








Netdata is made up from agile teams who are deeply committed to improving the usability of our product. We want to respond to our users and introduce in-demand features. Working directly with our community is the best way to make Netdata better.
But we face the same the dilemma as all agile teams: How do we do this safely?
Safety means that we can move quickly without compromising the quality of our code. Because we want to move quickly, engage with our users’ desires, and keep quality high, we’re becoming very serious about adopting unit testing in our work.
Unit testing is our safety harness
We can’t make the code any simpler than the problems that we solve, and some parts of monitoring are hard.We need to be able to trust that some of our more complex code is free from bugs. That means both the simple implementation bugs, where it does the right thing in the wrong way, and the more complex specification bugs, where it does the wrong thing.
If we can successfully implement unit testing across our codebase, we get that safety harness. Our team can detect where changes will affect the product and the way that it works for our users. The design contract in the code becomes visible to us so that we can maintain it, and our debugging work becomes faster and more accurate.
Bringing unit testing to Netdata hasn’t been as simple as flipping a switch, or enabling a post-commit hook in Github. Here’s a look into our journey.
Deciding on cmocka for Netdata’s unit testing
The Netdata agent’s core is written in C, which is not a usual target for Test-Driven Development (TDD). To be able to unit test key functionalities of the Netdata daemon, we needed to use mocking, which requires a complete framework.There are a lot of testing frameworks out there, but we narrowed it down to three main candidates: Google Test, cmocka, and Unity. A more detailed evaluation gave us the following comparison table.
Google Test | cmocka | Unity |
 |  |  |
But using cmocka wasn’t that simple
The largest difficulty in testing is making sure that we test the right thing: the relevant piece of code, running in a context that is as close as possible to how it runs in the real system.Because we are working in C, this context is really the state of memory inside the application, and we must be confident that we are recreating it. In the real application, the procedures that we are testing are integrated into the system—they call other procedures that are not part of the test. We need to way to cut out the piece of the application being tested, isolate it from the rest of the application, and wrap it up inside a reproducible test.
This is the main strength of cmocka, and using it lets us build on the huge amount of work that has already gone into making it do this.
The library provides us with a facility called “mocking”—substituting pieces of the real application with pretend versions. These “mocks” allow us to capture the data at precise points within the application and define the boundaries of the test. We can inject data directly into calls inside the application and use the mocks to capture the results before they propagate into the rest of the application.
The only additional facility that we need is control over memory. We have to make each test reproducible, and that means being certain no state accidentally propagates out of one test and into another. cmocka can checkpoint the state of memory in between tests and give us rigid guarantees that a test passes because of what we did inside the test—not because an earlier test accidentally set us up to give the right result.
Although cmocka is a powerful base for us to build testing upon, it lacks a feature that is critical to the tests that we want to build. In typical unit-testing, each piece of functionality inside the system being tested needs a separate piece code to test it. If we want to test 10 pieces of functionality, then we must write 10 tests.
If we want to test thousands of separate cases, then we’re a team with no agility at all.
There is a solution to this problem: parametric unit tests. Parametric testing allows us to write a single test, but in such a way that its exact behavior is controlled by the parameters that we feed into it: test_something(3, “blue”, SecondTechnique). Then, by altering the parameters, we can test the system with different values, access the red functionality, and control other aspects of the tested code.
But, as you might have guessed based on the existence of this post, parametric unit tests are not supported by cmocka.
This hiccup meant we needed to figure out a way set up testing on 1000s of variations of low-level HTTP messages without needing to spend months writing individual test cases.
The challenges of unit-testing Netdata
Choosing an initial target for unit testing was easy.We started with Netdata’s web API, because the interface that we supply to the network is the entry point to our functionality. Everything that Netdata does is designed to be integrated with other tools, which helps IT departments to leverage it fully. The web API has become essential to our users, and by testing it thoroughly, we get the best return on our effort.
The first step was to fuzz-test the current API. We needed a fuzzing tool that can be called from the command-line that generates URLs / expected responses from our latest Swagger definition. We identified a Python fuzzer that could work with our Swagger definition. We modified the fuzzer to make the generated URLs more relevant to our API.
This moves beyond using Swagger as a tool to document our API for humans to read, and starts building a model of our API that is detailed enough to verify automatically.
What’s all this fuzziness and swagger about? Certainly not warm sweaters and arrogant engineers. Swagger is software for documenting developer application programming interfaces (APIs). And fuzzing is the process of feeding a program invalid or unexpected data to see how it responds.We then analysed what happens in the current code when we fuzz the API, and compared it to a Netdata streaming configuration, to check for any relevant differences. We set up a test configuration to try out the fuzzer.
- Set up a test configuration with multiple nodes streaming to a common master.
- Fuzzed the API and extract the headers from our URL processing function.
- Used the streaming configuration and extracted the headers for STREAM requests from the same function.
- Connected with different browsers and checked for relevant differences in the headers.
- Verified that the set of URLs that we see in the headers for processing is covered by the set we are fuzzing.
- Wrote PoC unit test for the http header request processing.
- Extended the testdriver to generate partial requests.
- Verified that the processing handles partial reception of requests correctly.
- Ensured that the information required for further processing is correctly extracted:
url,method,cookie1,cookie2,originanduser_agent. - Checked compliance with RFC2616 and RFC7230 (including the notes on implementation).
- Checked correct decoding of escaped characters within URLs.
- Took a dataset of exploit URLs with weird escaping and null-behaviour and put the generic patterns that cover them into the unit tests.
- Ensured correct decoding of the URL for path components, and that the mocked dispatch point for the API is called correctly.

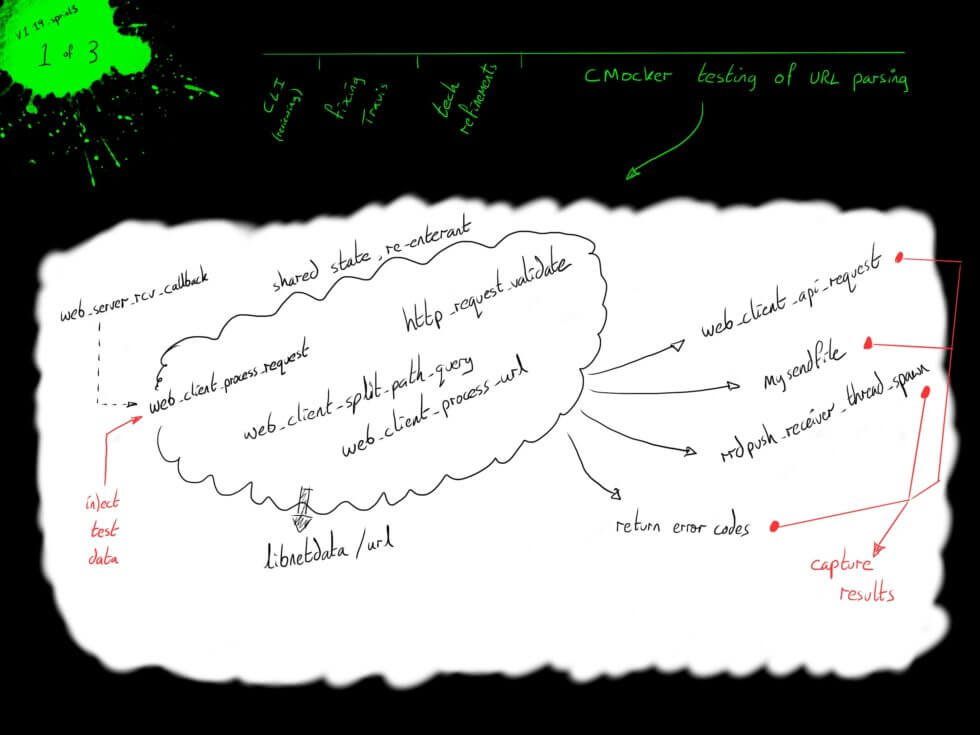
The testing process was extended by introducing a layer of parametric testing on top of the cmocka test runner. The parametric testing walks through a space of parameter values and dynamically generates test definitions for each point. A cmocka testing group was built that repeatedly calls the same testing procedure, feeding the test definitions to the procedure as a shared state.
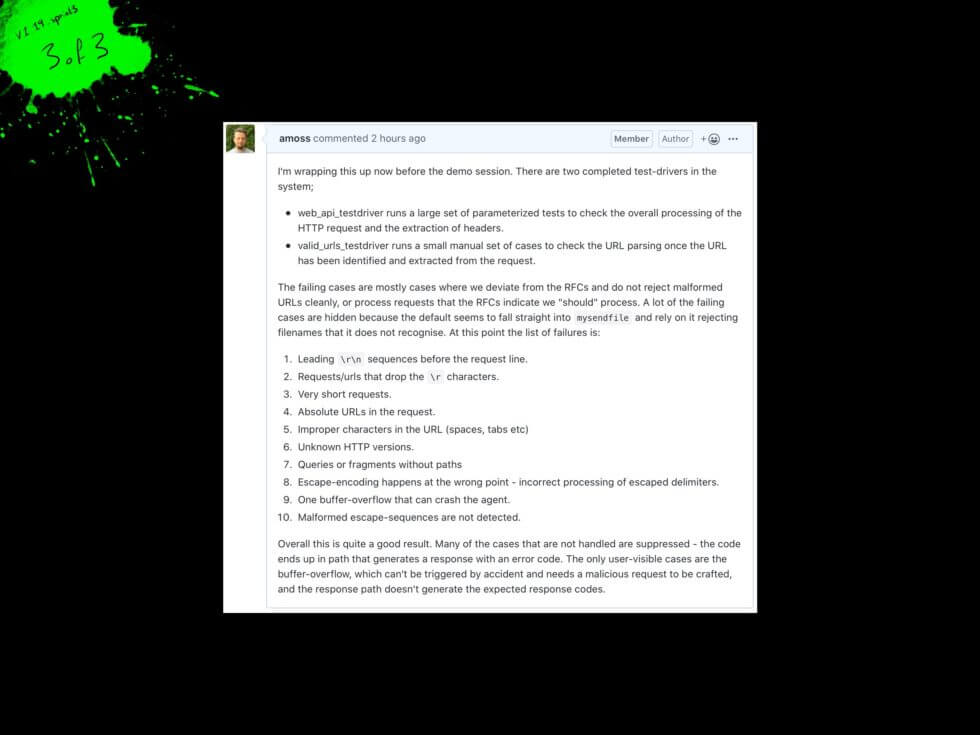
Our web_api_testdriver runs a large set of parameterized tests to check the overall processing of the HTTP request and the extraction of headers. The parameters control the headers in the request, the placement of r characters and the reception of partial prefixes of the message into the re-entrant code.
The valid_urls_testdriver runs a small manual set of cases to check the URL parsing, once the URL has been identified and extracted from the request. The interactions between decoding of characters in the URL and splitting the URL into its component parts are verified within the test suite.
Currently, the tests can be executed manually with make check, but after refining the web server’s behavior, we may execute the test suites automatically.
Tests, mocks, and URLs… oh my
To get all the benefits of cmocka’s library and be able to test our code with any agility, we needed to write a new layer on top of an existing FOSS project.Our new layer takes a single parametric test and walks through the thousands of possible combinations of testing parameters to build unit tests dynamically. These tests are fed into cmocka, and the result lets us build the robust and comprehensive testing that we want on top of industry-standard, high-quality external libraries.
That victory—getting all of cmocka’s value in a way that works best for our code—demonstrates the real strength of open-source development.
We build on the work of others and share our achievements, with the hope that others can continue to build on our results.
Despite all the hard work we’ve put in so far for our v1.19.0 release, there is a lot more to be done. If you’d like to follow along on our progress introducing cmocka unit testing, you can subscribe to our issue for rewriting the URL parser!