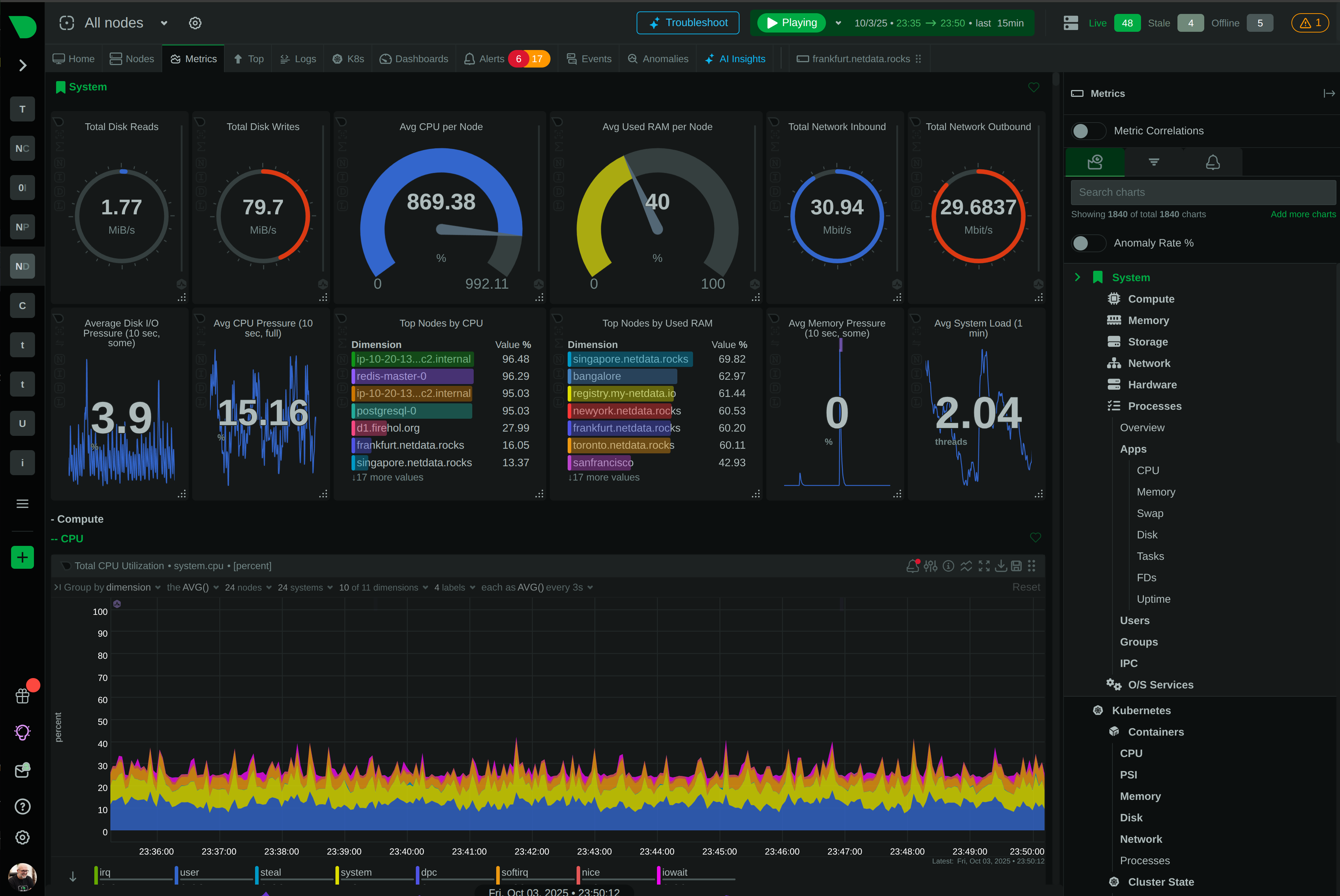
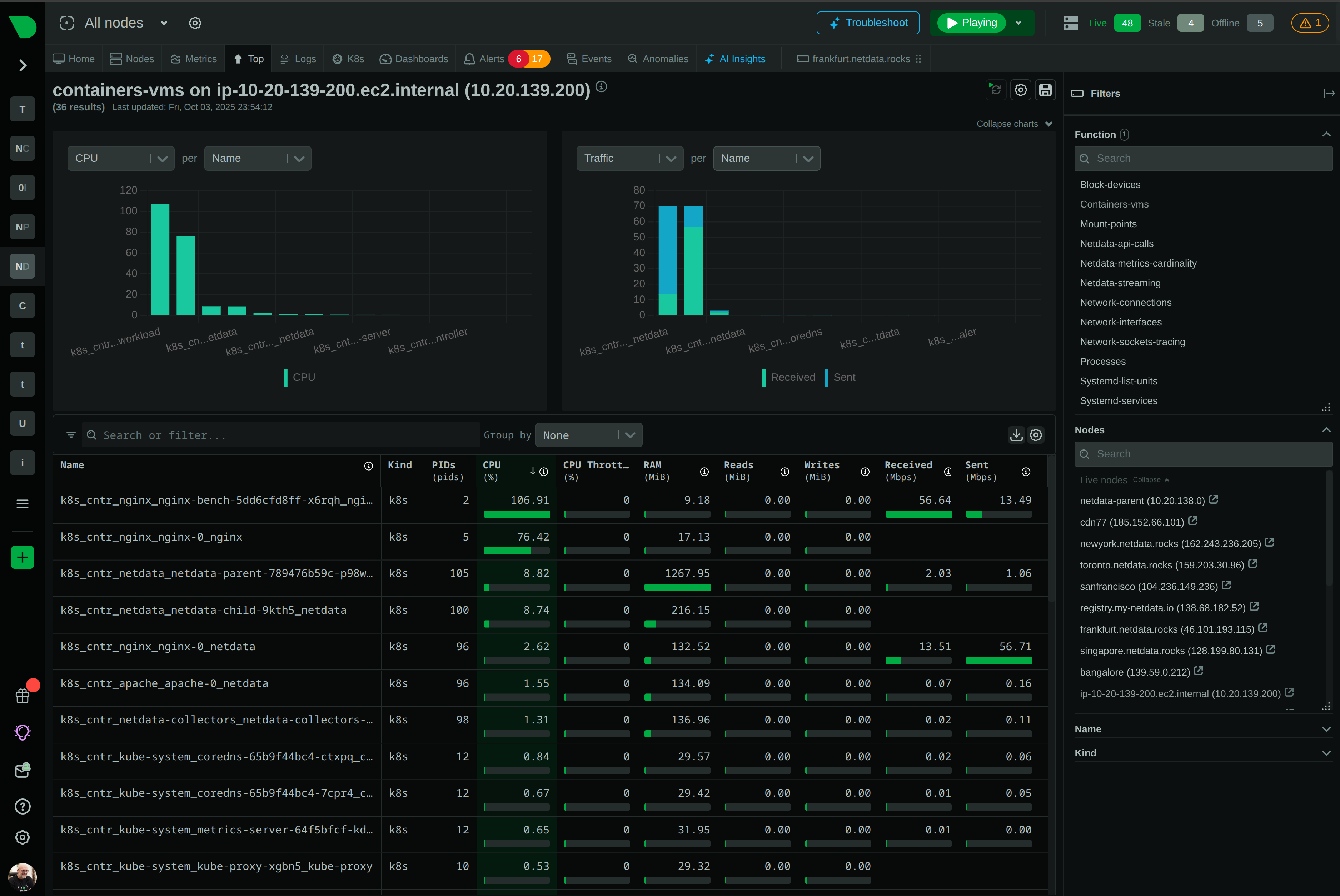
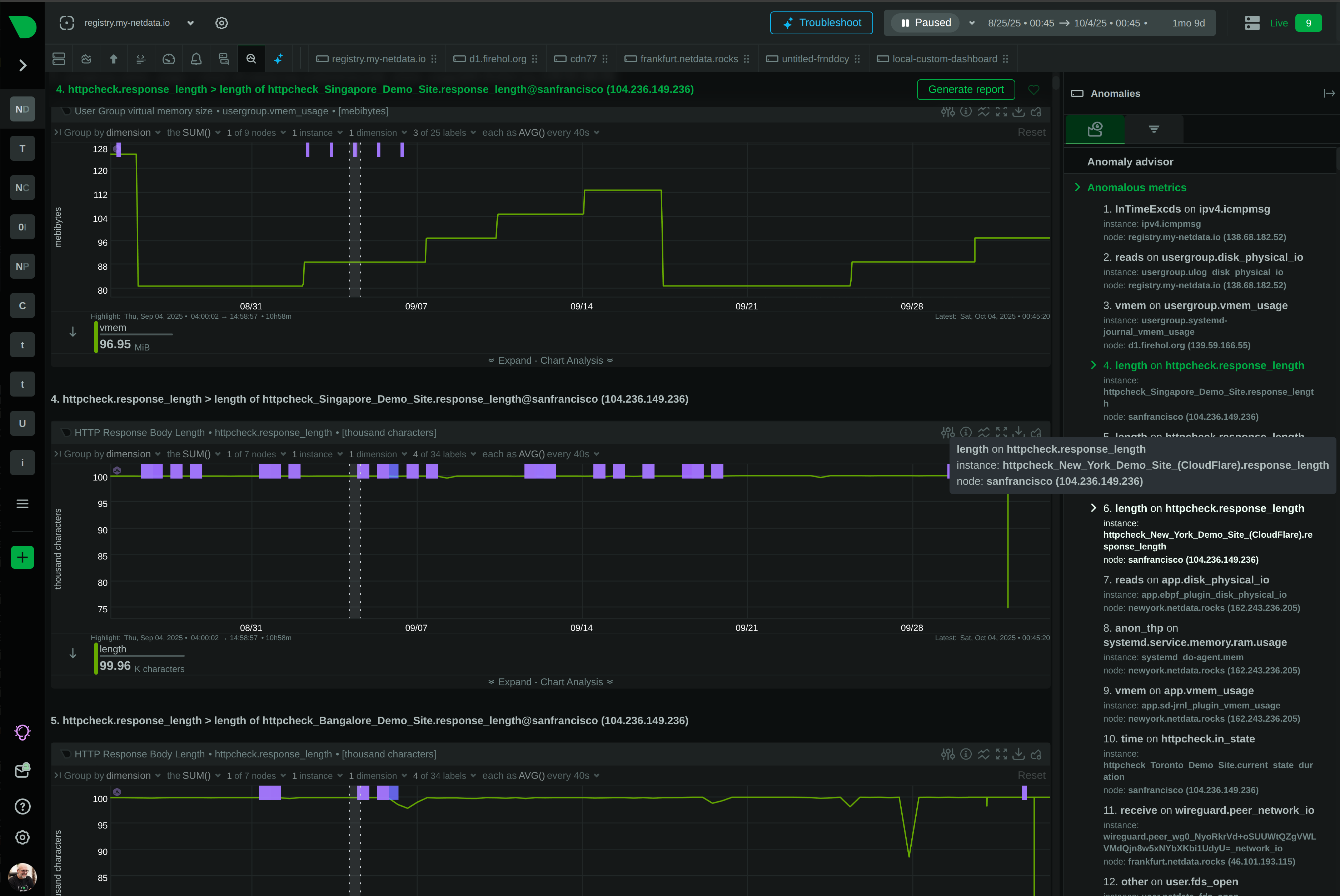
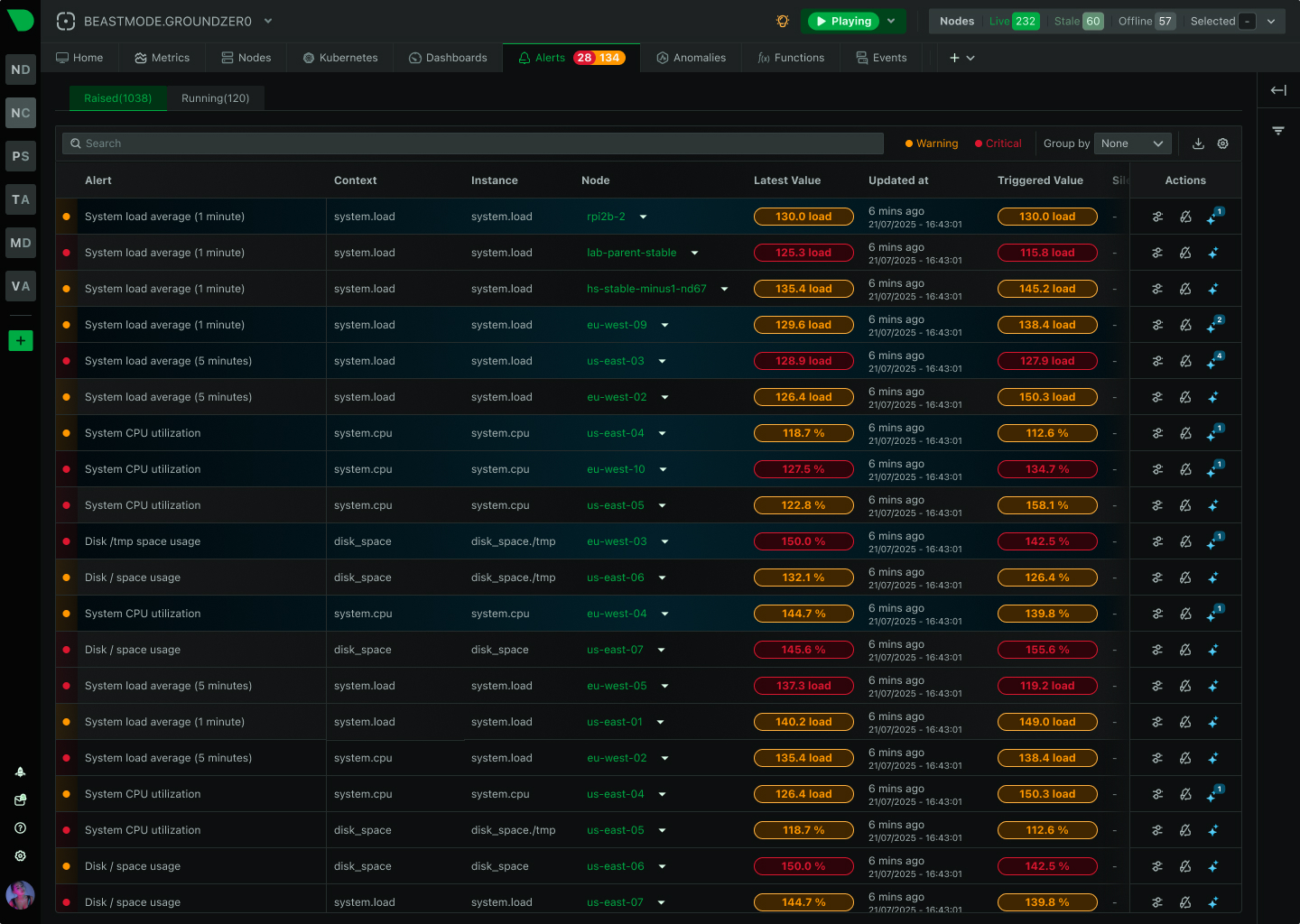
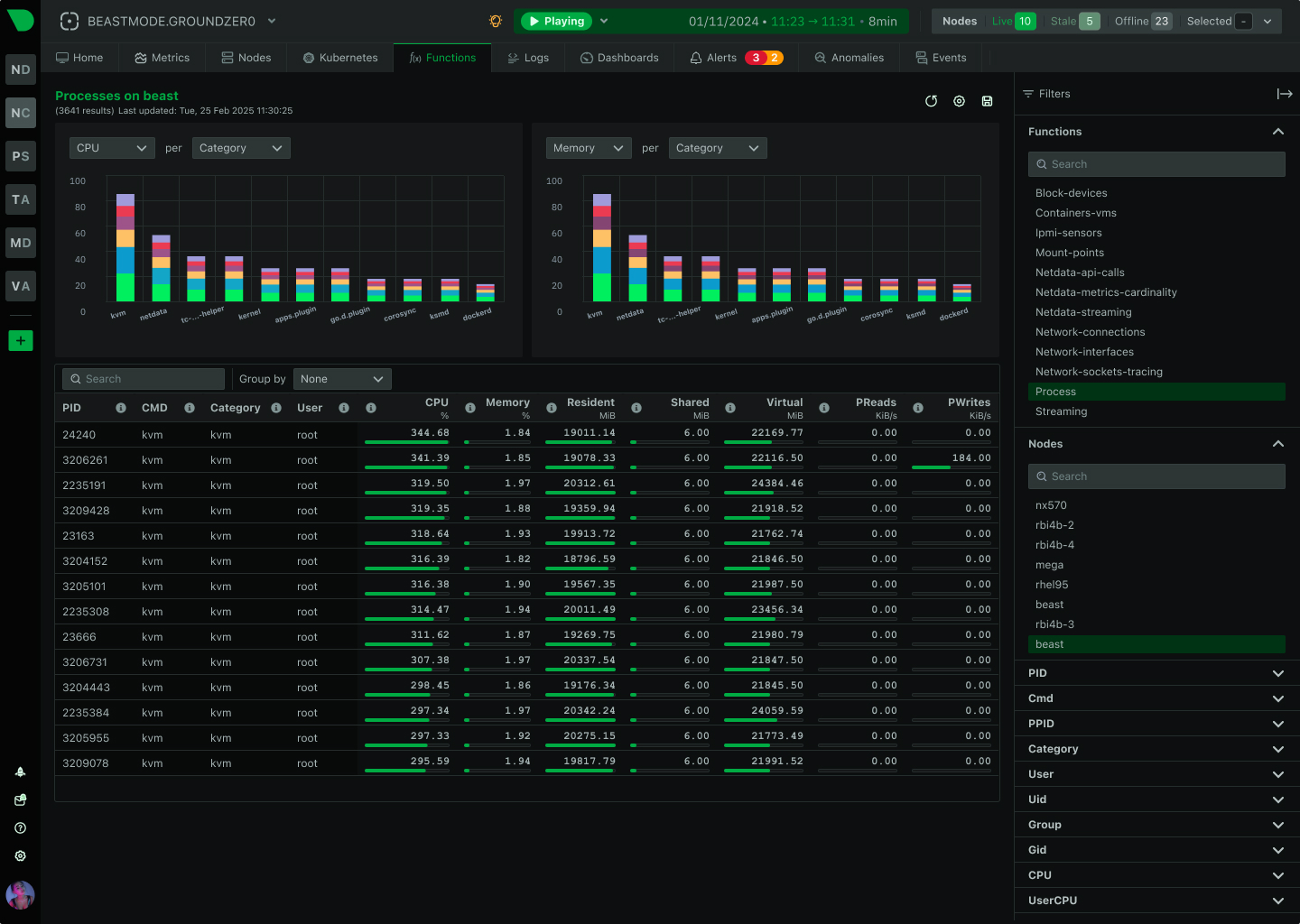
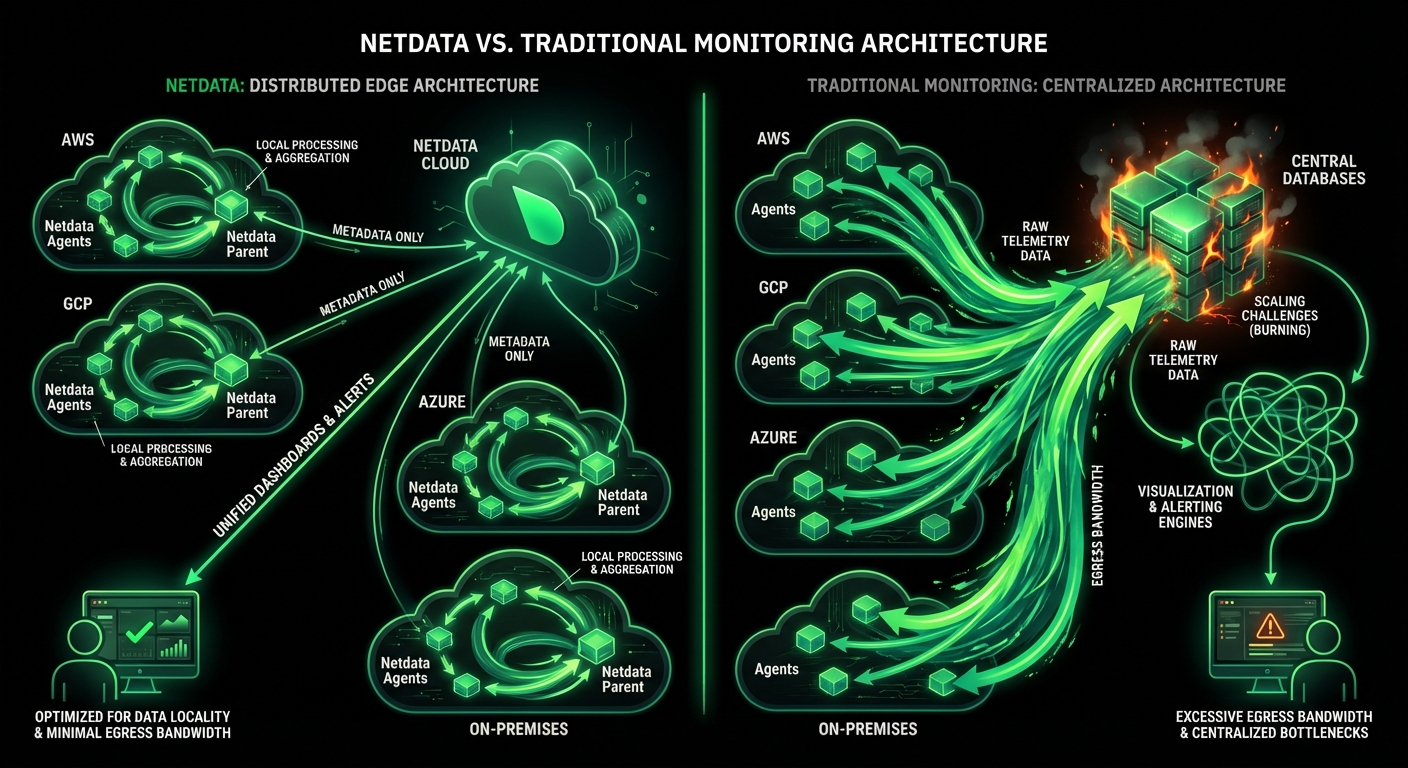
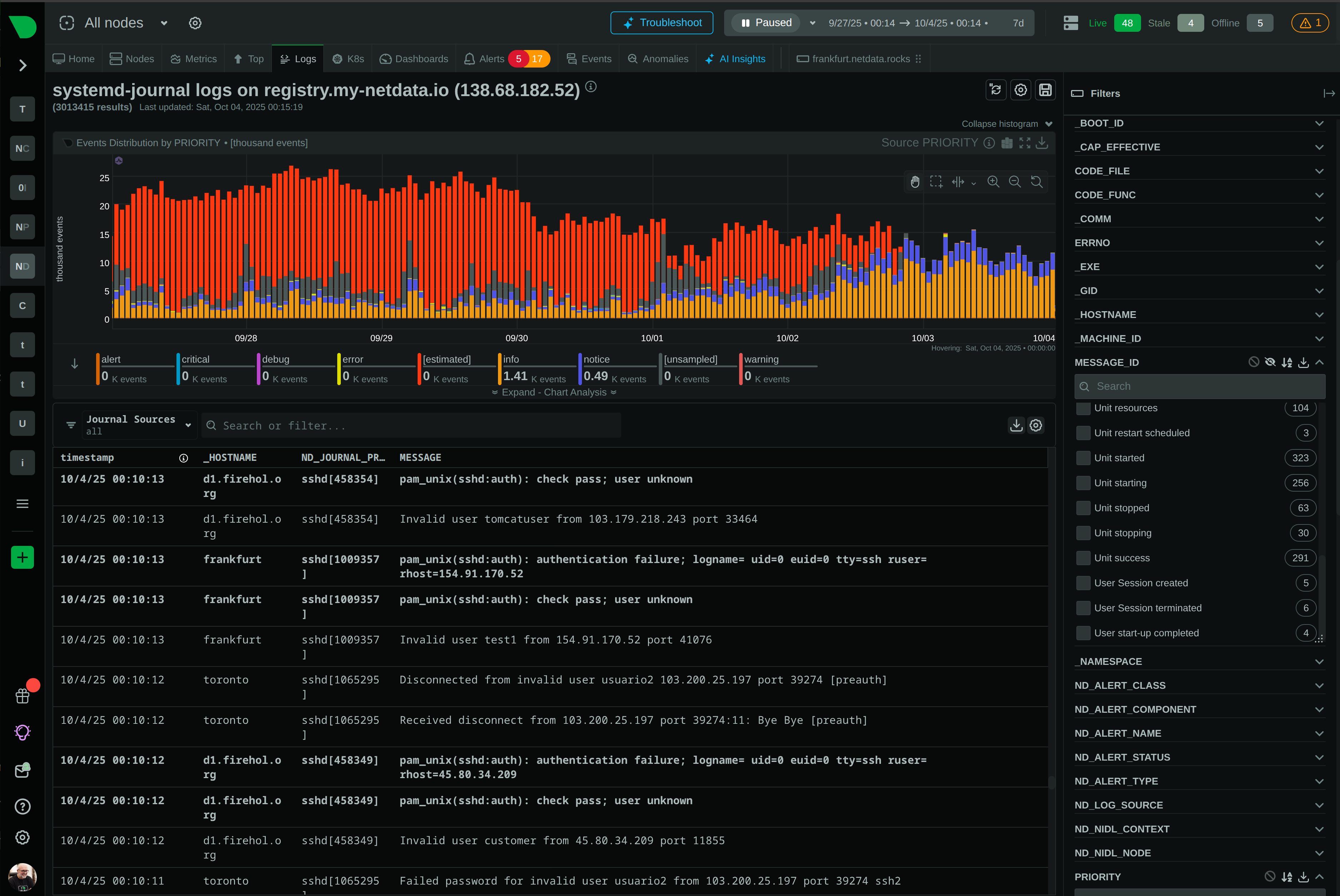
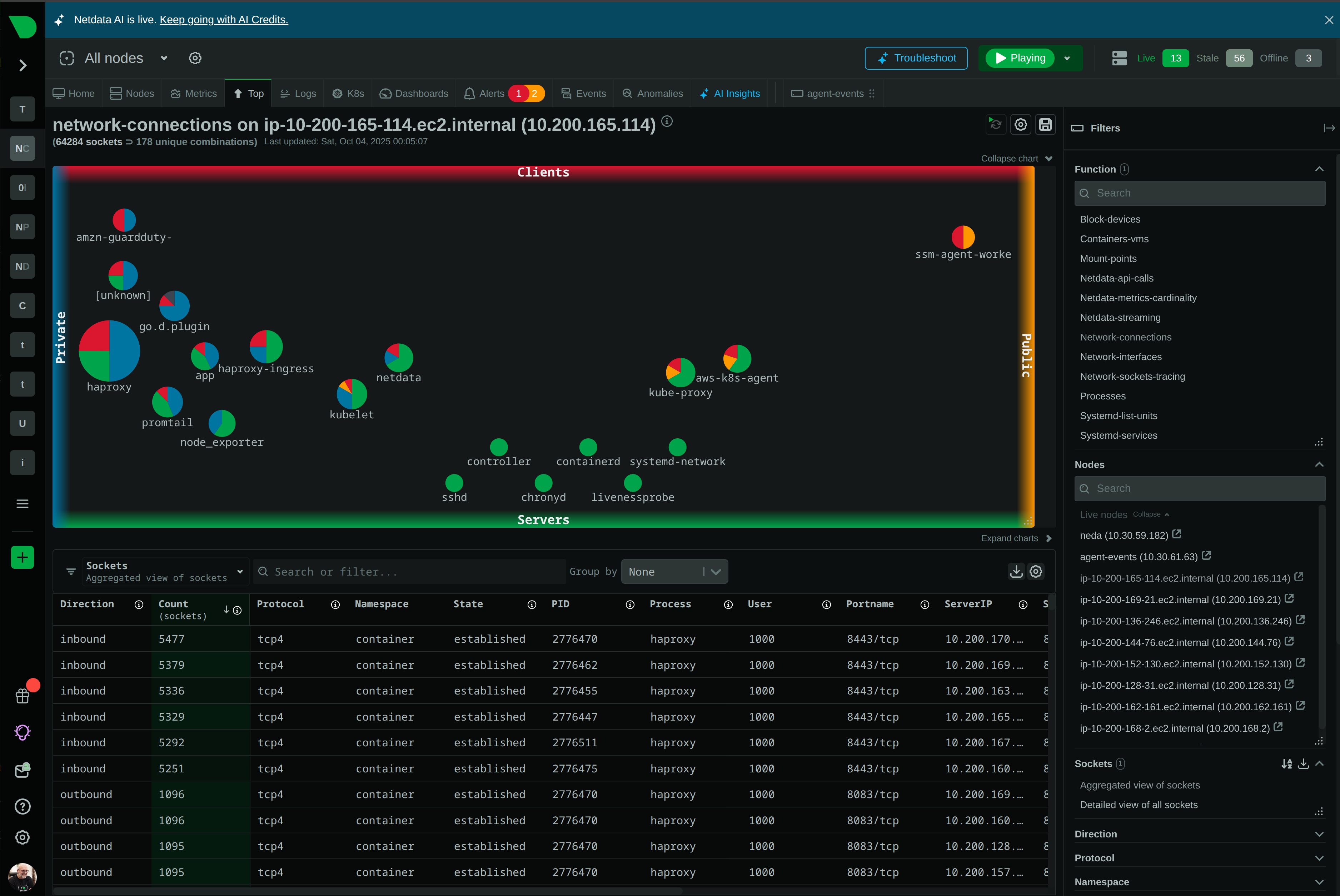
See Every Container, Every Second, Without the Chaos
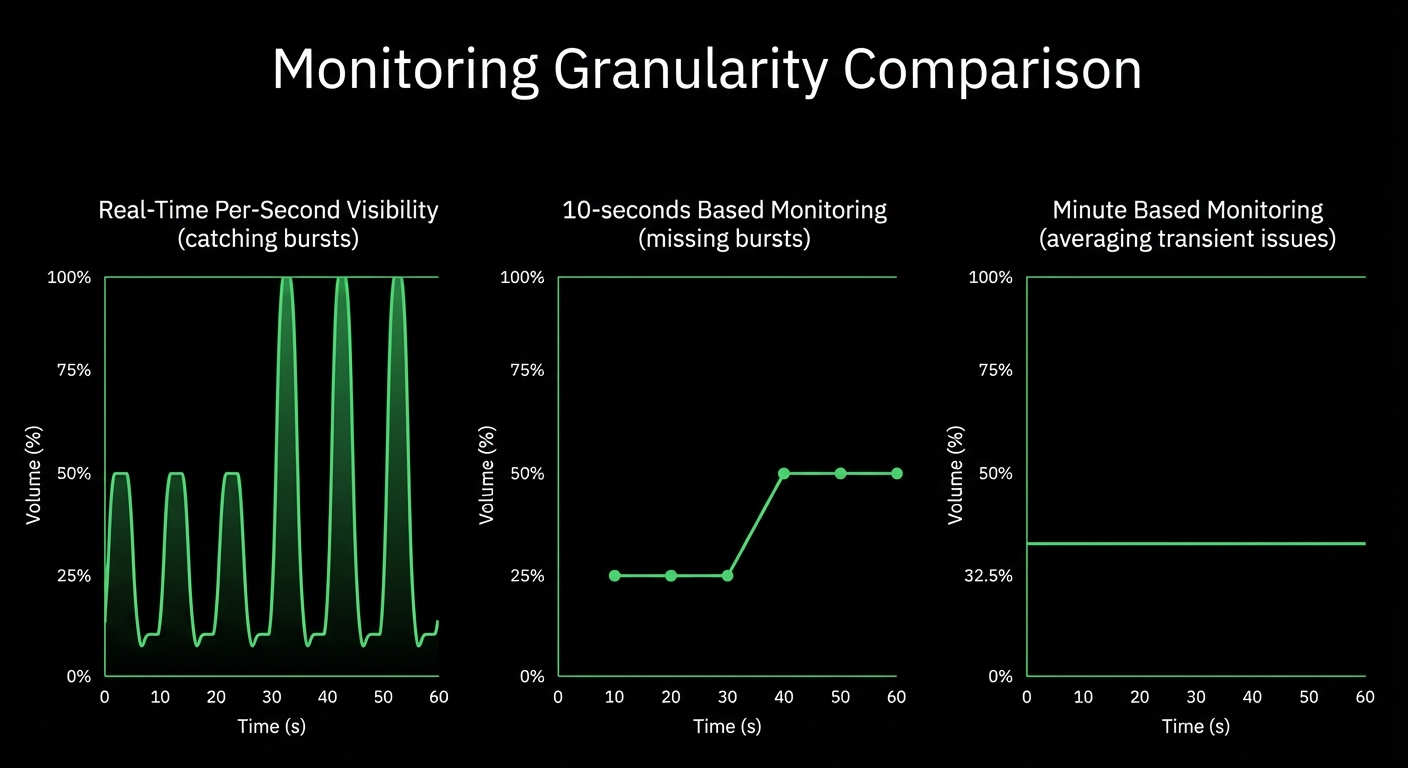
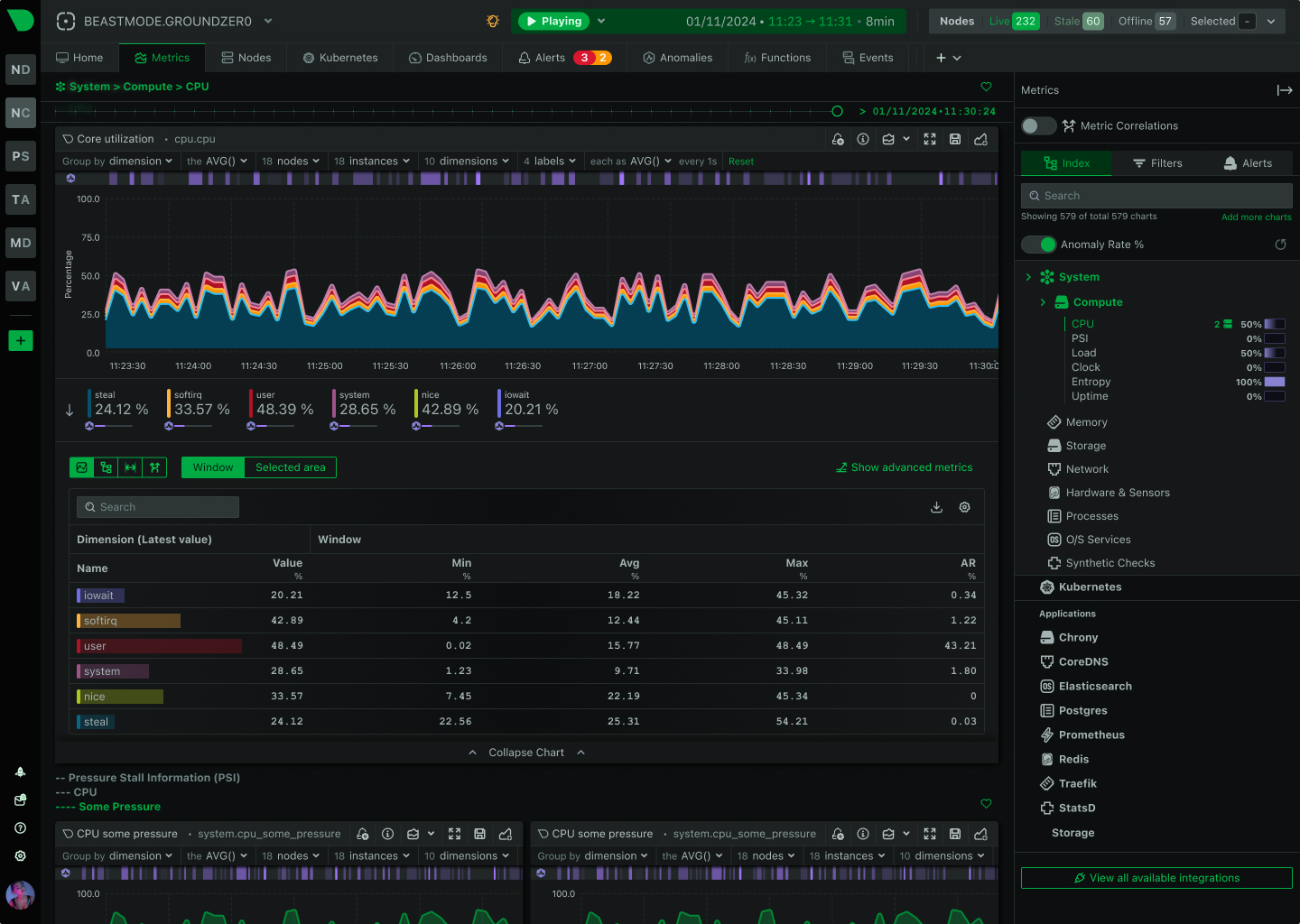
Traditional container monitoring drowns teams in complexity and costs. Netdata delivers per-second visibility across unlimited containers with zero configuration, ML-powered insights, and predictable pricing - transforming how lean teams monitor dynamic infrastructure.