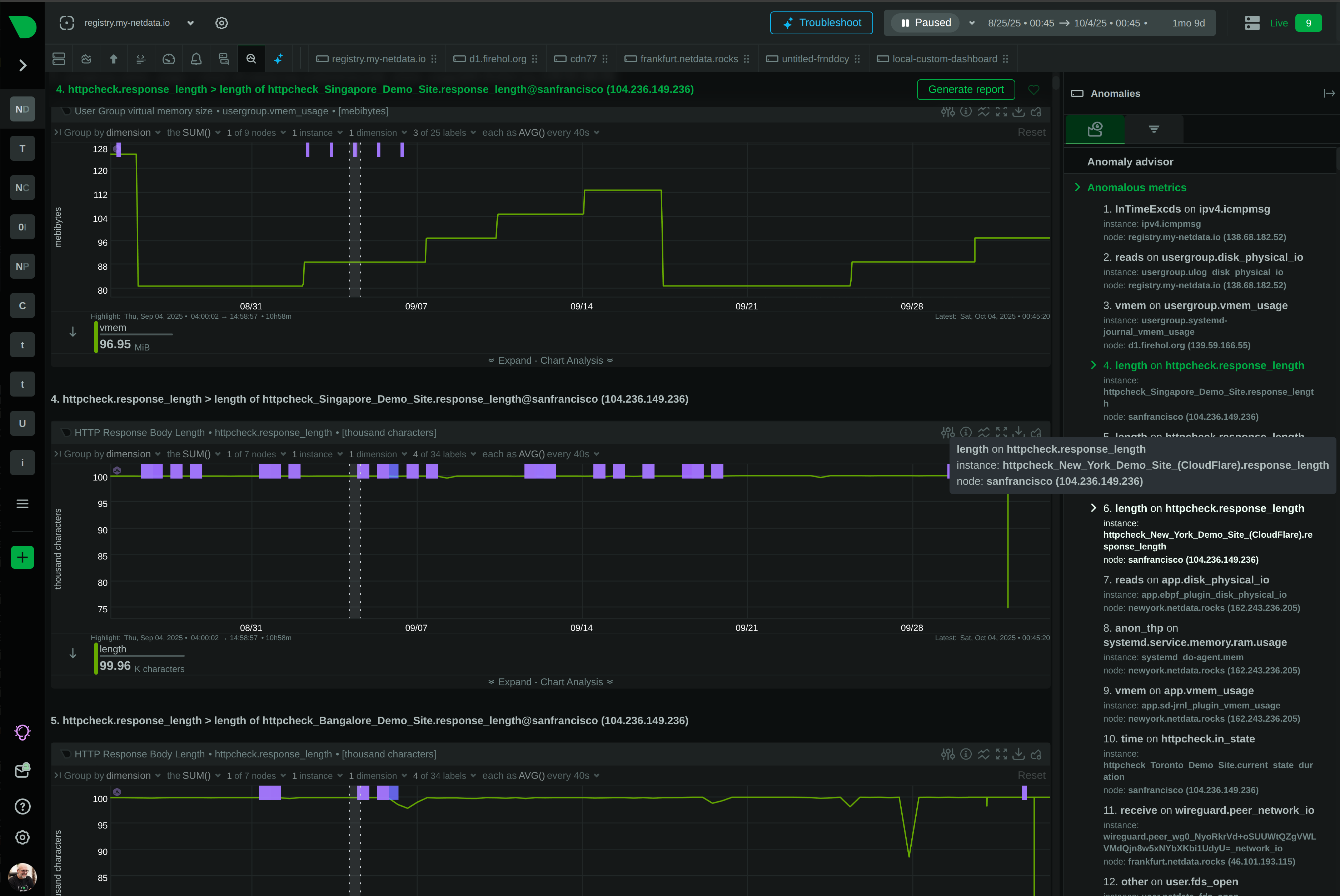
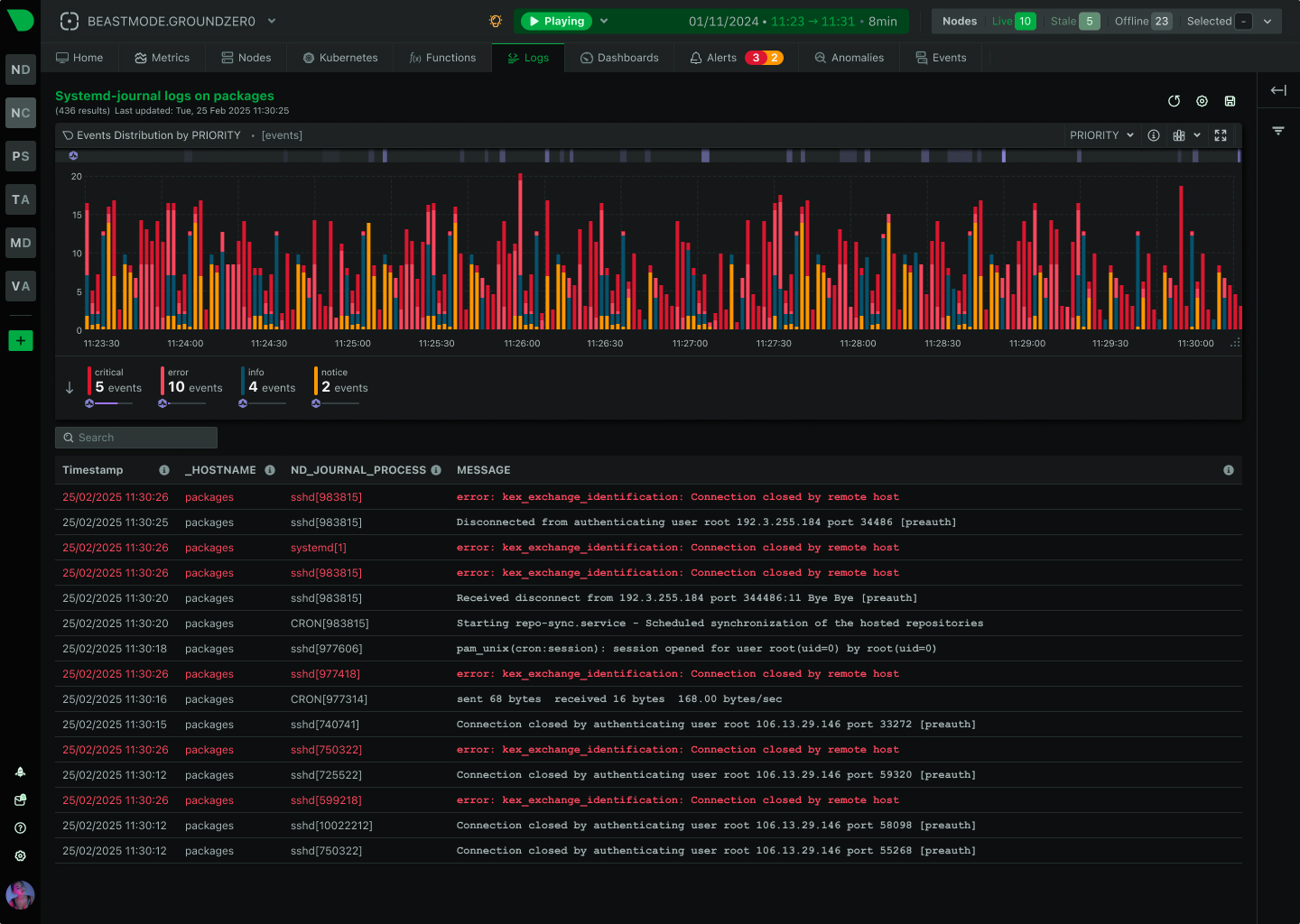
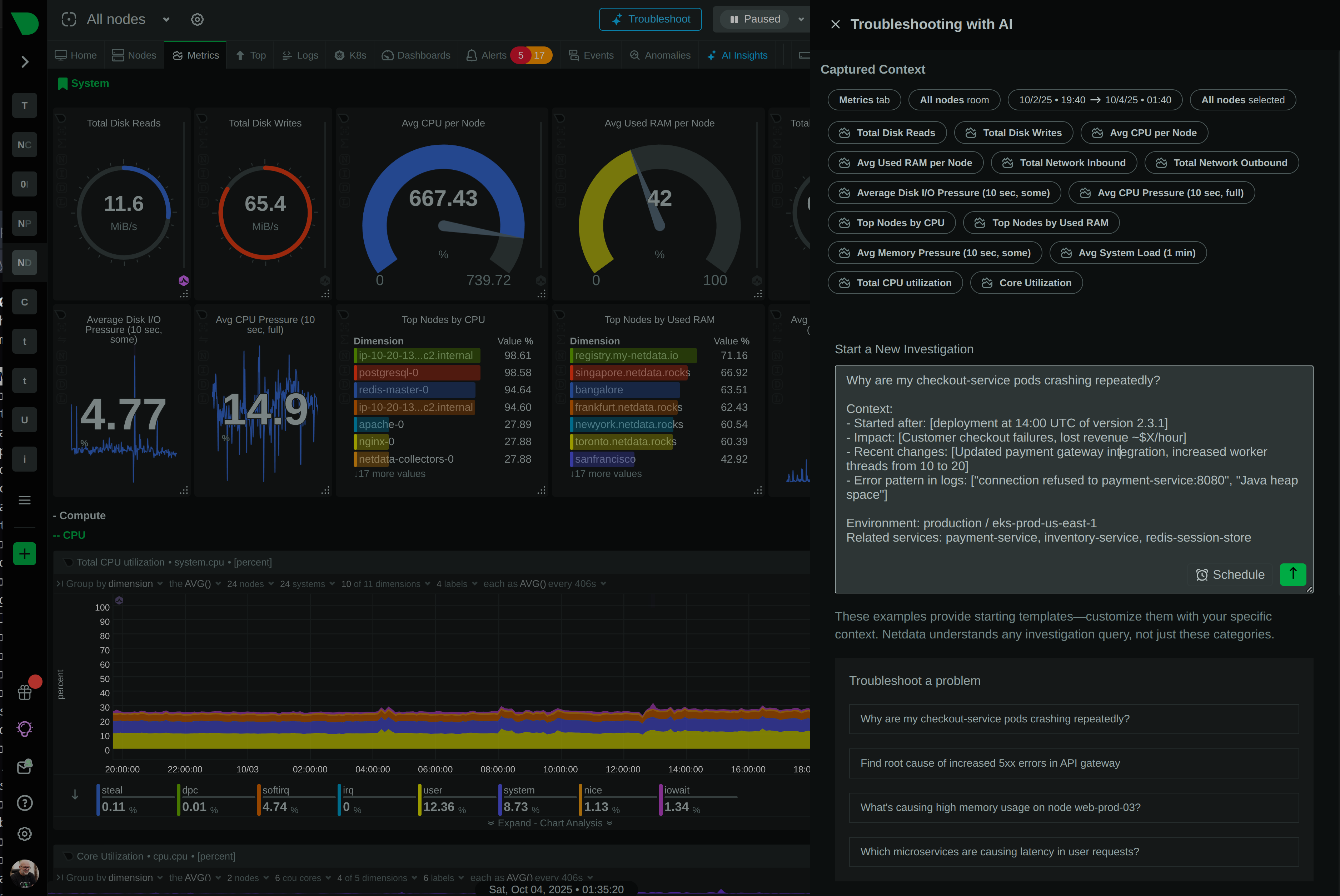
Troubleshoot Production Issues in Seconds, Not Hours
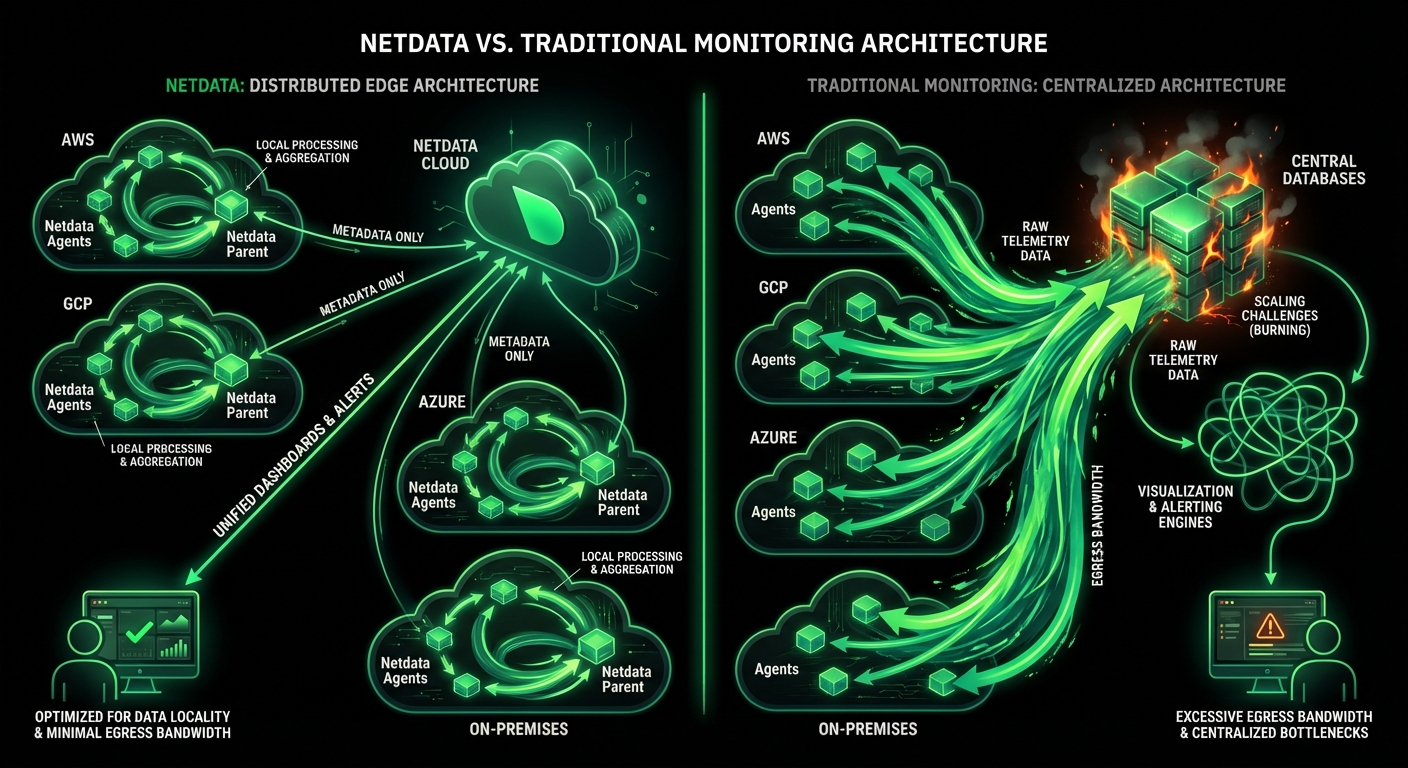
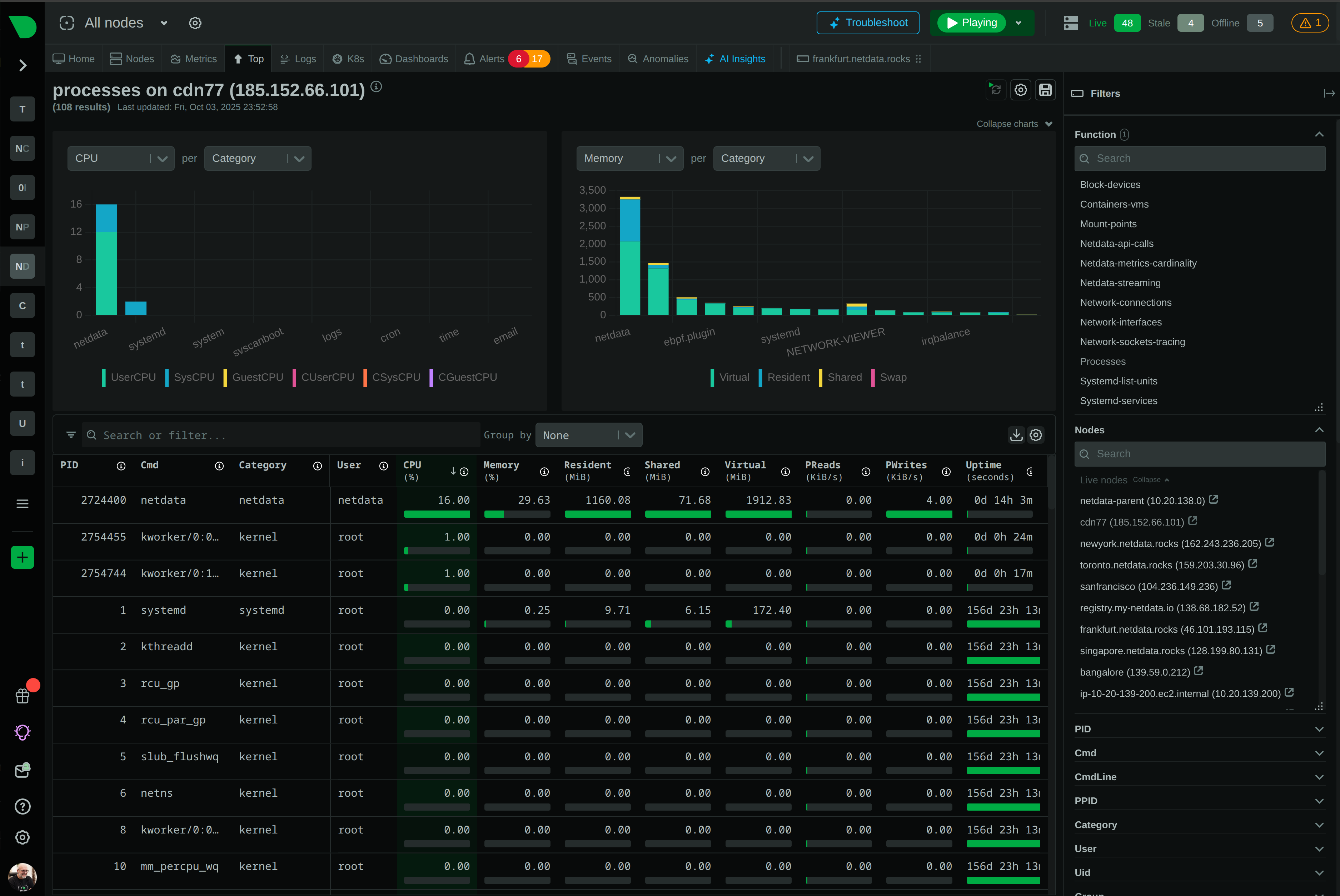
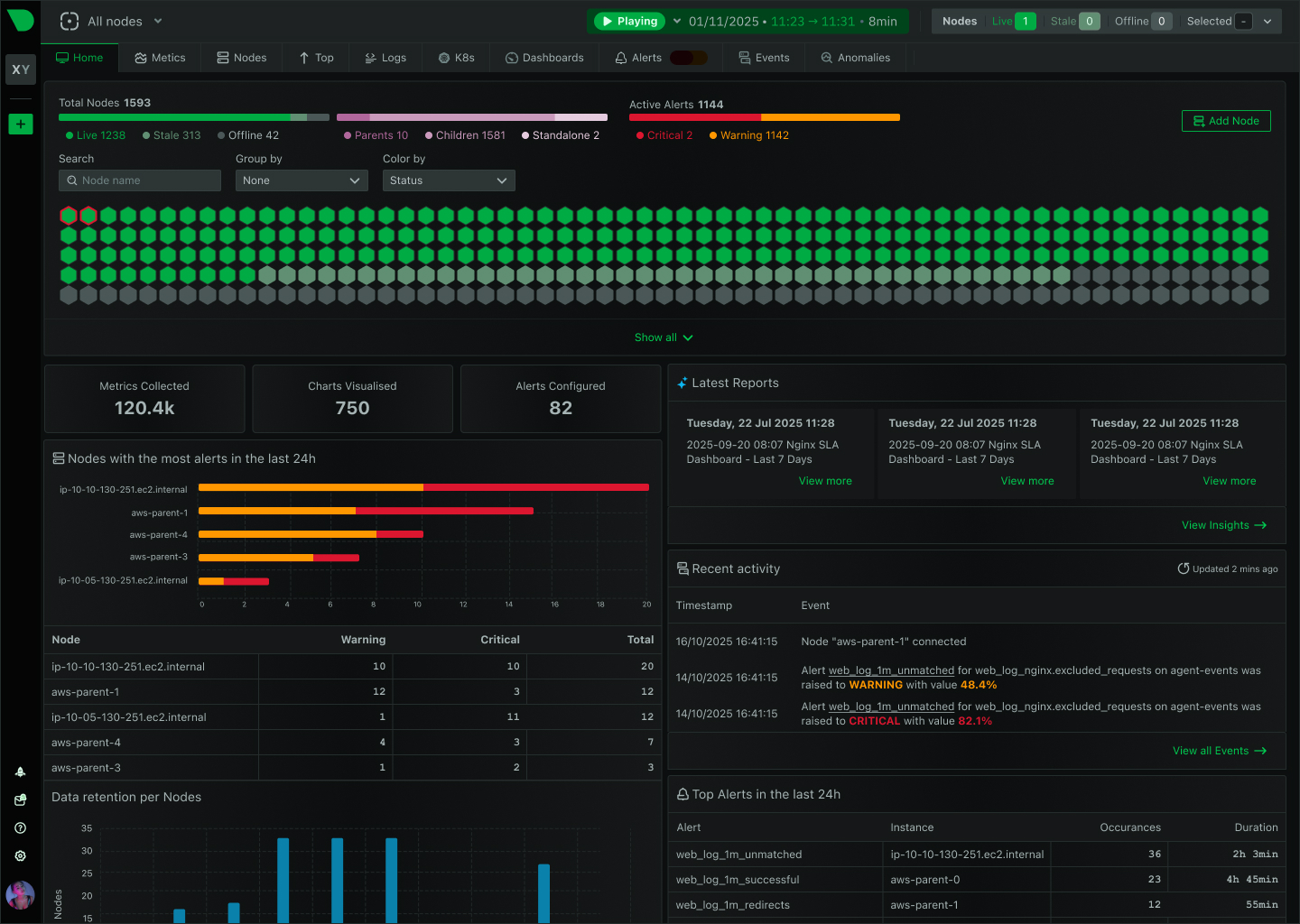
While Prometheus requires weeks of PromQL training and complex setup, Netdata delivers complete observability in 60 seconds with zero configuration. Get per-second visibility, built-in ML anomaly detection, and AI-powered troubleshooting - without the operational overhead.