
Health monitoring and performance troubleshooting aren’t easy. That’s exactly why we’re building Netdata, to democratize monitoring and make it accessible to anyone interested in learning more about their systems and applications.
Of course, teaching a complicated topic isn’t easy either.
Until recently, the only resource to help new users after installation has been our getting started guide. While that’s useful for those who have monitoring experience and a background in Linux administration, it jumps wildly over the heads of many Netdata users.
To fill that knowledge gap, we recently released an extensive step-by-step tutorial for Netdata, which guides you through everything you need to know about the best single node monitoring solution out there.
If you’re new to monitoring, or just new to Netdata, we wrote this tutorial for you.

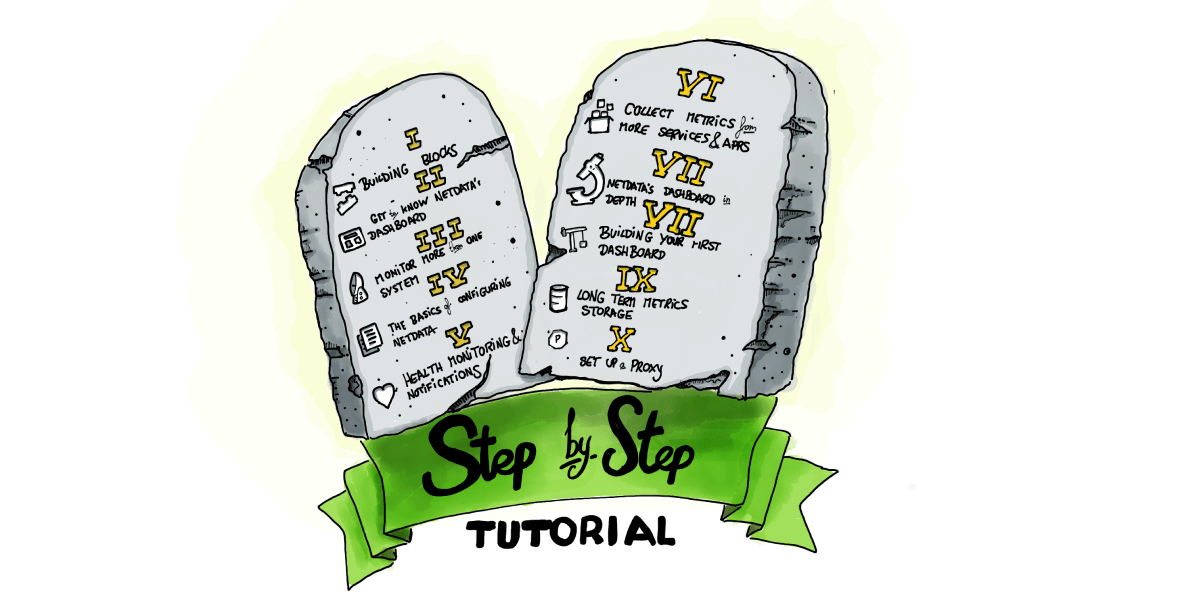
Each of the ten steps covers some fundamental component of the Netdata experience:
- Step 1. Netdata’s building blocks
- Step 2. Get to know Netdata’s dashboard
- Step 3. Monitor more than one system with Netdata
- Step 4. The basics of configuring Netdata
- Step 5. Health monitoring alarms and notifications
- Step 6. Collect metrics from more services and apps
- Step 7. Netdata’s dashboard in depth
- Step 8. Building your first custom dashboard
- Step 9. Long-term metrics storage
- Step 10. Set up a proxy
What’s next?
As with every step within the tutorial itself, this post also ends with a What’s next? section.
We’re working on comprehensive, valuable educational content directed toward the very people Costa, our CEO, addressed in his manifesto: “The people who find it hard to properly monitor their infrastructure.” Of course, we’ll always have detailed information for the experienced sysadmins, but we’re committed to teaching anyone who is interested in real-time health monitoring and performance troubleshooting.
