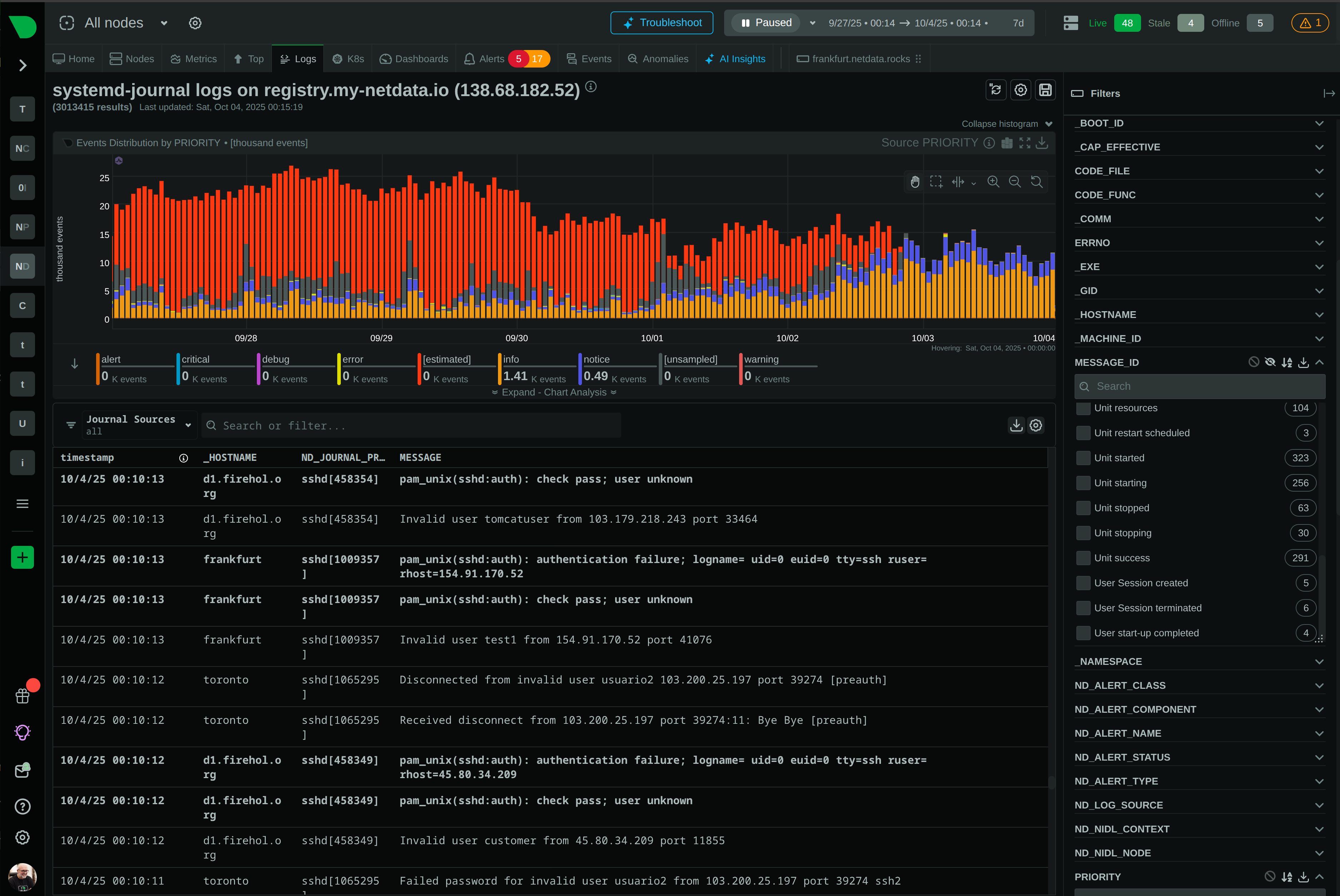
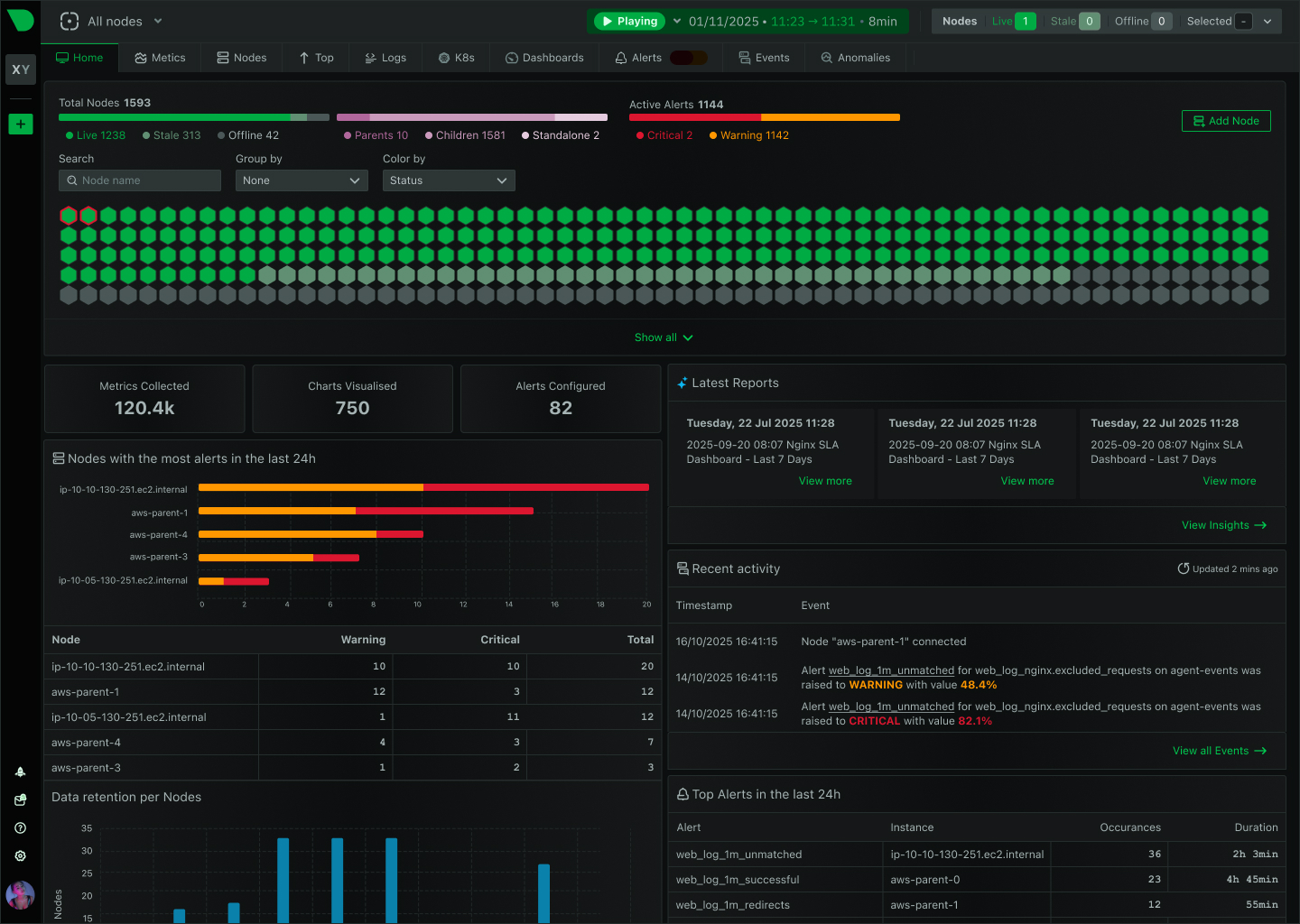
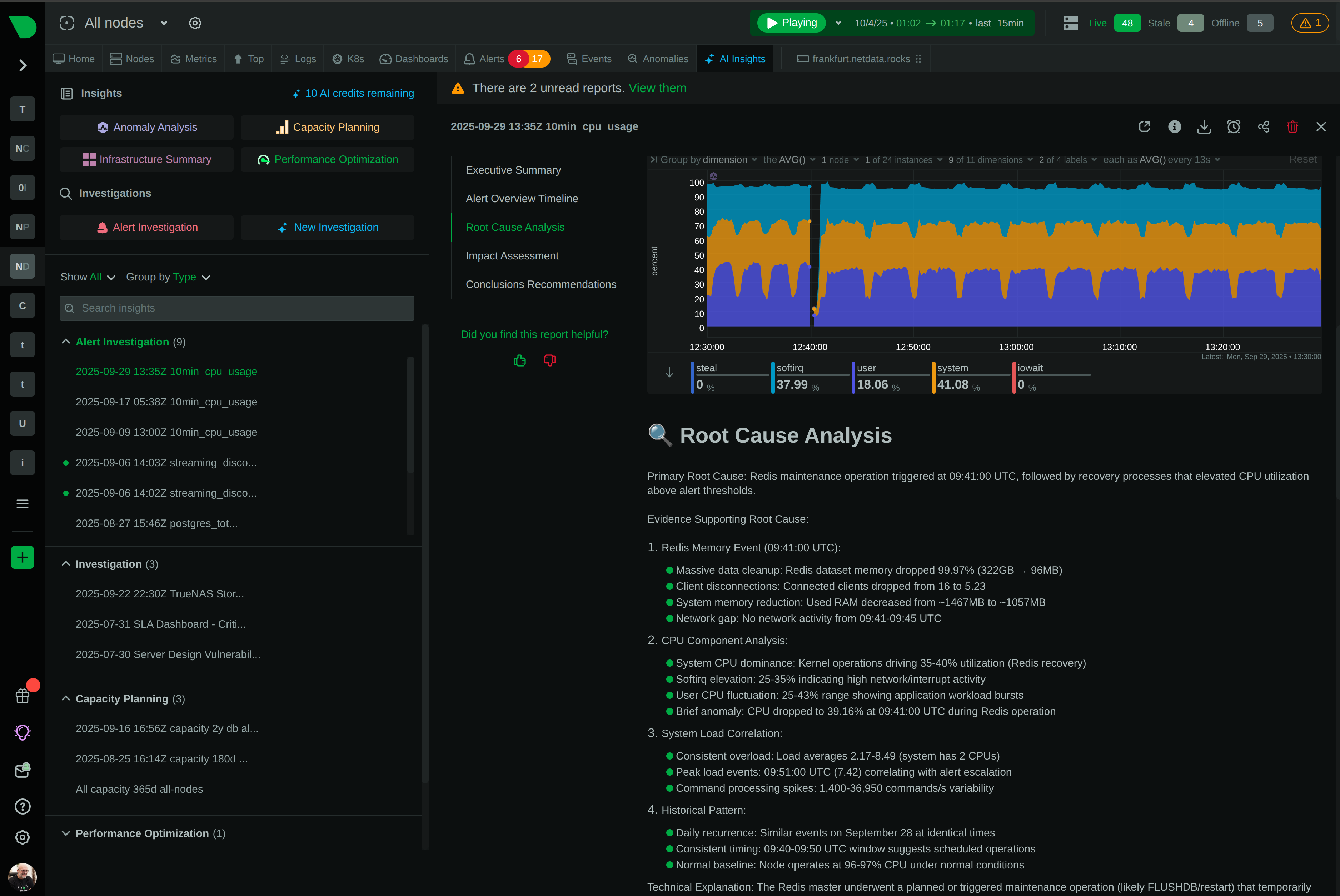
See Every Request, Catch Every Issue, Before Users Notice
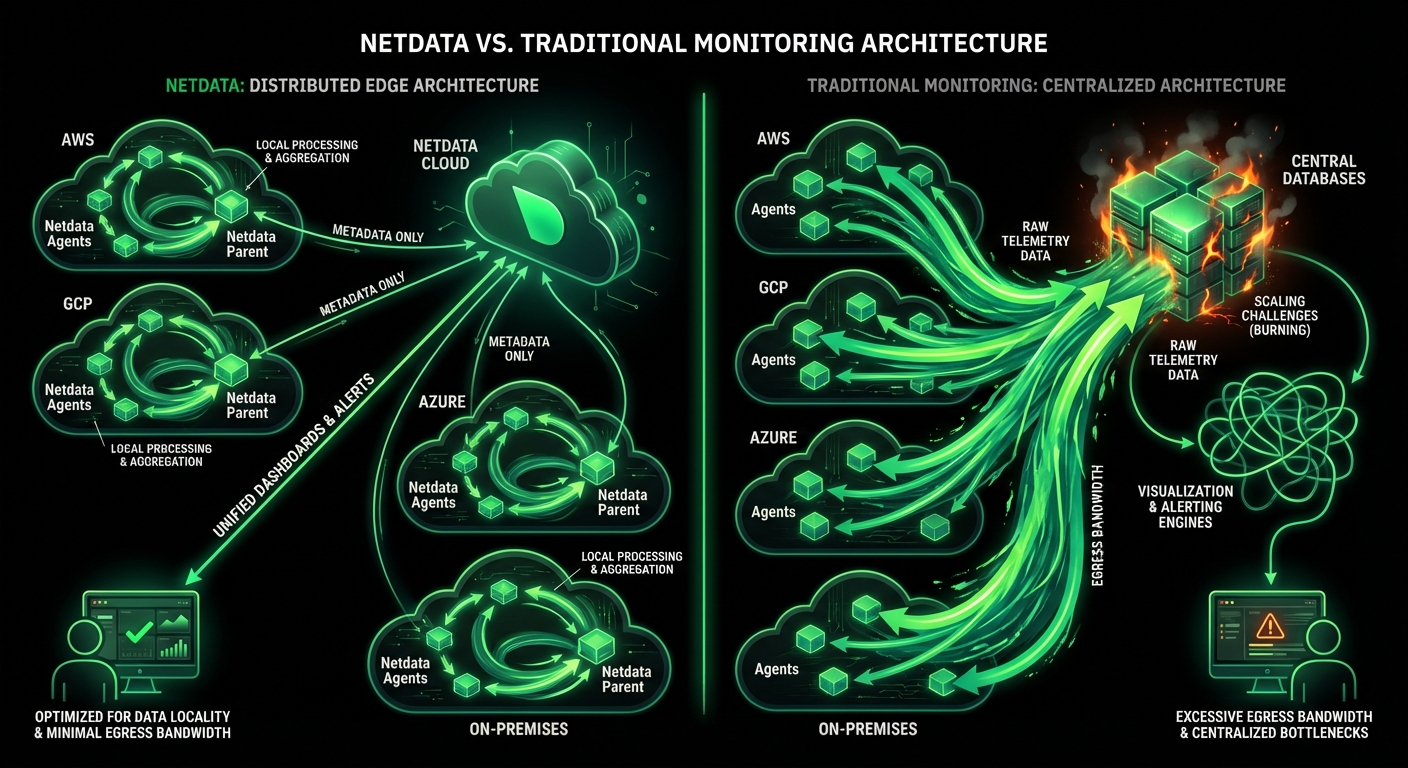
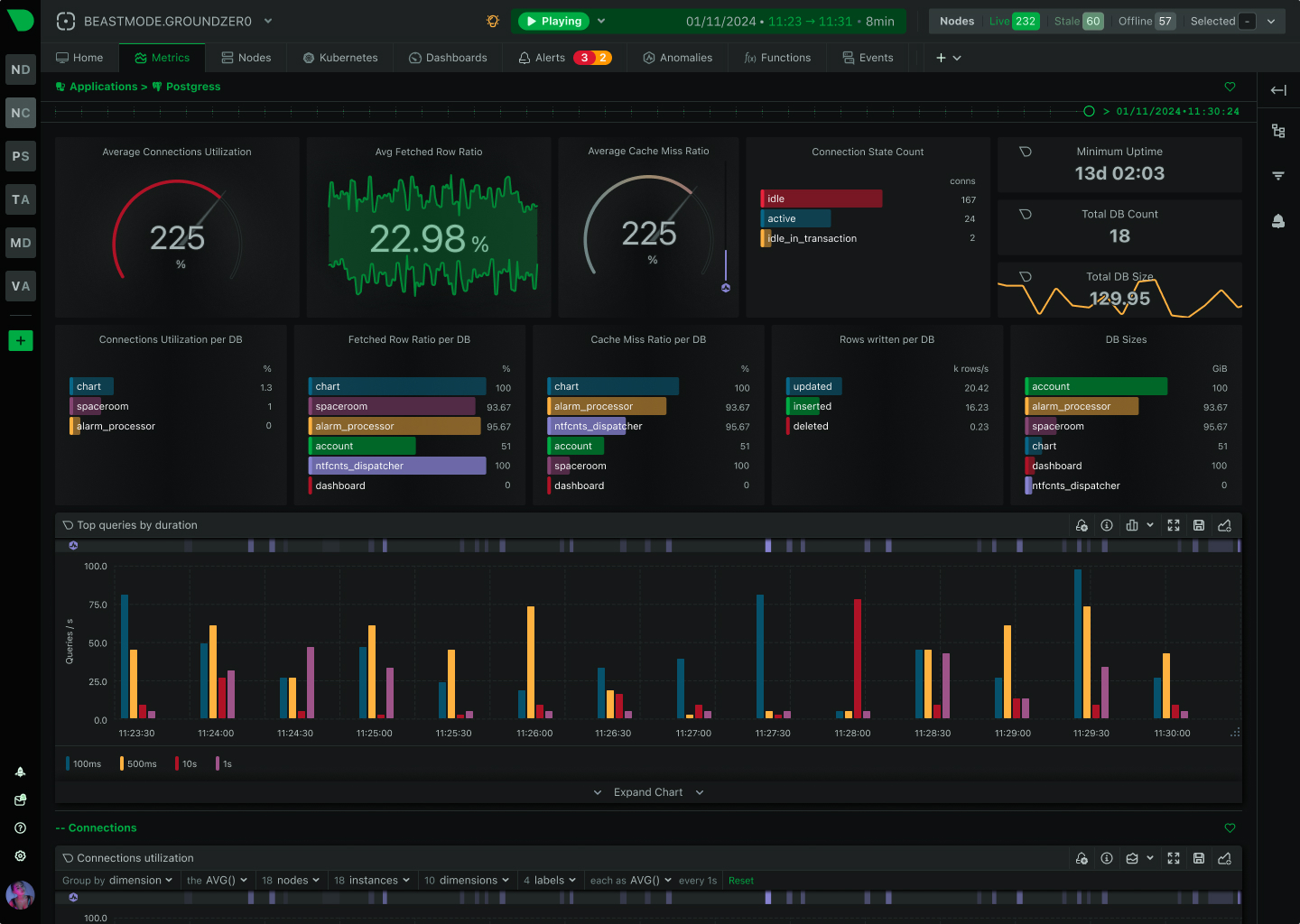
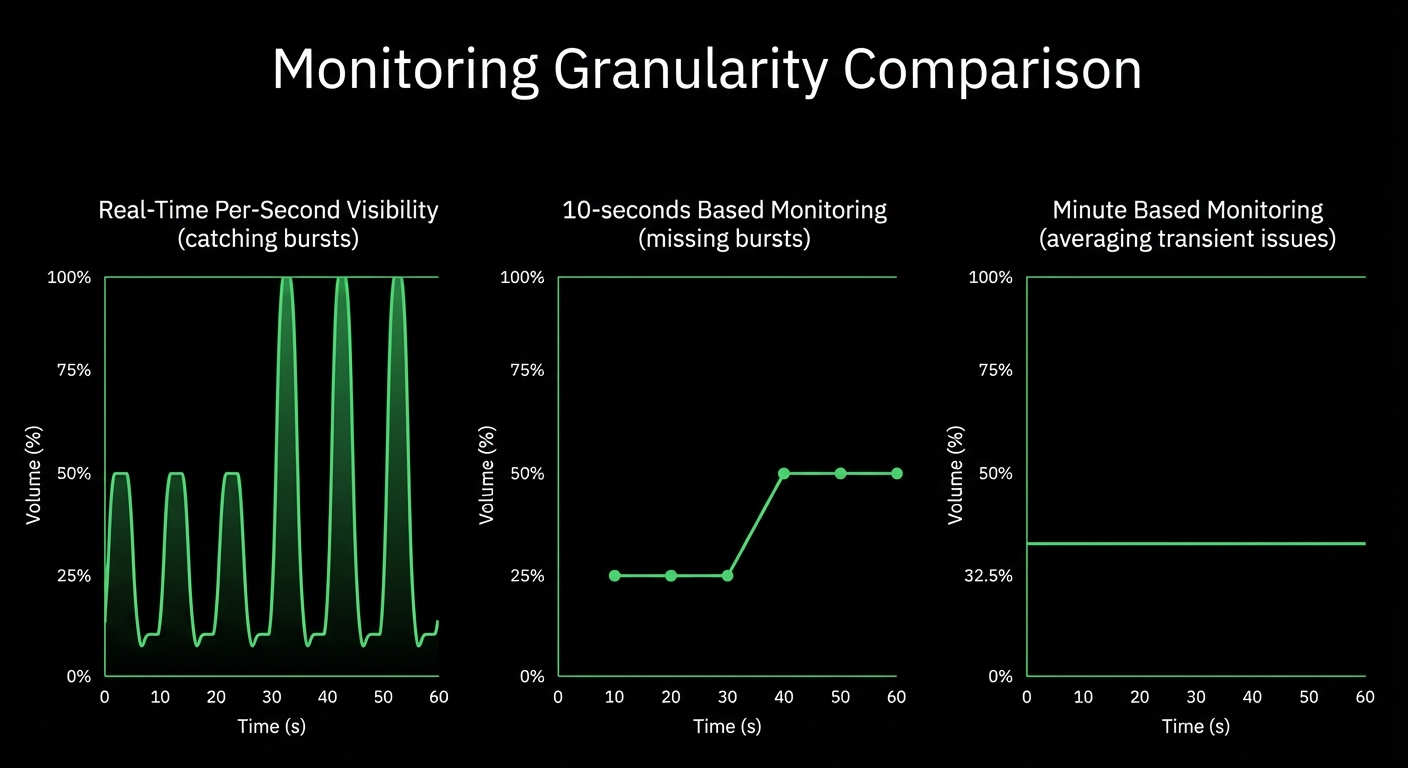
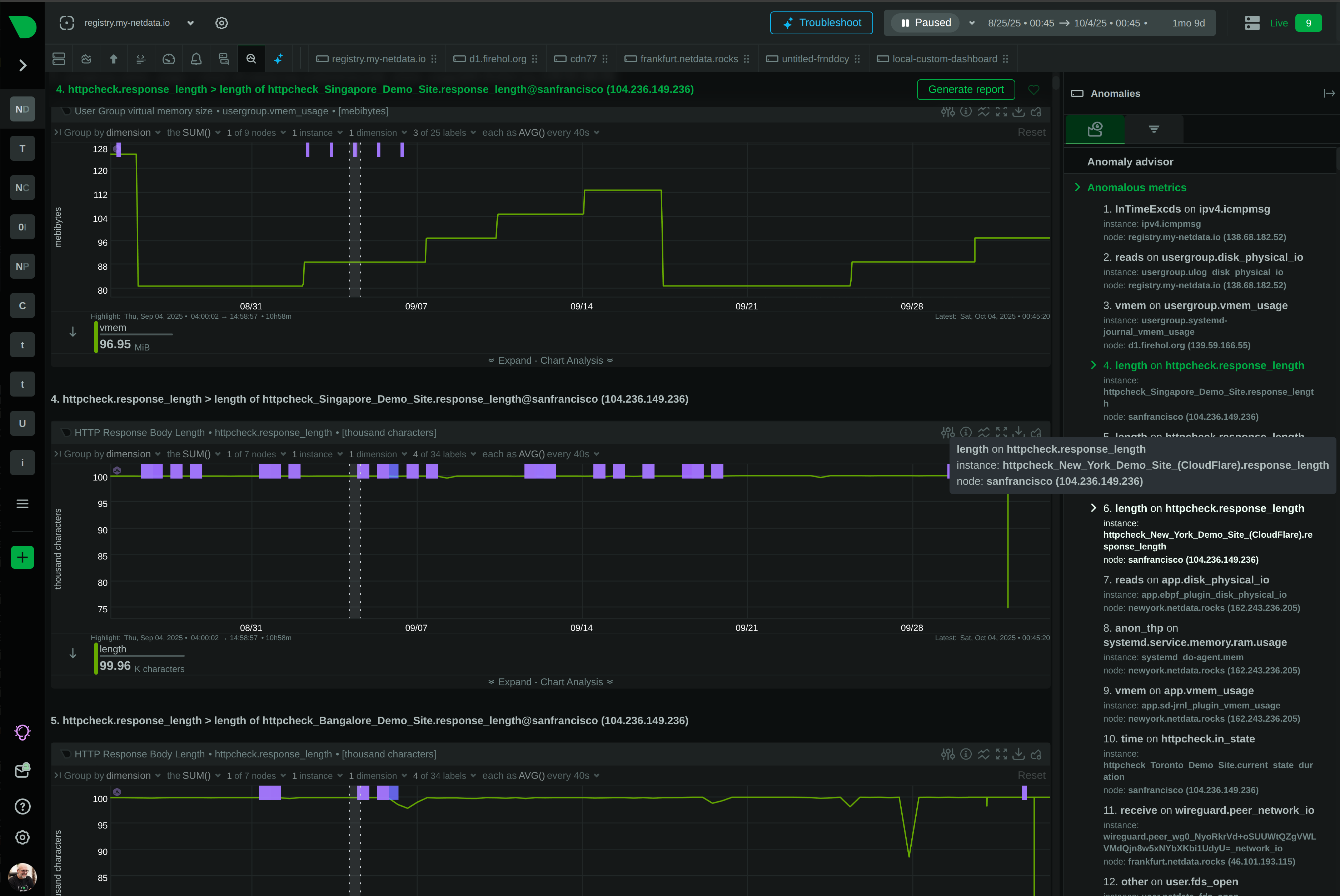
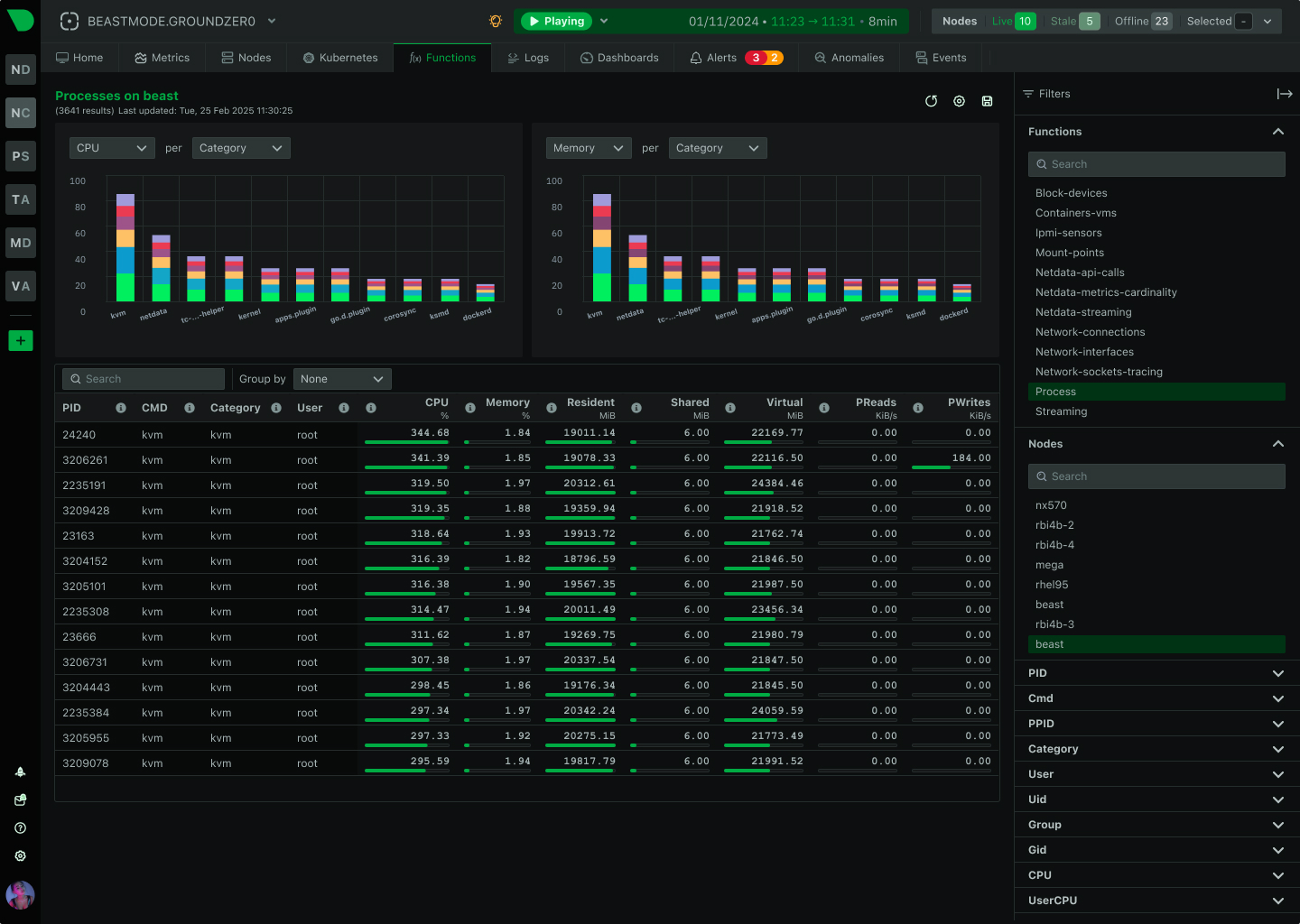
Monitor Apache, Nginx, IIS, and 800+ integrations with per-second precision. Netdata’s edge-native platform delivers complete web server visibility with ML-powered anomaly detection, automated root cause analysis, and zero-configuration deployment - all while reducing costs by 90%.