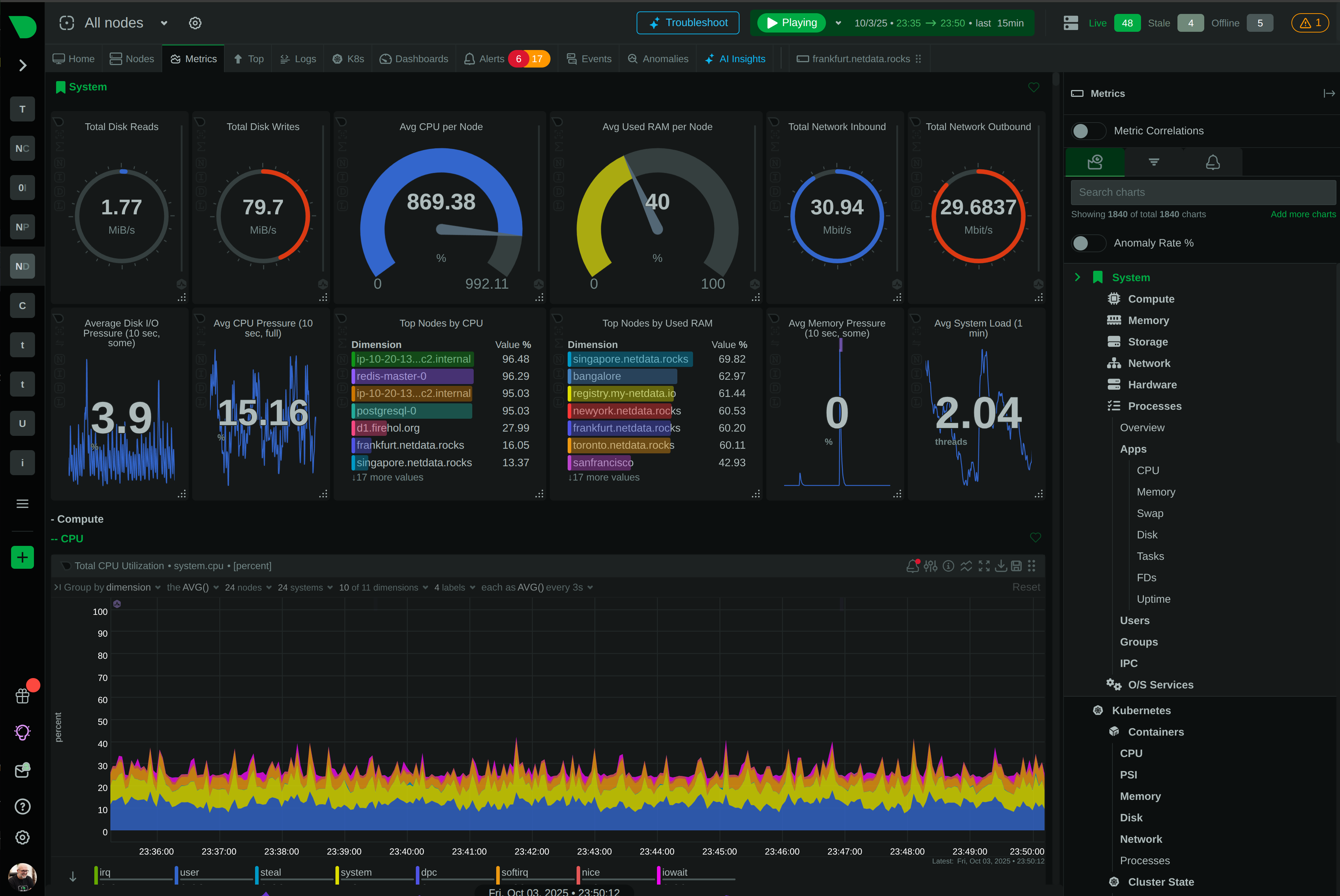
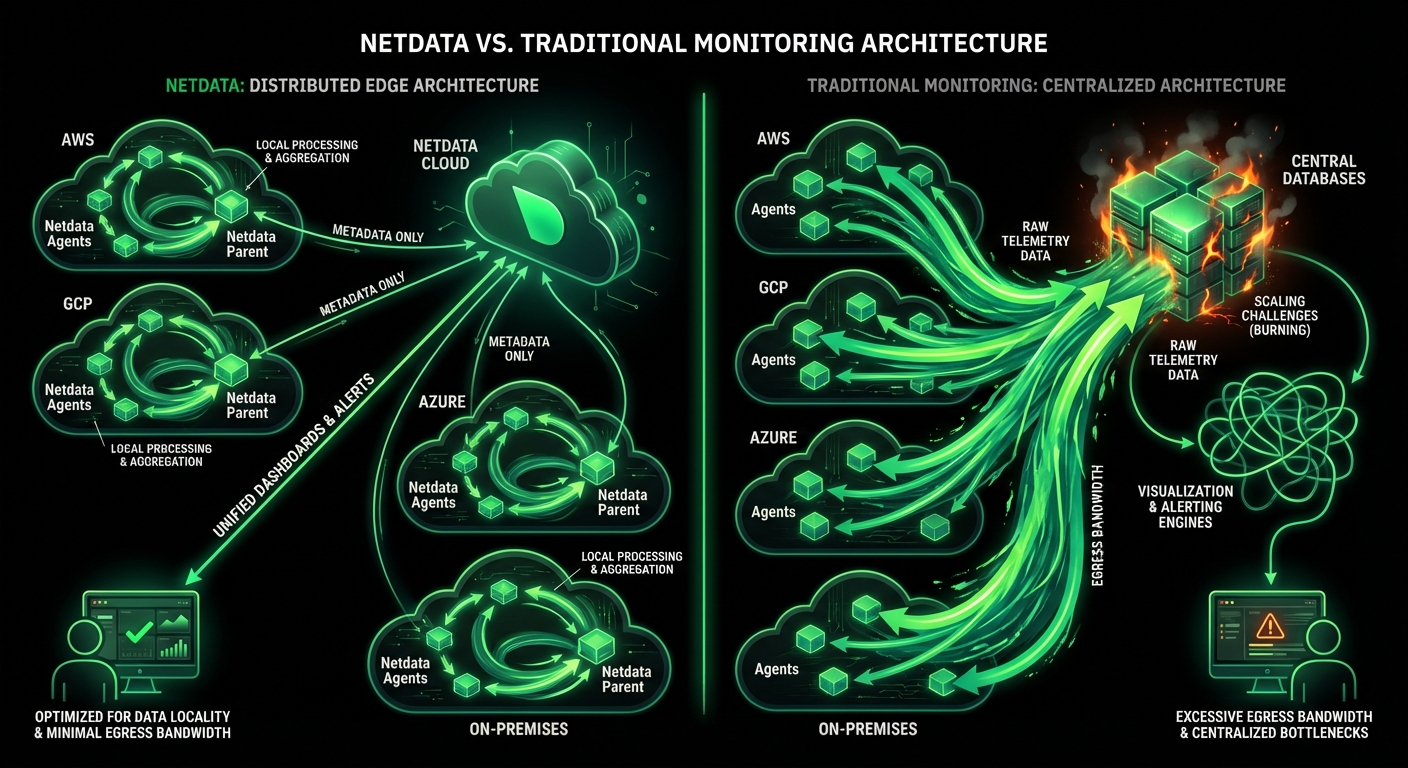
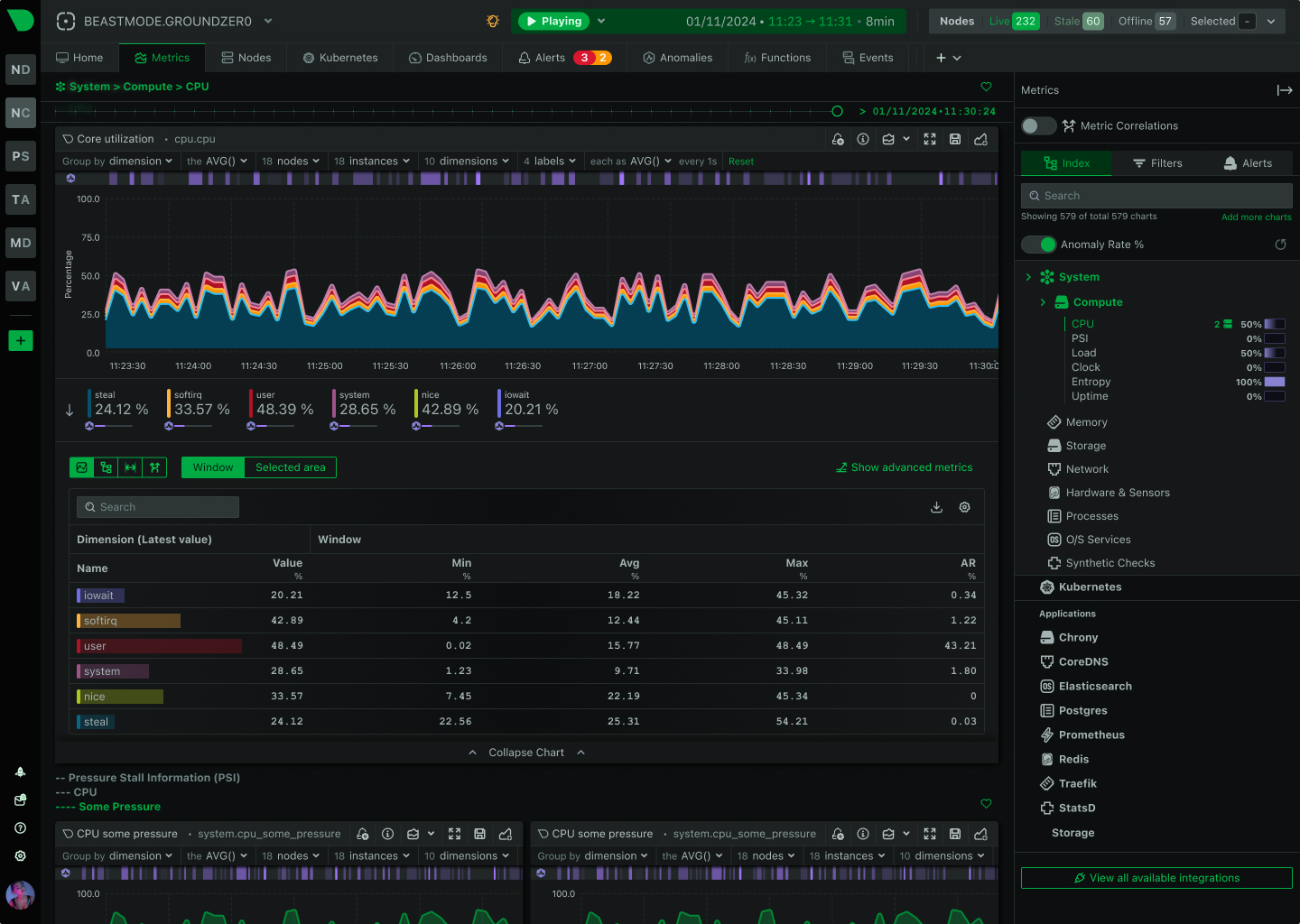
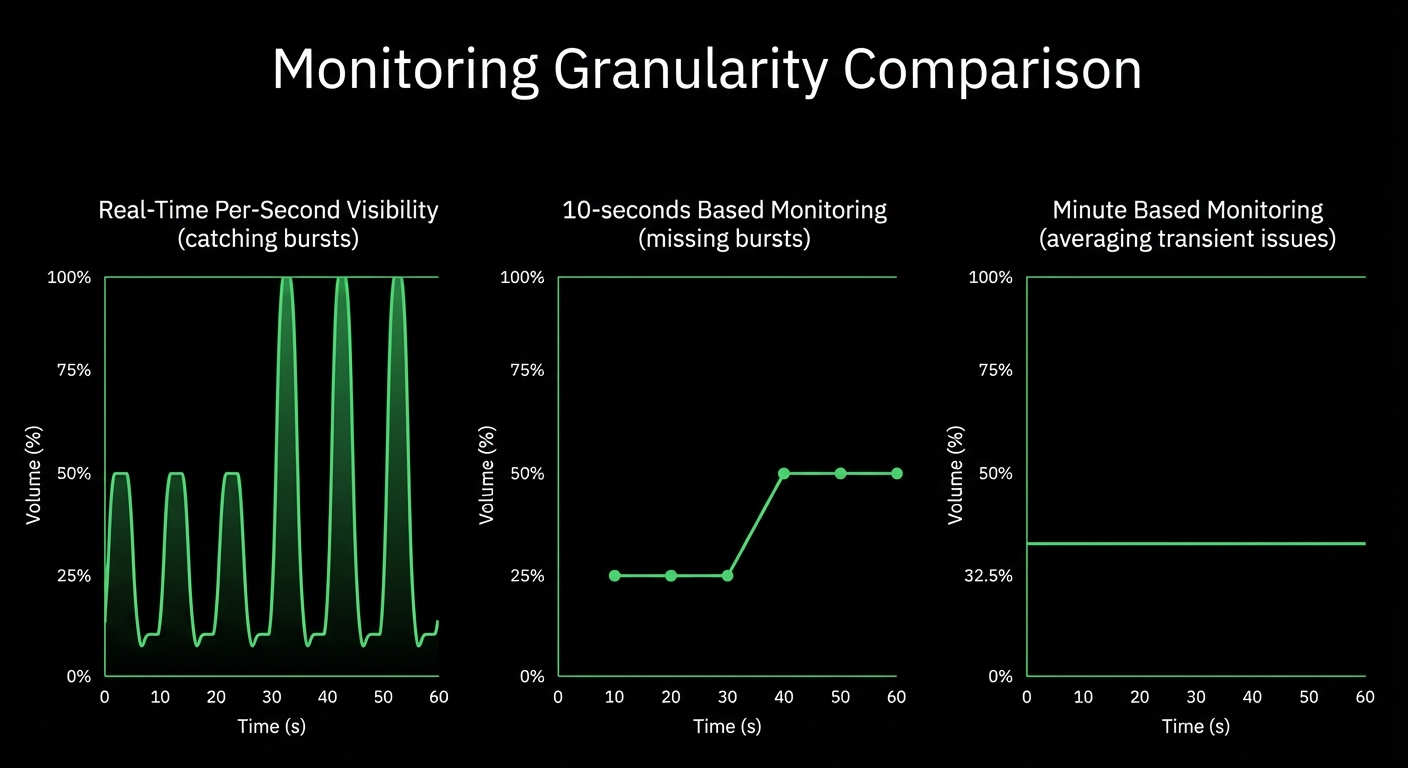
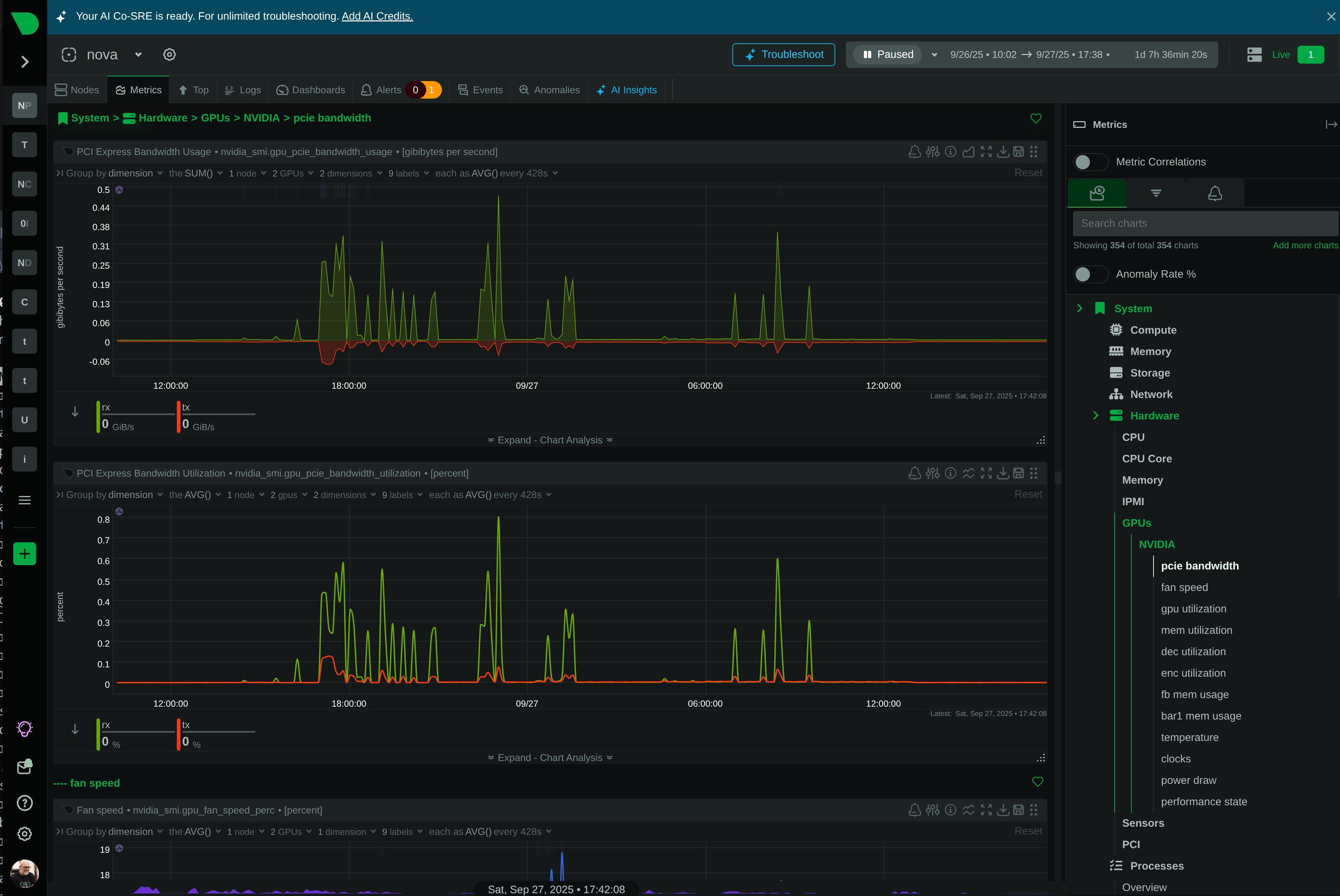
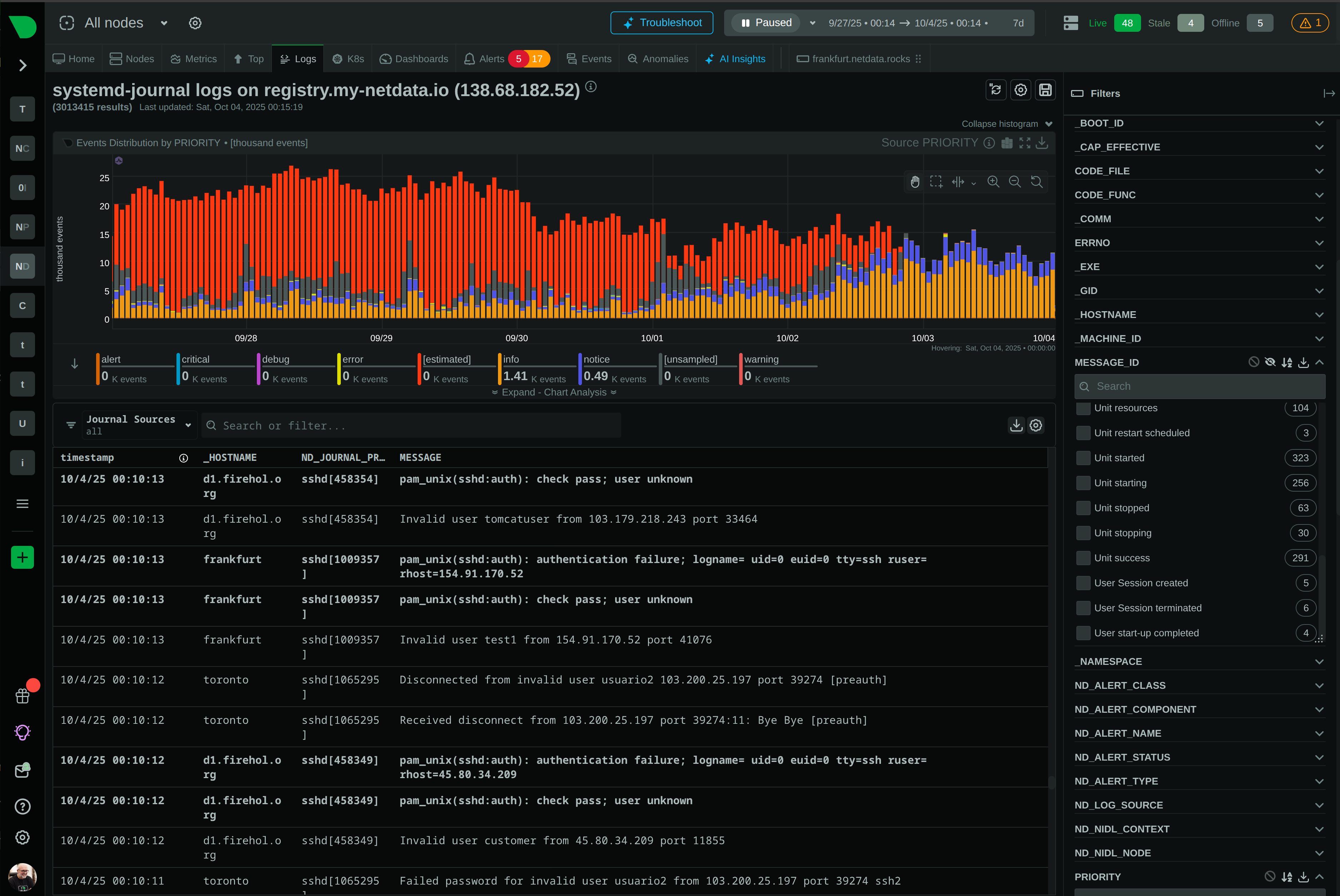
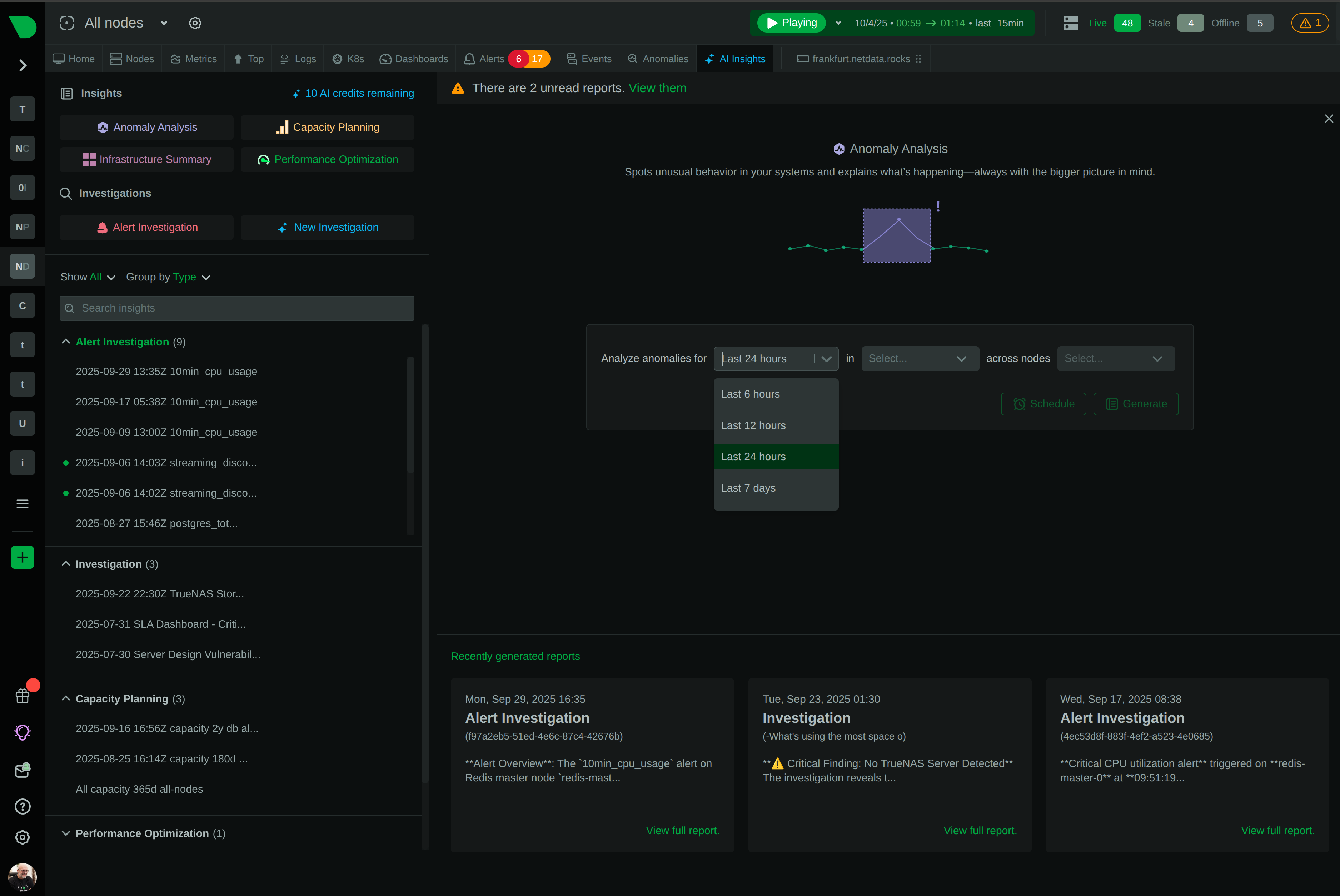
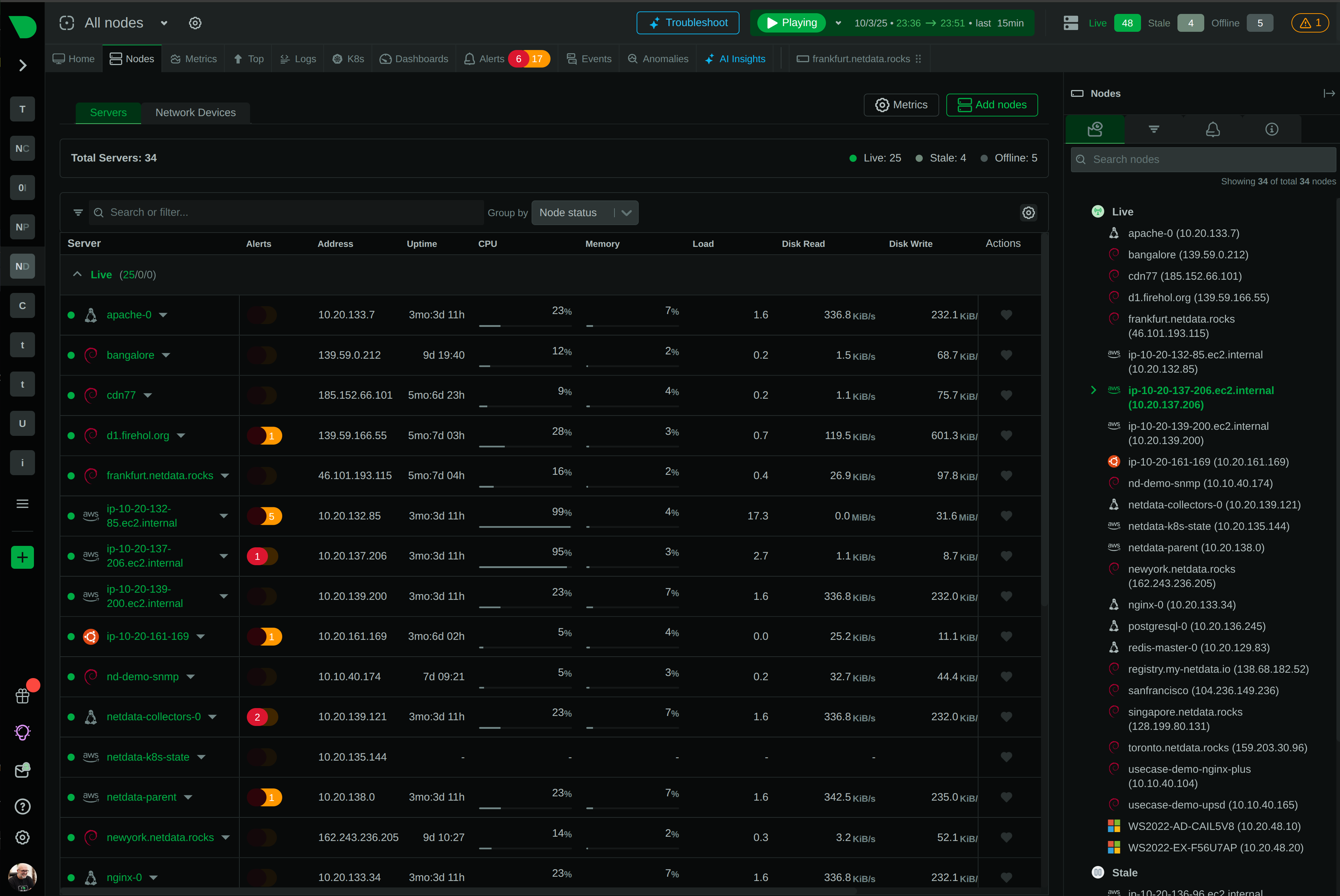
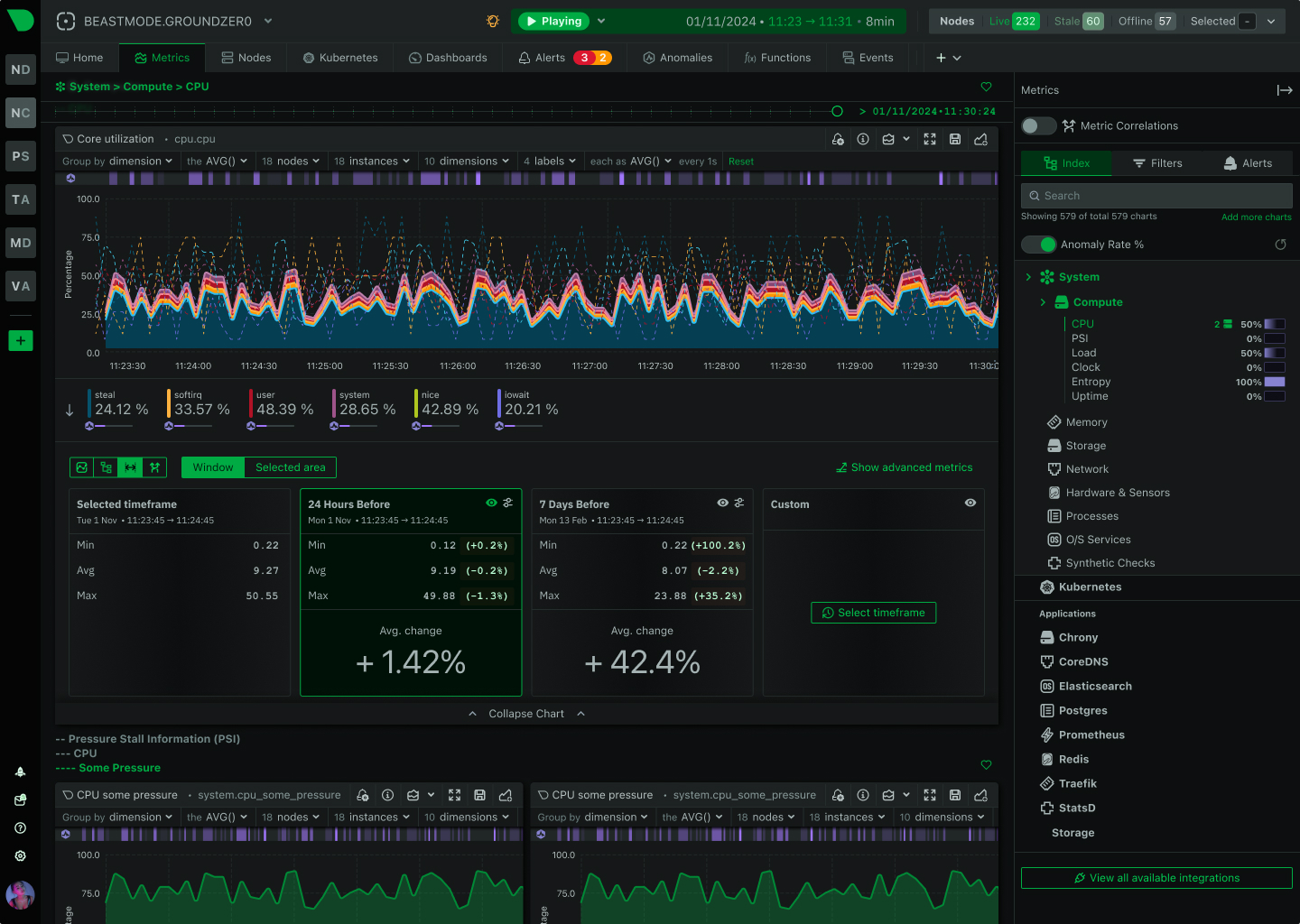
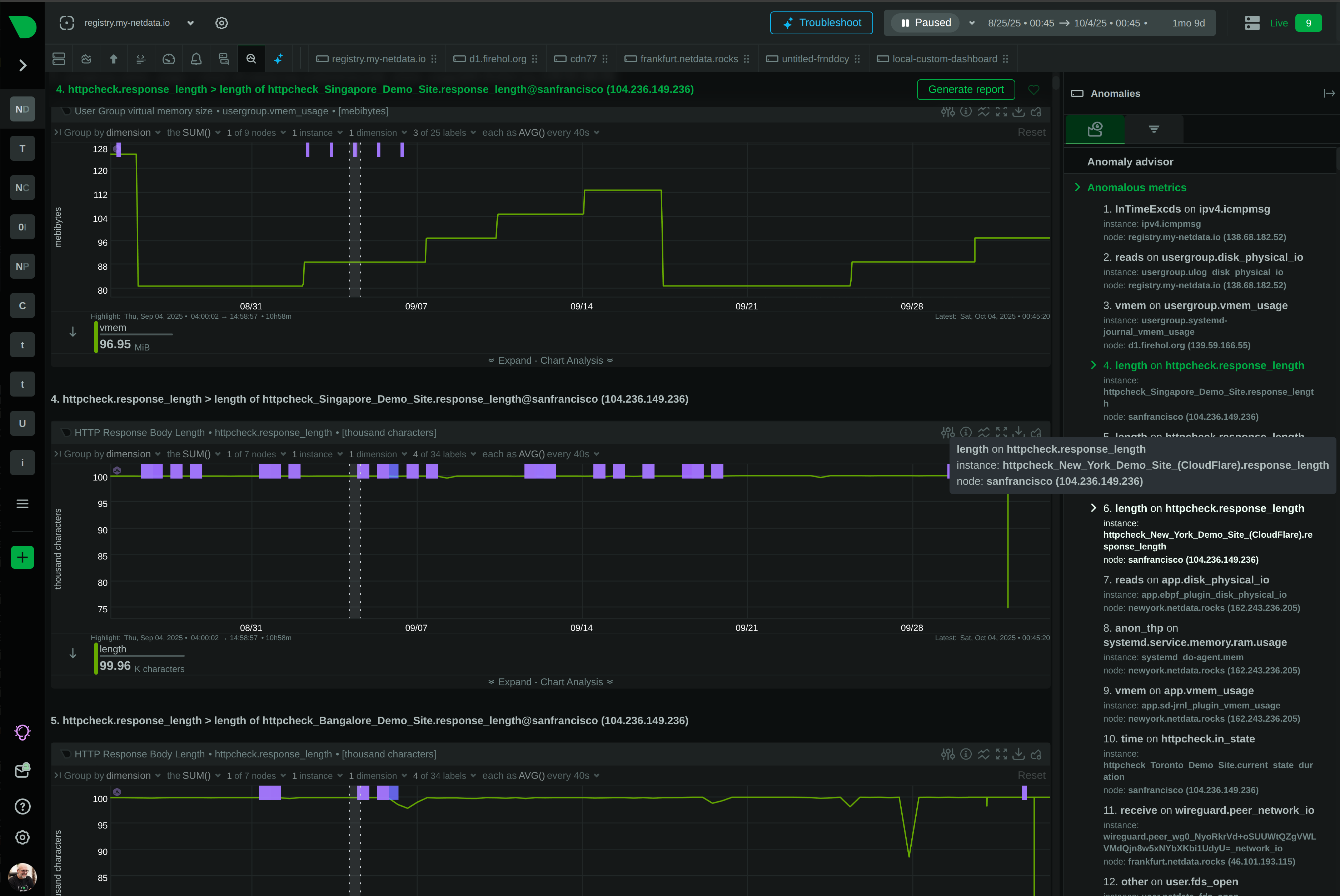
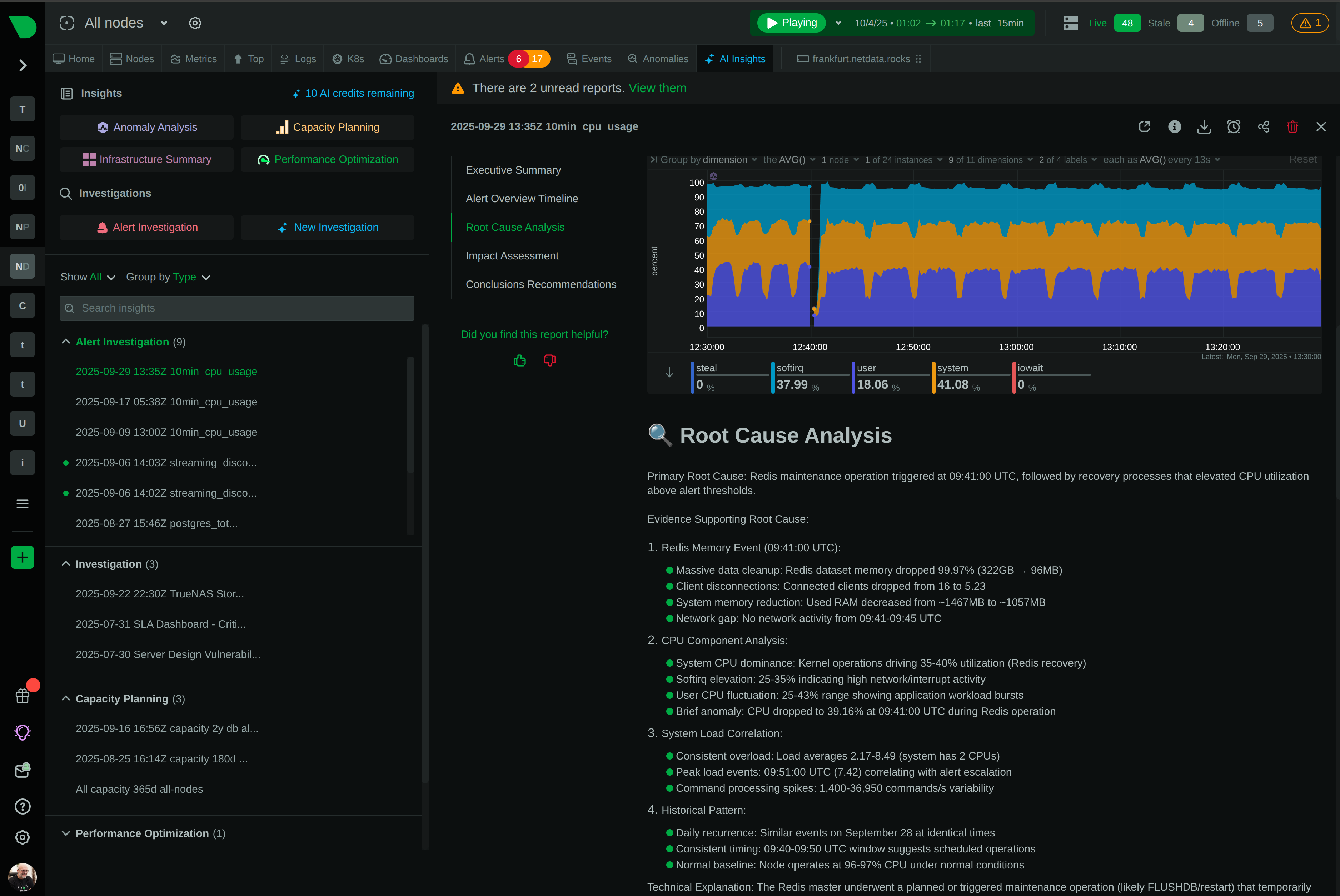
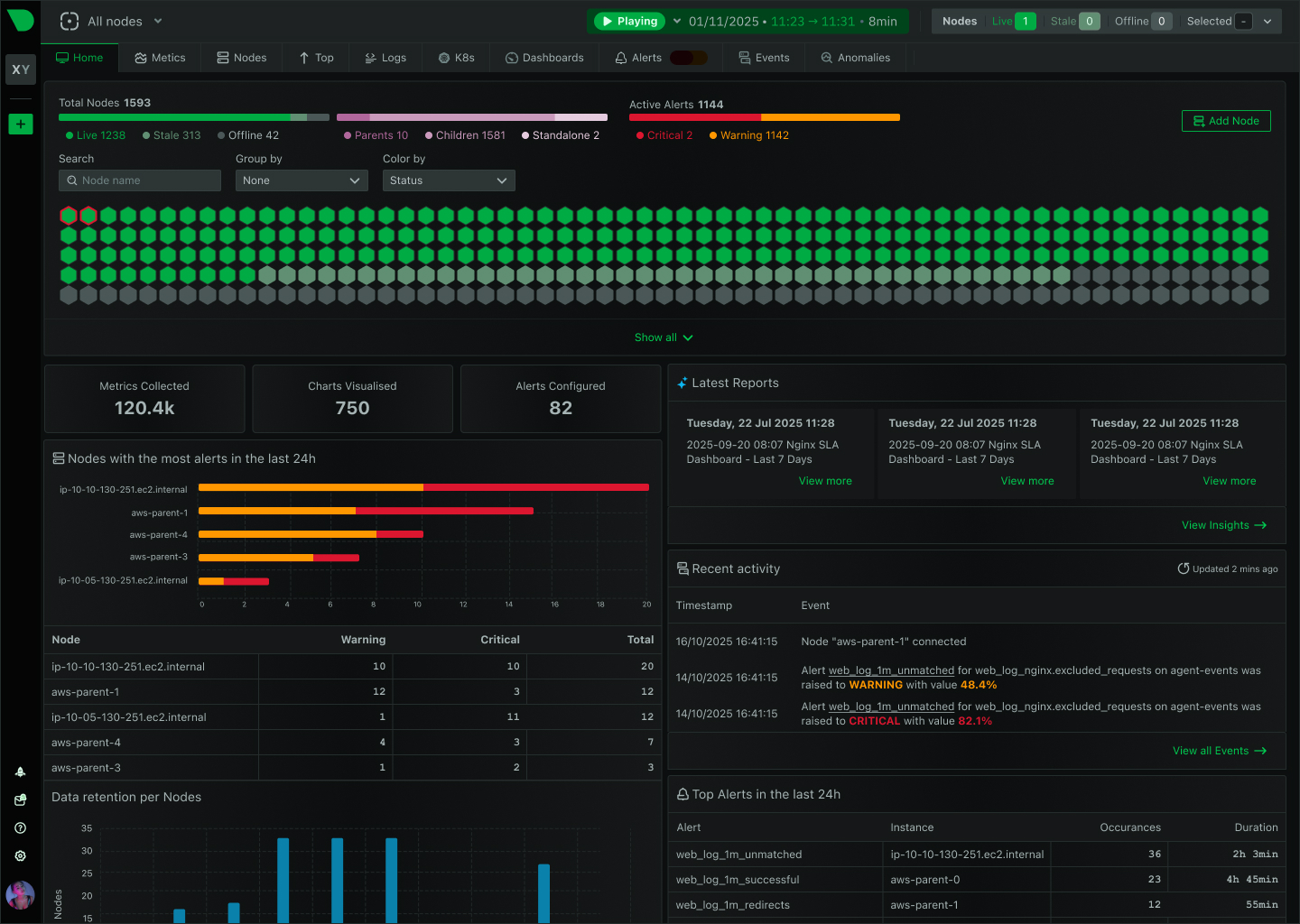
See Every Second of Your Kubernetes Infrastructure
Per-second visibility across control plane, nodes, pods, and containers. ML-based anomaly detection on every metric from day one. AI-powered troubleshooting that explains what broke and why - in plain English. All at 90% lower cost than traditional monitoring.