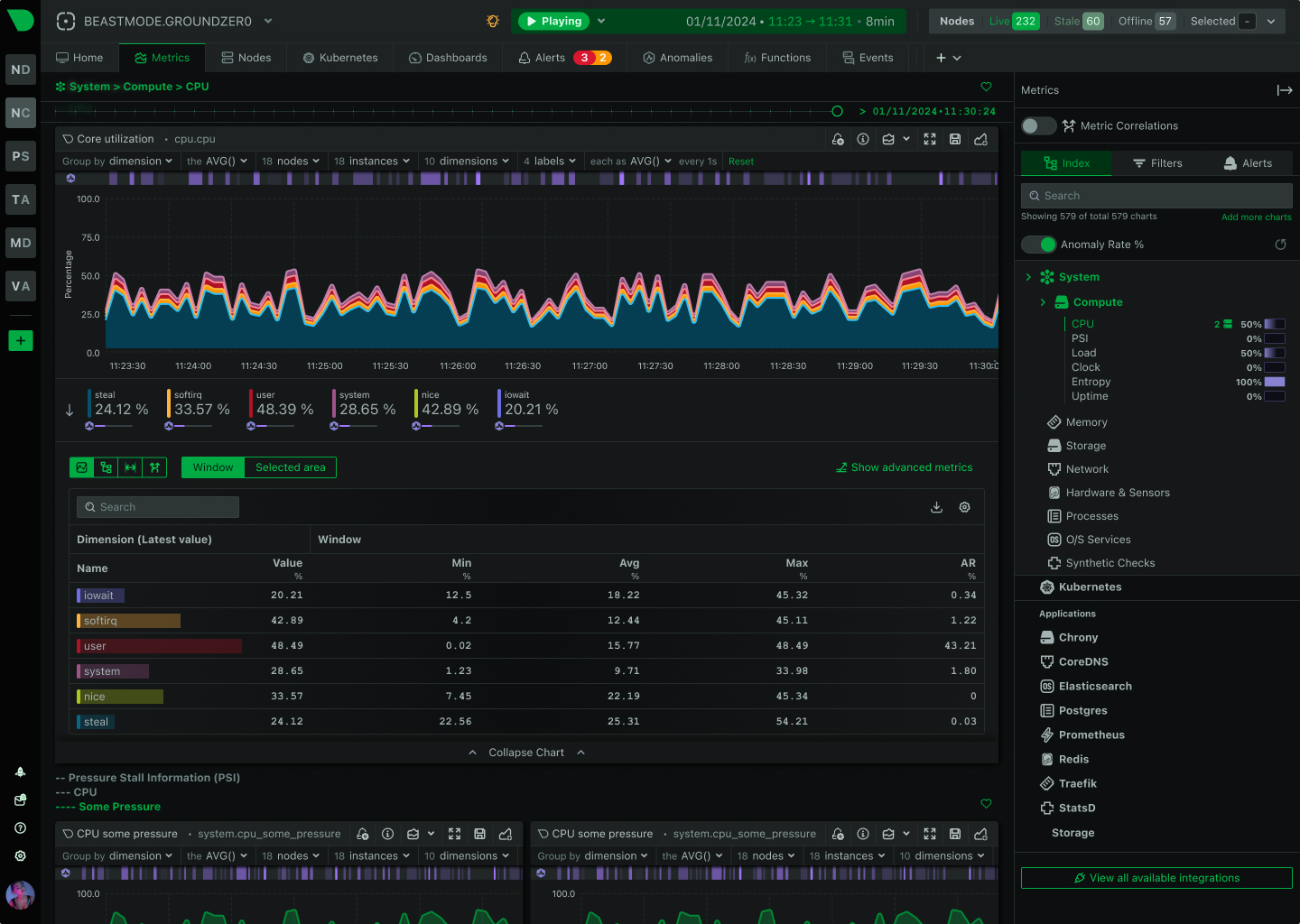
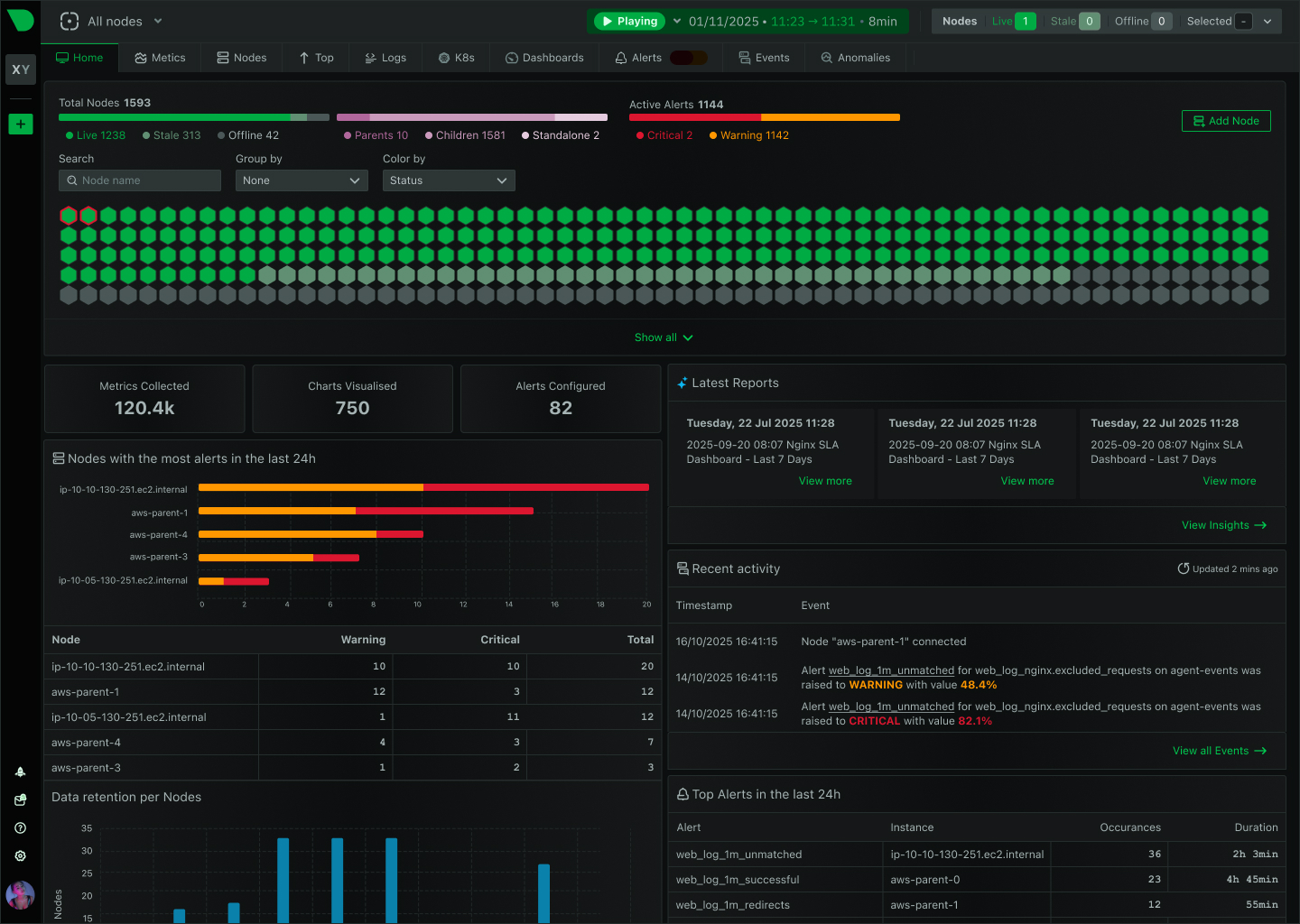
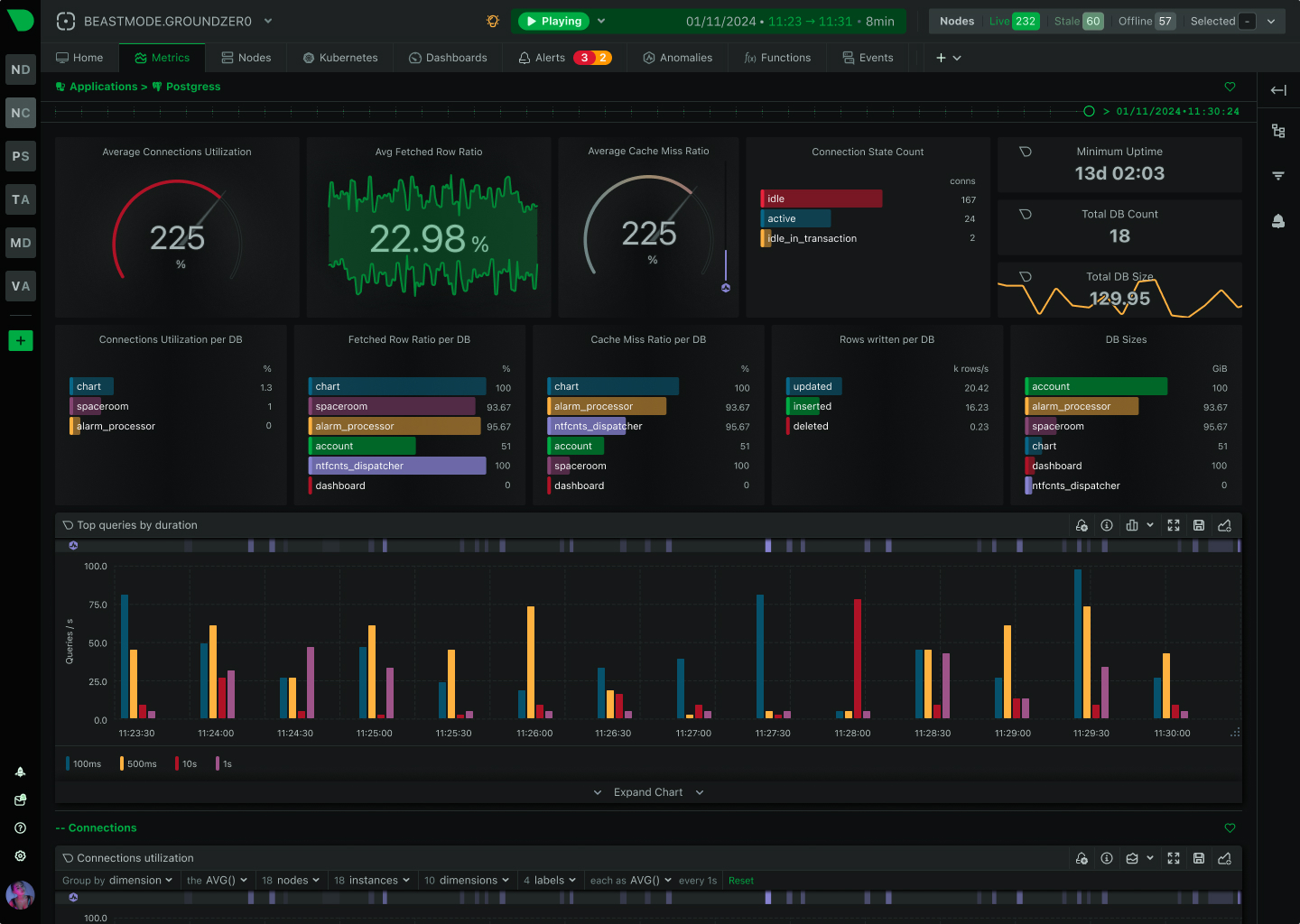
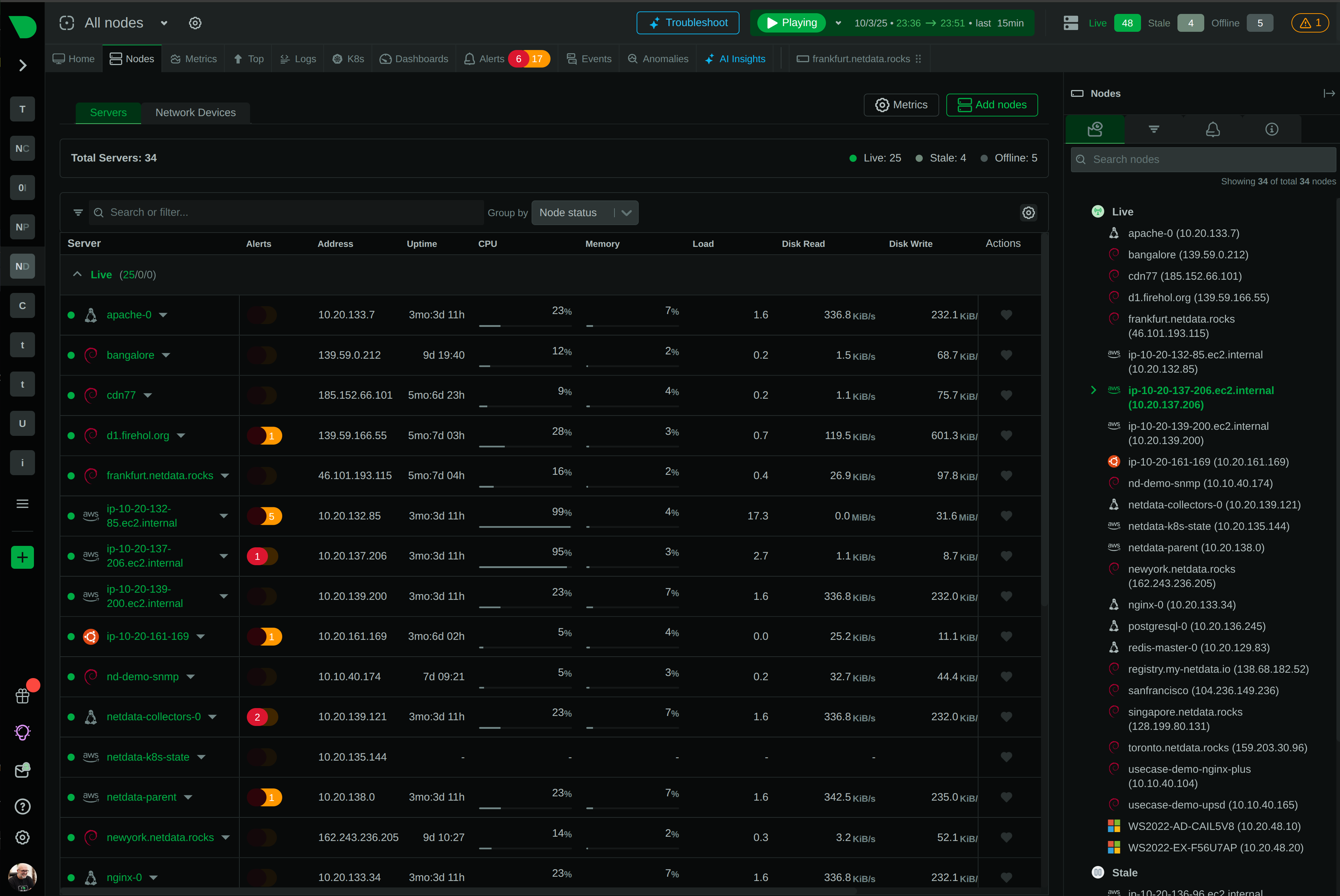
Detect Issues Instantly, Investigate Thoroughly
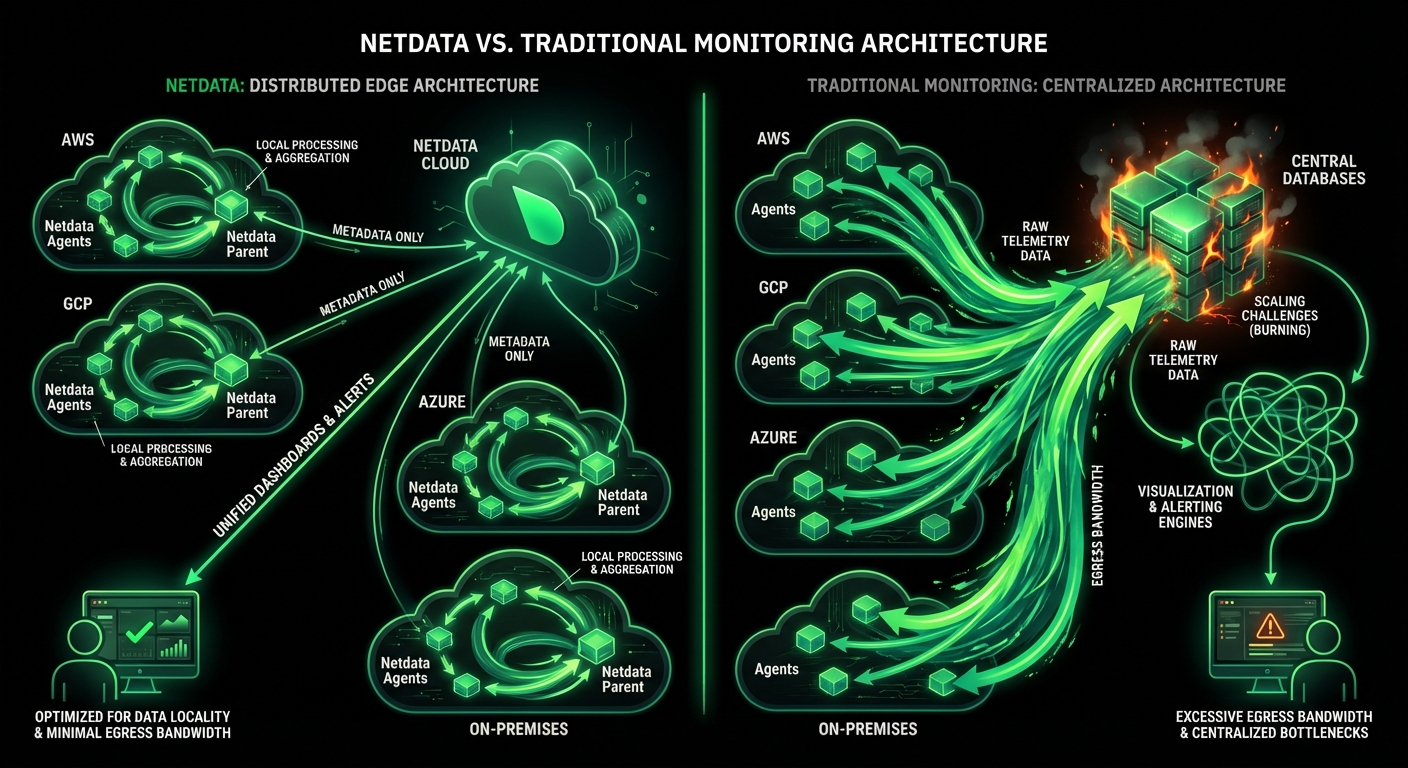
Modern infrastructure demands both real-time performance monitoring and comprehensive log analysis. Netdata detects anomalies as they happen with per-second metrics and ML-based insights. Graylog provides centralized log management for deep-dive investigations. Together, they transform your incident response from reactive to proactive.